







前言
蛮久前写过一篇torchtext加载数据,不过官方不久前升级了torchtext,移除了蛮多东西。数据加载也和之前不一样了。
看官方文档,似乎更推荐用torchdata装载数据,不过本文还是先用dataset做。
由于现在网上都没什么新版本教程,一个人看文档摸索的,有错请谅解
……
数据集准备
数据集随意,选用了自己常用的数据集作为例子。基本就如图所示:
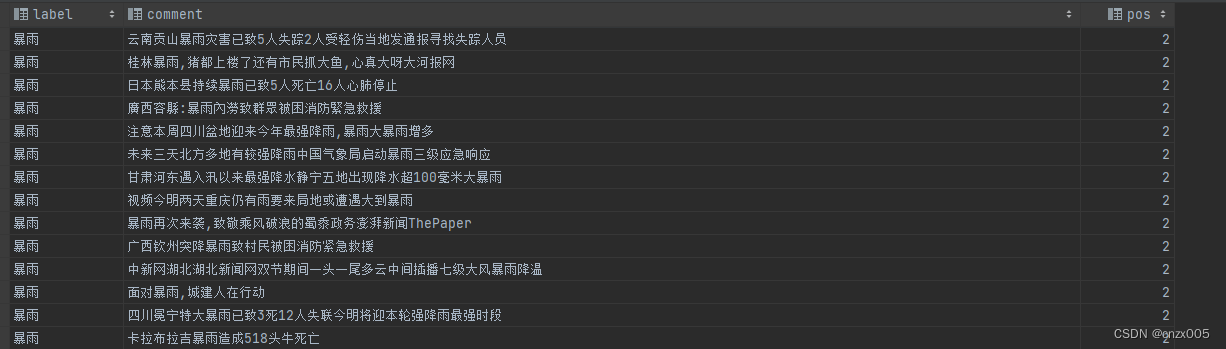
torchtext流程
新版本将之前的Field, TabularDataset,BucketIterator都删去了,流程略有不同。
词表装载
build_vocab_from_iterator 在 torchtext 中建立词表序列
主要参数如下
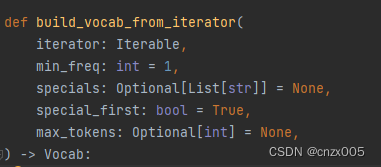
iterator 接受组成词表的迭代器
min_freq 是构成词表的最小频率
specials 是特殊词表符号
import pandas as pd
import pkuseg
from torchtext.vocab import build_vocab_from_iterator
seg = pkuseg.pkuseg()
def tokenizer(text):
return seg.cut(text)
def yield_tokens(data_iter):
for _, text in data_iter.iterrows():
yield tokenizer(text['comment'])
train_iter = pd.read_csv('./data/news_train.csv')
vocab = build_vocab_from_iterator(yield_tokens(train_iter), min_freq=5, specials=['<unk>', '<pad>'])
vocab.set_default_index(vocab["<unk>"])
dataloder
看了官方上的实例,先用dataset装载数据(我猜)
class TextCNNDataSet(Dataset):
def __init__(self, data, data_targets):
self.content = data
self.pos = data_targets
def __getitem__(self, index):
return self.content[index], self.pos[index]
def __len__(self):
return len(self.pos)
train_iter = TextCNNDataSet(list(train_iter['comment']), list(train_iter['pos']))
然后用dataloder装载dataset数据
train_loader = DataLoader(train_iter, batch_size=8, shuffle=True, collate_fn=collate_batch)
collate_batch 为自定义的处理数据函数
def collate_batch(batch):
label_list, text_list = [], []
truncate = Truncate(max_seq_len=20) # 截断
pad = PadTransform(max_length=20, pad_value=vocab['<pad>'])
for (_text, _label) in batch:
label_list.append(label_pipeline(_label))
text = text_pipeline(_text)
text = truncate(text)
text = torch.tensor(text, dtype=torch.int64)
text = pad(text)
text_list.append(text)
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.vstack(text_list)
return label_list.to(device), text_list.to(device)
Truncate , PadTransform 分别为 torchtext 中 截断 与 填充 的函数
试着跑一下
for i, batch in enumerate(train_loader):
pos, content = batch[0], batch[1]
print(pos)
print(content)
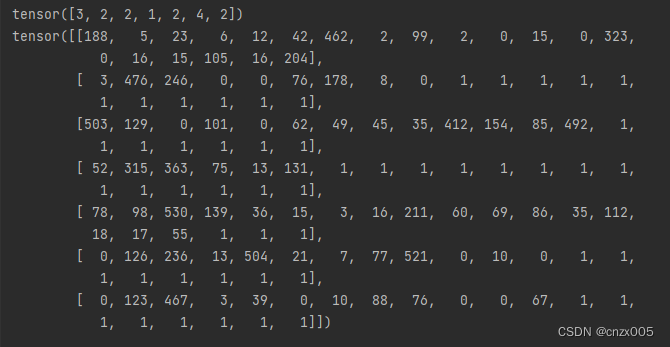
装载完成
后续
可能之后会用torchdata试一下torchtext,也可能不会,torchtext更新感觉跨度好大,指不定下次又更新什么,又得重新写了















 7309
7309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









