







flatMap(func)
类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)返回的有点类似于集合的概念,把list,或者array的元素都抽出来,组成一个集合。
第一步和map一样,最后将所有的输出分区合并成一个。代码测试
测试数据准备
在hdfs上放一个文件1.txt

打开spark-shell
spark-shell --master spark://master:7077(重要的事情说多遍,spark-shell和spark-submit核心的参数是差不多的)创建RDD
var data = sc.textFile("/qgzang/1.txt")
测试flatMap
使用flatMap算子
var flatMapResult = data.flatMap(line => line.split("\\s+"))
运算flatMap算子结果
flatMapResult.collect()
使用注意事项
flatMap会将字符串看成是一个字符数组。
scala> data.map(_.toUpperCase).collect
res32: Array[String] = Array(HELLO WORLD, HELLO SPARK, HELLO HIVE, HI SPARK)
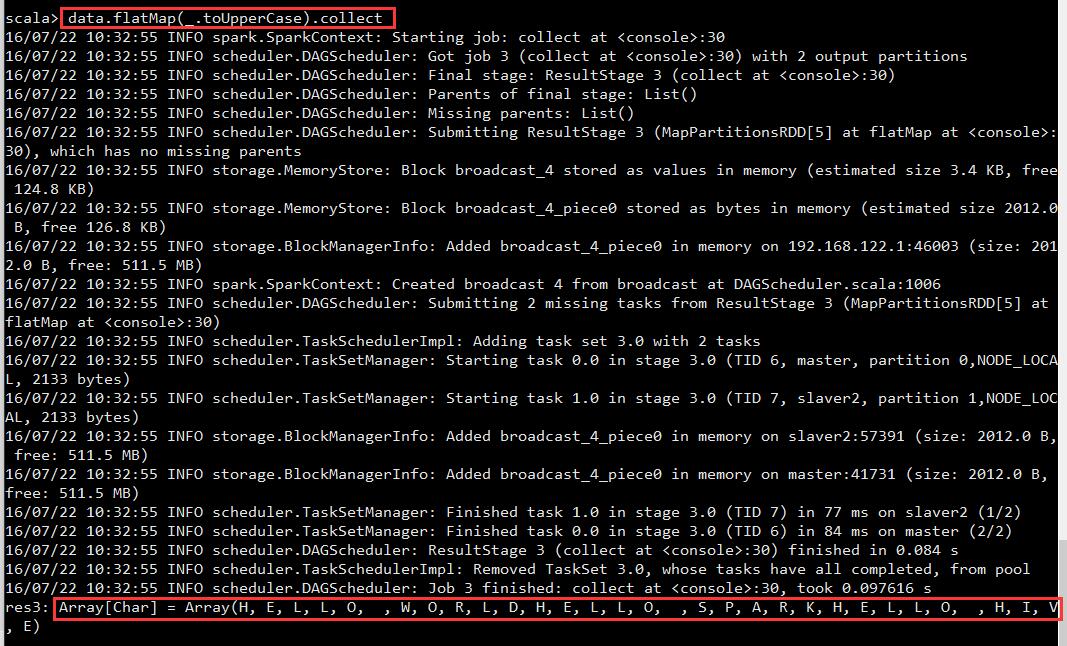
scala> data.flatMap(_.toUpperCase).collect
res33: Array[Char] = Array(H, E, L, L, O, , W, O, R, L, D, H, E, L, L, O, , S, P, A, R, K, H, E, L, L, O, , H, I, V, E, H, I, , S, P, A, R, K)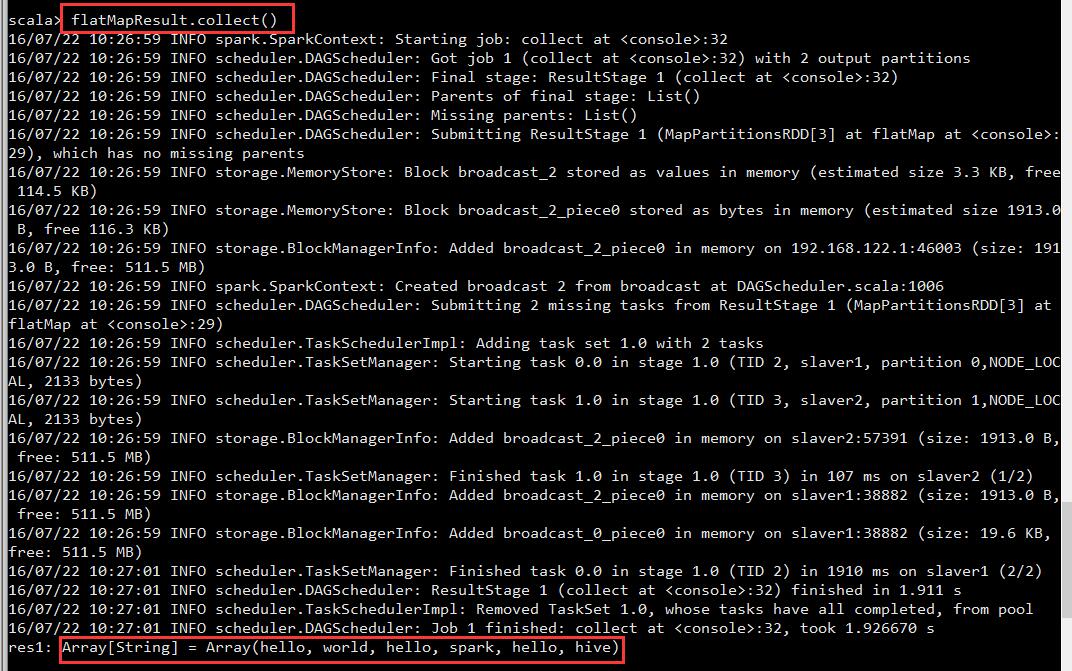
原理图
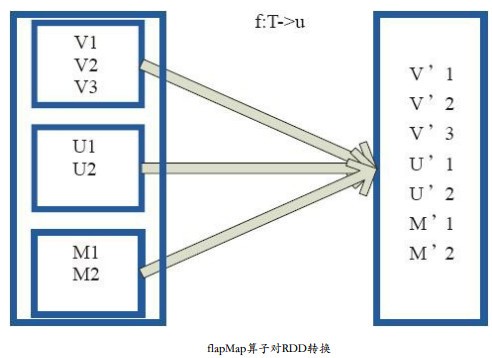
将原来RDD中的每个元素通过函数 f 转换为新的元素,并将生成的RDD的每个集合中的元素合并为一个集合。 内部创建FlatMappedRDD(this,sc.clean(f))。
图中,小方框表示RDD的一个分区,对分区进行flatMap函数操作,flatMap中传入的函数为 f : T->U,T和U可以是任意的数据类型。将分区中的数据通过用户自定义函数f转换为新的数据。外部大方框可以认为是一个RDD分区,小方框代表一个集合。 V1、 V2、 V3在一个集合作为RDD的一个数据项,转换为V’1、 V’2、 V’3后,将结合拆散,形成为RDD中的数据项。
源码
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}














 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









