






不用大篇幅技术词汇
不搞精神胜利和闭眼狂喷
想用客观的“人话”说一说自己理解的DeepSeek中国式创新
1月21日晚写了一篇《时代巨响——也谈DeepSeek从V3到R1》
次日发在CSDN一周涨到1.6W阅读量,想来大概是AI在春节前的风口
随着春节前后数个大模型陆续发布,网络热评已经从技术圈扩大到社会圈、朋友圈
国内外好评与差评,热捧与诋毁,在我看来都是浮云
它既不会影响DeepSeek自身的迭代,也不会掣肘同行探索脚步
事无绝对,DeepSeek也是同样,今天起就啰嗦两句
从人工智能N落N起演进中,审视DeepSeek的中国式创新
观点未必正确,不喜勿喷
提及人工智能(AI)和现在火热的大模型,有几个问题摆在面前:
1.AI赛道中为什么大模型当今被炒得这么热?
2.OpenAI做的ChatGPT真的不如DeepSeek吗?
3.DeepSeek是未来AI发展的方向吗?
我的回答:1.适者生存。2.不是。3.未必。
摸着时间脉落,先从AI起落沉浮说说发展史上几个关键研究成果,然后再做比较
一、
互联网上能看到太多的人工智能发展史或编年史,我就不赘述了。
上世纪40年代开始人工智能的混沌探索,其核心是想制造出类似人类思考和行动的机器。造出这个智能体:
1.你得跟人交互吧(如果人类语言不能直接听懂,人类通过电脑发送通用指令应该被接受)
2.你得有所谓的逻辑思维和运算能力吧(其实人类也没有完全搞清思维是怎么回事,从神经元模拟开始,生物科学进一步,人工智能进一步)
3.你得能自如移动吧(例如机器狗和具身智能机器人)
科学家很早就知道,造一个铁皮壳子很简单,机器人的行为动作取决于它的大脑,所以设计它的思维模式才是根本。

1956年,达特茅斯学院研讨会上正式使用了人工智能(artificial intelligence,AI)这一术语后,早期的各种AI流派研究角度各有不同,他们做出了能够证明部分定理的程序,也写出了棋类简单游戏,研究过通过符号来解读人类获得知识的方式,但实话说来,从理论上并没有研究出可行的路线。
那时的计算机编码和逻辑推理设计,语言翻译搞不定,视觉感知更别提,加之当时计算能力和数据存储限制,也就是路线和能力皆不具备。摸着石头过河,没投资、没技术、普世悲观,AI寒冬纪。
二、
走的人多了,也便成了路。第一次横空出世的引领者是机器学习(ML)走出新路线。
机器学习这个方法早在1959年就被提出,它的原理可以概括为处理数据、提取特征、训练模型、改进性能、给出结果。
是的,我们后来所知道的DeepBlue机器战胜国际象棋棋王卡斯帕罗夫、AlhpaGo战胜围棋冠军李世石和柯杰、某音某宝精准推送音乐和商品,不都是这条路线吗。所以回头看,人工智能的研究是选择了机器学习这条赛道。
但为什么会是机器学习呢?
我们看标黑字体的第四个,改进性能,没错,流程中加了改进性能,实际上包括了运用逻辑门电路(与、或、非)建立反馈机制,而这就是神经网络的雏形。借一张C友的图
我只有不断的纠错反馈才能让我变的更强大。好熟悉,有没有。跳出历史周期率的第二答案——自我革命。还说社会主义科学不是科学?
言归正传,1982年,约翰·霍普菲尔德(John Hopfield)在自己的论文中重点介绍了具有记忆和优化功能的循环(递归)神经网络(RNN)。
这个RNN突破在哪里呢,传统的机器学习里神经网络算法,输入和输出是直线。
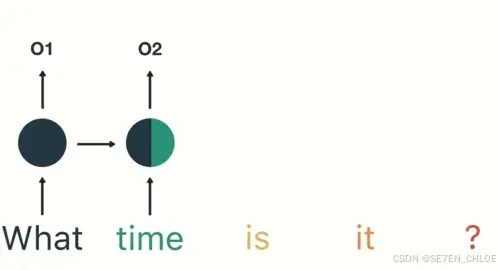
RNN最大的区别在于每次都会将前一次的输出结果,带到下一次的训练,这使得每一个后位数据都与前序数据产生关系影响,通过计算相似关系而预测后一数据。
例如,我问What time is....它会根据前三个单词的意思和与之关系,预测最后一个词是it。
1986年,戴维·鲁梅尔哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)等人共同发表了一篇名为《通过反向传播算法的学习表征》的论文。
在论文中,他们提出了一种适用于多层感知器(MLP)的算法,叫做反向传播算法(Backpropagation,简称BP算法)。
BP算法是什么,好比①②③④⑤五位同学传信息,当信息传到②号时,他在往③号传的同时,还要向①号发送反向信息检验传递的准确性。
同理,③④⑤号同学也会逐个反向验证,通过计算信息传递的损失,得出各位同学能力的大小个头(称为梯度),利用算法来调整梯度权重,从而最小化损失。
我认为RNN和BP的诞生是核弹级别,让机器学习真正意义上活了,可行了,有路可走了,起码是找到方向了。
这算是大创新吧,国际大奖的认可比较迟,直到2024年,约翰·霍普菲尔德与杰弗里·辛顿(Geoffrey E. Hinton)才共同获得了诺贝尔物理学奖。Better late than never,发展进程不断为后人探索已经证明了创新的价值。
三、
循环递归神经网络(RNN)和反向传播算法(BP),确实是两把好工具。但是在应用中不免遇到问题。
比如,传递信息的同学太多,每个同学都要向后面所有同学确认,计算量越来越大怎么办?
相邻站位的同学大小个头太接近,或者差距太大(梯度近似或失真),计算差值不准确怎么办?
1997年,德国计算机科学家于尔根·施密德胡伯(Jürgen Schmidhuber)与其弟子塞普·霍克赖特(Sepp Hochreiter)开发了长短期记忆网络(LSTM)。
LSTM有什么特别之处呢,它引入了记忆细胞、输入门、输出门和遗忘门的概念。
记忆细胞负责保存重要信息,输入门决定要不要将当前输入信息写入记忆细胞,遗忘门决定要不要遗忘记忆细胞中的信息,输出门决定要不要将记忆细胞的信息作为当前的输出。
打个比方,当一本小说我看到中间部分时,离我当前最近的前一段落,可能是我记得最清楚的,而开头的一此细节可能就记得不那么清楚了,这叫短时记忆,前面提到的RNN就是那种短时记忆。离得越近,相互影响越强。
而LSTM会选择重要信息并加以权重,那看到小说中间的时候,我还是会想起前面埋下的伏笔。
由此来看,LSTM是RNN的高级形式,与BP有异曲同工之妙。
但是德国大叔对自己成果在AI学界被忽视表示强烈不满,批评同行、开喷Meta、怒怼图灵奖,有点儿祥林嫂的感觉,有兴趣的小伙伴可以自己搜来看。
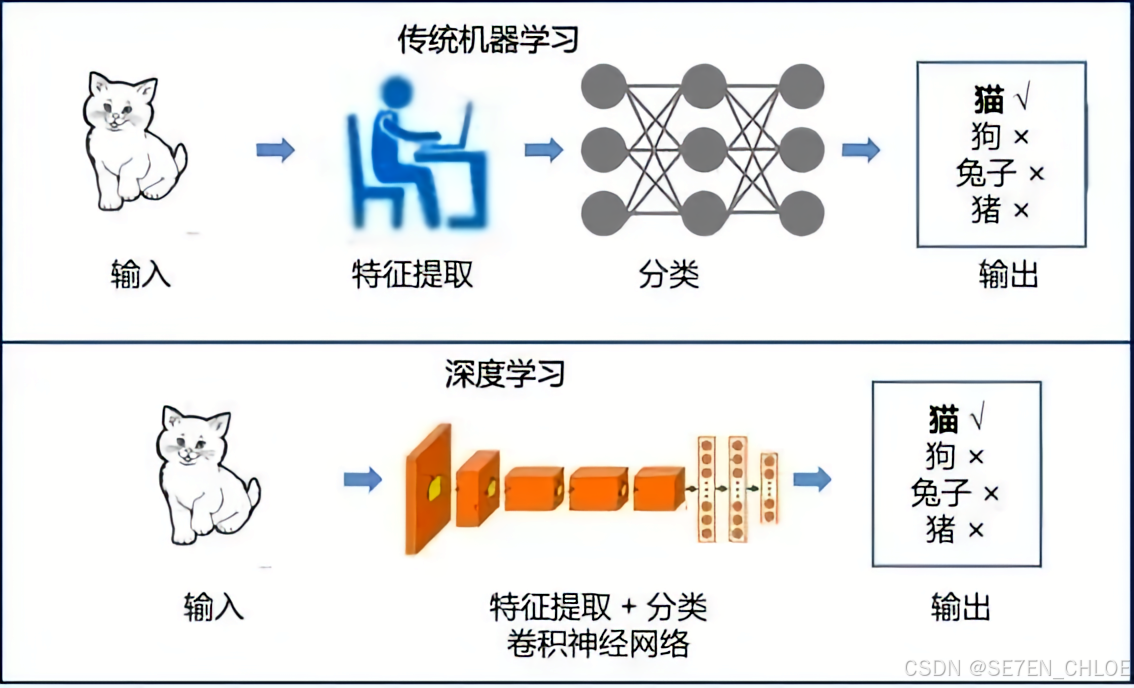
另一个事件是2006年,杰弗里·辛顿正式提出深度学习概念。主要观点是:多隐层的人工神经网络具有优异的特征学习能力,学习到的数据更能反映数据的本质特征有利于可视化或分类。
之前机器学习的RNN到BP、LSTM路线,构建的有输入、有反馈、有权重、有输出的循环模式。总体上它可以看作是简单的神经网络,也就是它就像在模拟生物神经元的工作方式来处理数据。这就是人工智能模仿生物神经元思维的路线。
单一的神经网络只能对连续的序列(例如语音、文本)单线条的处理,而多线程直至1998年卷积神经网络(CNN)的出现,就好比一台由无数神经元组成的并行机器,要有组织有规模的工作了。
可以想象这是比较耗费计算资源的一项工程,从此,人工智能研究正式开启了算力比拼。
我认为相比LSTM和CNN这种导弹级别的成果,深度学习概念的提出是核弹级别的创新。
因为它引出一条看似可行的AI之路,终于使得原本用于图像处理的芯片(GPU),参与到更加复杂的计算之中。
芯片商业帝国重新划分,原本的图像领域单项冠军英伟达(NvIDIA)市场份额逐渐超过CPU厂商Inter和AMD,独领高性能计算风骚。
待续未完……
春节晚上每天晚上码几字,喜欢的点个赞


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









