







当你看到上图AI回答“贾宝玉的最佳伴侣是贾母”时,有没有感觉它像是人工智障?当然,现在主流的Chat-BOT我都试过,再也不会有初代ChatGPT那样离谱的回答。
但不可否认的是:对于一个大语言模型(LLM)来说,如果你给它喂的数据没有营养,那它表现出来的智能程度也不会高到哪里去,输出的结果大概率也就不靠谱。
训练数据对于人工智能来说就是精神粮食的存在,只有食物(数据)提供的到位,做出来的菜才会香。如果训练数据不到位,可能就会真的把人工智能模型训练成人工智障。

2025年在AI迅速席卷商企政各界、跨层渗透生活圈的同时,我们来摆一摆这个话题——人工智能时代的数据资产。
一、【数海溯真】数据资产何为
我们都知道,人工智能的三大要素分别是算法、算力、数据。
算法——好大脑,它好比生产工具,算法创新代表着技术方法的突破与技术效能的提升;
算力——好身体,它好比生产力,算力聚集代表着强劲的计算性能和硬实力的革命本钱;
数据——好食物,它好比生产资料。数据丰富代表着强大的底层支撑和算法算力的转化动力。
数据(DATA)并不是人工智能时代才诞生的产物。广义上通过符号被描述并记录的内容,都可以称为数据。
数据与信息经常被混为一谈。事实上,数据是信息的载体,信息是消除不确定性之后提炼出的数据。数据带有客观性和随机性,信息包含主观意识和分析痕迹。这就好比,成都今天温度7-12摄氏度、湿度90%,昨天10-25摄氏度、湿度60%,以上称为数据;而天气预报表示今天成都大幅降温,这个就是信息。
因此不难理解,我们所称的信息社会、信息化建设,其核心都建立在由数据提取的、与人直接交互的信息之上。而科学领域的研究者需要暂时抛开信息,直接与承载信息的数据做交流,更客观的从数据中研究产生多种信息的可能性。
十多年前,大多数互联网和科技公司动辄要给自己标榜“大数据技术”,而今天,你基本上听不到“大数据”这个词,仿佛它已被时代浪潮所抛弃。
然而真实情况是,大数据技术本身是数据科学的一部分。在特定的时代背景下,它与云计算技术融合,建立了对多元数据的处理规范(如MapReduce、HDFS、Hadoop、Spark),孕育了从数据体系架构形成到数据处理与挖掘,进而正在被机器学习、深度学习等人工智能技术进一步赋能。
各领风骚数十年,这里不变的,是数据做为研究本体的基础要素价值。
人工智能技术从机器学习发展到语言大模型(LLM)与多模态模型构建,数据,成为了构成人工智能系统学习、决策和优化的基础。它不仅包括了用于训练、测试和优化人工智能模型的结构化、半结构化、非结构化数据,还涵盖了人工智能外部加工再生成的合成数据和标注数据,以及场景交互、人机交互、系统运行、模型衍生的应用数据。
0与1的数字与代码堆彻而成的,只能看作原始数据。由原始数据经过有序整理,就可以形成数据资源。而再将数据资源深加工,在相应领域产生经济价值,那就是数据资产。
举例来说,去年我给孩子买AI学习机,最后聚焦于科大讯飞和学而思两款产品。抛开硬件参数以及运用的星火与九章模型,两者之间最大的差别在于,学而思产品背后有教培市场20年教研沉淀,3000+人教研团队更新迭代的1400万+分钟内容资源同步更新,20000+本教学精辅精讲。假设学而思不做产品,这些数据资源也完全能提供给其他学习机硬件企业,这就是学而思的数据资产。
同理还有新能源汽车行业的比亚迪、吉利和蔚小理米,车辆行驶的各类参数不断反馈厂商用于研发迭代。3-5年后行业兼并重组时,车辆行驶和研发数据一定会作为数据资产成为谈判资本。
二、【万象织源】数据资产何来
人工智能大模型的数据资产,通常以数据集的形式体现。
数据集是什么呢?它好比一袋袋整齐归类过的各种类型的粮食。
一个代表性的例子是2009年发布的ImageNet数据集。
ImageNet是一个计算机视觉系统识别项目,2007年起,斯坦福大学的计算机科学团队通过组织人工标注方式,将超过1400万的图像进行分类和手动注释,比如每一个“皮球”或“汽车”的分类下,都包含有数百张图像。这相当于为视觉识别算法做了一个巨大的通用题库。
以此为基础,2010年至2017年举办的ImageNet挑战赛,检验全球各研究团队在视觉识别领域的算法能力。诞生了AlexNet(2012)、VGG(2014)、GoogLeNet(2014)、ResNet(2015)等耳熟能详的深度学习网络模型。
2012年杰弗里·辛顿(Geoffrey E. Hinton)和弟子伊利亚·苏茨克沃(Ilya Sutskever)和亚历克斯·克里切夫斯基(Alex Krizhevsky)提交的卷积神经网络AlexNet模型,直接将错误率降低了前所未有的近 10 个百分点,被视为这一轮人工智能技术热潮的启幕之战。(历史沿革参见之前写的《一文看懂DeepSeek的中国式创新》)
到2015年,卷积神经网络对ImageNet测试的识别错误率已经低至3.57%。换句话说,机器算法已经能够正确识别近97%的图像,而人类的测试识别正确率约为94.9%。
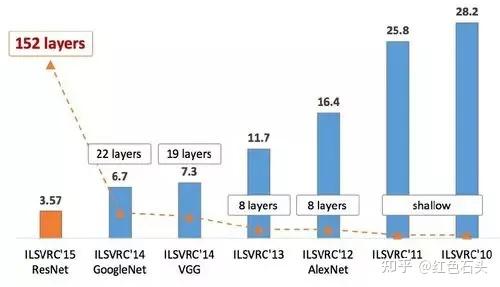
ImageNet贡献的是一个面向算法的开源数据集,其作用主要在于推动科研评测,本身不包含直接经济效益,所以我们不能把它简单归于数据资产。
但是,在大语言模型(LLM)的生成过程中,从设计、训练、评测、仿真到算法更新迭代的全生命周期,都有大量数据集的输入和产生,这些数据集是有特定价值的,所以一般不会公开。
当人工智能模型在具体场景适配应用时,例如之前提到的新能源汽车智能驾驶,又或是具身智能模拟仿真,无论是最初的场景环境数据,还是二次生成数据,这些私有数据集会被视为具有商业属性价值的数据资产。
你问OpenAI和DeepSeek最有价值的资产是什么?其中之一就是经过严格筛选和优化的海量训练数据。
总结一下,要将数据转化为数据资产,需要经过以下步骤:
第一,数据资源化。将原始数据进行原料初加工,经过收集、整理和清洗,转化为可利用的数据资源。
第二,资源产品化。将数据资源转化为具有特定功能和价值的产品或服务。
第三、产品价值化。通过数据产品的交易、流通等方式,实现数据的价值转化和增值。
三、【百川赋值】数据资产何用
“高筑墙,广积粮,缓称王。”600多年前,初创企业“大明”CEO朱重八欣然接受了这项战略提议,在元末群雄并起时局中稳扎稳打地构筑了自己的“护城河”。
随着数字经济的蓬勃发展,数据已成为企业最宝贵的资产之一。据国际数据公司(IDC)预测,到2025年,全球数据总量将达到175ZB。数据资产的积累和运用,不仅能够提升企业的决策效率,还能够推动产品和服务的创新,为企业带来直接的经济效益。
筑基护城。构成企业“护城河”的要素可以有很多种,比如信息差——赚你认识以外的钱,硬实力——专利或独有技术,先发优势——领先一步占领市场,生态体系——多元渗透形成相互关联支撑的产品生态,规模效应——大体量高质量形成品牌。而数据资源,也成为构成“护城河”的要素之一。电商、外读平台的护城河不止是推荐算法,还有基于数量庞大的采集数据生成的精准“用户画像”。生物制药、基因工程行业龙头企业的护城河,也一定是背后的专业数据。更不用说所谓的互联网“内容五巨头”:腾讯音乐、B站、爱奇艺、阅文集团、知乎。在线音乐、视频、网文、社区等不同赛道,以内容数据为资产的付费享受即为其核心商业模式。越是独角兽或单项冠军企业,越会像朱重八那样构筑坚实牢固的数据护城河。
驱动决策。运行数据是企业的体征指标,用户数据体现市场风向,数据资产成为企业决策的重要依据。企业通过分析数据资产,能够更准确地预测市场趋势,优化产品设计,提升客户服务体验,从而在激烈的市场竞争中占据优势。政府则可以依据数据分析结果,调整政策制定原则,更加有效实现对市场调控引导。直播平台的头部主播崛起,固然有其个人因素与市场需求,也离不开背后的MCN机构提供的流量分析、资源引导和赛道孵化。卖什么产品,用什么话术,甚至穿什么衣服、如何妆扮,主播与MCN决策都来源于数据。
创新拓源。商场如战场,灵敏的商业嗅觉会助力占据市场主动。数据资产既是决策的依据,也是创新的源泉。数据资产的深度挖掘和应用,为企业提供新的业务模式。年初DeepSeek横扫国内大模型市场,之前活跃在圈内的“AI六小虎”初创AI公司,浮在岸上的基座大模型公司仅剩若干家。但与此同时,垂类大模型应用正迎来井喷期,成为推动产业升级和商业创新的核心驱动力。
提升估值。数据资产信息发布有利于提升企业形象声誉,向市场传递企业具有竞争力的积极信号,扩大品牌影响力。同时,为投资者精准掌握企业经营发展实力,提高投资者信心,从而提升企业保值。双11购物狂欢节,自2009年开启,2012年开始使用实时大屏显示成交金额以及其他数据信息,在直播带货尚未兴起的电商时代,大屏展示的交易数据,既是电商成交数额的真实感观体验,也是一种内部激励和技术炫耀,更是平台综合实力体现。曾经有人说,因为这个实时大屏,他一整晚都没睡,边盯着屏幕边剁手,大屏上的数据刺激着他持续想消费。
四、【潜礁暗涌】数据资产何患
若干年之前,我们经常会看到一车小汽车顶架着摄像头,缓慢穿行于大街小巷,摄像头旋转着摄像街景,再后来,手机地图APP上就有了全景地图选项,点击可以看到某个街角的实景图。
APP地图里的全景数据采集合规吗?采集全景数据是无偿免费的吗?数据资产形成的背后,还有哪些潜在的风险隐患呢?
数据质量:数据的准确性、完整性和一致性是数据资产价值的基础,但数据质量问题普遍存在。大模型公司通过语料数据训练基础模型,垂直分类领域利用标注数据做监督微调,这是目前主流AI玩家的基本操作。诚然,GPT-4几乎把整个互联网的语料库精华一网打尽,监督微调也养活了一群数据标注公司,由此产生数据对齐的概念。然而,语料库精华仅仅是世界万物已经呈现或是前人总结的一部分,还存在巨量的多模态数据,以及今后可能出现的未知数据,所以靠已有数据和人类标注监督是不可能完全覆盖的。数据质量不高,模型会产生“幻觉”,数据质量如果被人为错误标注,则会出现“数据污染”,进而影响模型输入。那如果让AI自己对筛选、清洗、原始数据,自己去标注和合成数据,自己去反馈评估并且改进呢?这就是杨立昆的“世界模型”和LLYA的“超级对齐”概念了。
数据安全:数据泄露、数据滥用等安全问题可能导致重大损失。这是一个老生长谈的问题,具体案例和警示就不太多说了。值得注意的是,AI数据安全与网络防护密切相关,实际上是网络安全在AI领域的延伸,数据加密和网络防御等技术同样适用于保护AI数据资产。
数据隐私:数据隐私保护是数据资产管理的重要方面,尤其是在涉及个人数据时,必须严格遵守相关法律法规。2018年5月25日,欧盟出台了《通用数据保护条例》(General Data Protection Regulation,简称GDPR),是全球数据隐私保护的一个里程碑事件。继该条例之后,世界上许多国家都颁布了自己的数据保护立法。拿用户佩戴智能手环为例,用户在使用手环前,下载APP时会收到点击同意确认授权的提示,确认之后才可以使用。在我看来,这里的逻辑还是有问题的。企业向用户提供服务的同时,也是在收集用户的数据,难道不应该是企业向用户承诺,而不是带有半强迫式性质的逼用户授权。
数据孤岛:企业与企业、行业与行业之间,通常有着很强的壁垒。数据分散存储,模型、应用与外部之间缺少有效链接协议,专业数据拥有者的私有化心理,都容易形成数据孤岛,影响数据资产的整合和共享。拿近期比较火的MCP(Model Context Protocol,模型上下文协议)来说,这款由AI公司Anthropic于2024年11月发布的一种开放协议,核心作用是解决AI模型与外部数据的高效调用。AI模型的生成是靠已有数据训练而成,而模型问答都一个“联网搜索”的角标,目的是模型实时与互联网开源数据做调用。对于专业化数据,AI模型如果不做接口,回答的结果肯定是不准确的,而面对众多应用,一一对接开发的效率实在低下,于是这款“万能接头”的MCP协议迅速被各AI模型公司接受,被业内认为是破冰“数据孤岛”、构建链接模型与外部生态的重要工具。
数据权属:数据与其它商品要素一样,存在权属确认问题。参照土地权属,那数据资产也可以分为所有权、使用权和经营权,目前数据权属制度仍在探索建立当中。因此,在我们无法明确数据资产权属可能带来的纠纷时,通常用“知识”来替代“数据”的表述。拿AI+医疗产业来说,可以称得上是场景丰富、技术可行、前景广阔,众多门类的医产数据为AI基座模型寻找切入口提供了契机。与此同时,医疗行业内部掣肘、技术端对数据不具有属权,限制了数据向资产形成后的利益风险。当百川智能决定在医疗领域深耕时,很多人并不看好的原因之一是百川并不拥有医产数据,无法建立属于自己的医疗模型护城河。
数据价值评估:数据资产的价值评估是一项新兴产物,数据不以实体存在,流通性和易变性强,评估尚无权威机构,资产价值受场景、市场、成本、质量等多种因素影响,评估缺乏统一的标准和方法。在数据资产的价值体现还不够充分,数据立法仍在建立完善的阶段,未来关于数据资产价值的潜在商业纠纷也现实存在。
五、【云途共赴】数据资产何去
我们先从2020年新一轮AI浪潮涌起时,梳理国家在数据建设关键节点上的谋篇布局。
2020年4月,中共中央、国务院出台《关于构建更加完善的要素市场化配置体制机制的意见》,首次将数据与土地、劳动力、资本、技术并列,明确列为第五大生产要素,并提出加快培育数据要素市场的方向性要求。
2021年9月1日颁布《数据安全法》,确立数据分类分级、跨境传输安全管理等制度,首次将数据安全纳入法律体系。
2022年12月,国务院出台《关于构建数据基础制度更好发挥数据要素作用的意见》(“数据二十条”),提出数据产权、流通交易、收益分配等基础制度框架。
2023年成立国家数据局,负责协调推进数据基础制度建设、数字中国建设等,标志中央层面对数据要素治理的强化。
2023年2月出台《数字中国建设整体布局规划》,将数据资源体系列为数字中国建设的核心内容。
2024年9月下发《关于加快公共数据资源开发利用的意见》,加快公共数据资源的开发利用,提升资源供给规模和质量,培育数据要素型企业。
2024年12月31日下发《国家数据基础设施建设指引》,明确建设和运营国家数据基础设施,促进数据共享,推动数据要素的高效流通和利用。
2025年1月下发《公共数据资源授权运营实施规范(试行)》《公共数据资源登记管理暂行办法》《关于完善数据流通安全治理 更好促进数据要素市场化价值化的实施方案》,规范公共数据资源授权运营,完善数据流通安全治理,促进数据要素的市场化价值化。
包含但不仅于以上政策措施可以看出,国家在数据管理和开发利用领域,早已起步规划政策框架,逐步建立数据要素市场,为推数据要素形成数据资产创造了有利条件。
数据资产的概念,改变了科技投资深层次逻辑。过去信息化建设投资只是支出,是成本项;数据资产的概念出来之后,企业和各地政府逐渐认识到数据资产是一个“富矿”,能够成为资本项,甚至能够创造收益。有的省份成立了大数据集团,集中收集、管理省级数据;有的地方甚至要把数据资产打包售卖。
数据要素市场建立和数据资产形成是一个长期过程。宏观层面,随着数据资产观念普及,数据要素流通通道会更加通畅,将驱动人工智能相关产业发展,为生成式AI的国产化、自主化创造条件和土壤。而数据要素市场的打通和开放,同时配备相应的数据治理体系,数据产权体系会逐步确立。
微观层面,数据资产的发展形成,将促进AI技术面向垂直领域更多具象化应用,垂直大模型类型的丰富,又会催生AI智能体的一体化模型(类似初创公司Monica开发的Manus)。大众能够感知的场景,如特定应用的AI客服、进厂打螺丝的AI牛马、个性化服务的医疗助手,数据资产既存在于开发厂商和应用企业,也关联着每一个端侧用户个人。
1980年,美国科技记者阿尔文·托夫勒(Alvin Toffler)在所著的《第三次浪潮》(The third wave)中,非常肯定地指出“数据就是财富”。
当你清晨开启电动牙刷,手带智能手表,操控智驾汽车时,你不仅是智能时代AI工具的享受者,也是人工智能技术发展的贡献者。
(完)
https://www.zhihu.com/question/41253829/answer/2314090371(亿信华辰,知乎)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









