







基本思想
Sunday算法由Daniel M.Sunday在1990年提出,它的思想跟BM算法很相似。
只不过Sunday算法是从前往后匹配,在匹配失败时关注的是主串中参加匹配的最末位字符的下一位字符。
- 如果该字符没有在模式串中出现则直接跳过,即移动位数 = 模式串长度 + 1;
- 否则,其移动位数 = 模式串长度 - 该字符最右出现的位置(以0开始) = 模式串中该字符最右出现的位置到尾部的距离 + 1。实例
下面举个例子说明下Sunday算法。假定现在要在主串”substring searching”中查找模式串”search”。
刚开始时,把模式串与文主串左边对齐:
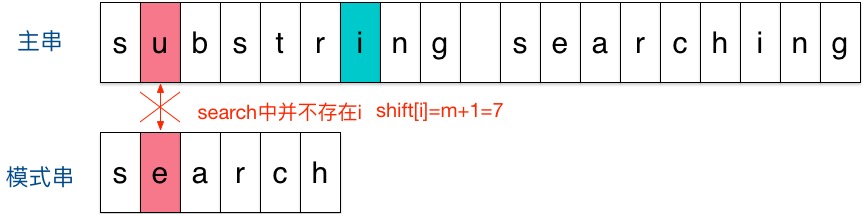
结果发现在第2个字符处发现不匹配,不匹配时关注主串中参加匹配的最末位字符的下一位字符,即标粗的字符 i,因为模式串search中并不存在i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符n)开始下一步的匹配,如下图:
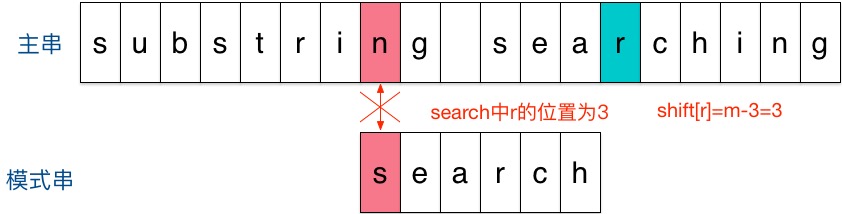
结果第一个字符就不匹配,再看主串中参加匹配的最末位字符的下一位字符,是‘r’,它出现在模式串中的倒数第3位,于是把模式串向右移动3位(m - 3 = 6 - 3 = r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个‘r’对齐,如下:
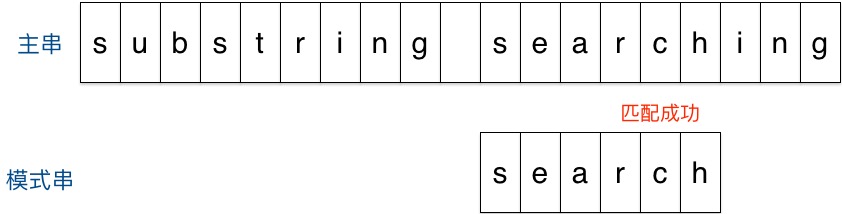
匹配成功。
回顾整个过程,我们只移动了两次模式串就找到了匹配位置,缘于Sunday算法每一步的移动量都比较大,效率很高。
偏移表
偏移表
在预处理中,计算大小为∣∑∣的偏移表。
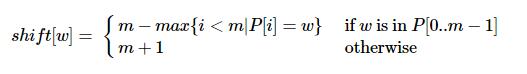
代码实现
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 28 23:11:27 2016
@author: zang
"""
import re
def Sunday(text, pattern):
results = [] # 匹配结果
flag = 0
len_pattern = len(pattern)
len_text = len(text)
endIndex = len_text - len_pattern + 1
for i in range(0, endIndex):
for j in range(0, len_pattern):
if text[i + j] == pattern[j]:
if j == (len_pattern - 1):
flag += 1
results.append(" "*i + pattern + " "*(len_text - len_pattern - i) + " " + str(i+1) + " " + str(flag))
break
else:
t = i + len_pattern
if t >= len_text:
break
if text[t] in pattern:
array = [m.start() for m in re.finditer(text[t], pattern)]
move = len_pattern - array[len(array) - 1]
i = i + move - 1
else:
i = i + t - 1
break
if flag == 0:
print "No find."
else:
print flag," matching results are listed below."
print "-------" + "-"*t + "-------"
print text
for line in results:
print line
print "-------" + "-"*t + "-------"
def main():
while 1:
text = raw_input("text: ")
pattern = raw_input("pattern: ")
if len(text) == 0 or len(pattern) == 0:
print "\nplease input text and pattern again!"
break
Sunday(text, pattern)
if __name__ == '__main__':
main()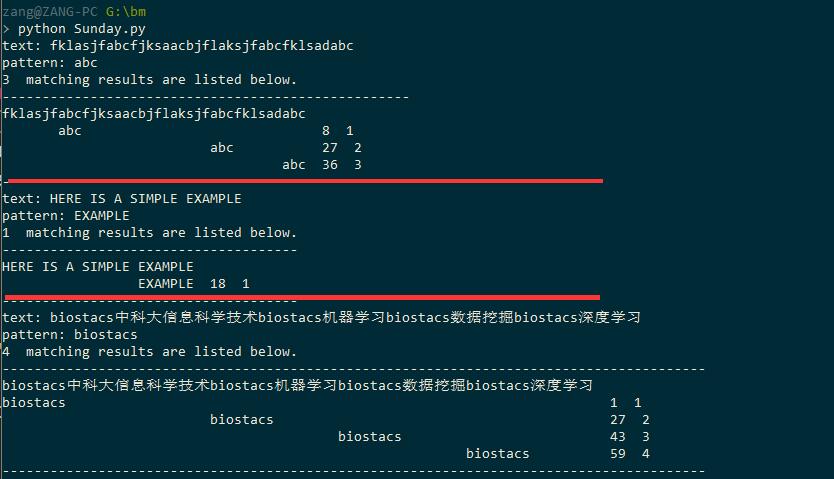















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









