







介绍
冒泡排序的原理非常简单,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
步骤
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

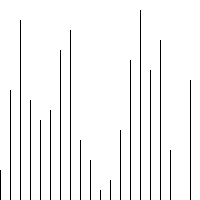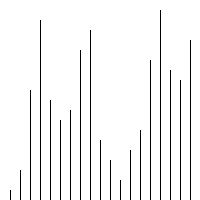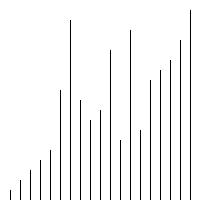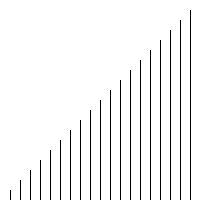
代码
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 26 16:41:35 2016
@author: zang
"""
from matplotlib import pyplot as plt
import random
def bubbleSort1(unsortedList):#采用递归
if len(unsortedList)<2:
return unsortedList
list_length=len(unsortedList)
for i in range(list_length - 1):
if unsortedList[i] > unsortedList[i + 1]:
unsortedList[i],unsortedList[i + 1] = unsortedList[i + 1], unsortedList[i]
max_num = unsortedList.pop()
return bubbleSort1(unsortedList) + [max_num]
def bubbleSort(unsortedList):
if len(unsortedList)<2:
return unsortedList
list_length=len(unsortedList)
for i in range(list_length - 1):
for j in range(list_length - i - 1):
if unsortedList[j] > unsortedList[j+1]:
unsortedList[j],unsortedList[j+1] = unsortedList[j+1],unsortedList[j]
return unsortedList
def plotScatter(inputList):
plt.scatter(range(len(inputList)),inputList)
plt.show()
if __name__ == "__main__":
num_list = range(1000)
unsortedList = random.sample(num_list, 5)
print "unsortedList:"
plotScatter(unsortedList)
print unsortedList
sortedList = bubbleSort(unsortedList)
print "sortedList:"
plotScatter(sortedList)
print sortedList
sortedList = bubbleSort1(unsortedList)
print "sortedList1:"
plotScatter(sortedList)
print sortedList测试
输入:
[729, 114, 934, 151, 917, 262, 445, 298, 261, 259, 393, 431, 441, 331, 849, 167, 247, 686, 146, 558, 173, 744, 353, 538, 425, 271, 100, 196, 67, 819]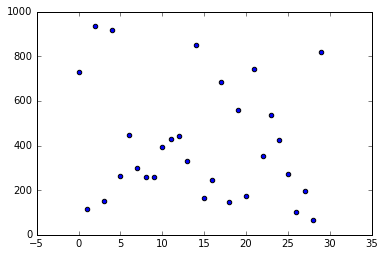
输出:
[67, 100, 114, 146, 151, 167, 173, 196, 247, 259, 261, 262, 271, 298, 331, 353, 393, 425, 431, 441, 445, 538, 558, 686, 729, 744, 819, 849, 917, 934]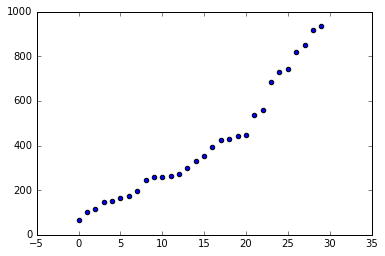
分析
| 情况 | 性能 |
|---|---|
| Worst case performance: | O(n2) |
| Best case performance: | O(n) |
| Average case performance: | O(n2) |
| Worst case space complexity: | O(1) |
优化
优化1:某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了。用一个标记记录这个状态即可。
优化2:记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序,不用再排序了。因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









