










Screaming Frog SEO Spider 最强大的功能之一是能够使用自定义提取从网站批量抓取您想要的任何信息。如果要创建高级自定义提取,则需要学习如何使用函数。
Screaming Frog 发布了 21 版,该版本已将其支持从 XPath 1.0 升级到 2.0、3.0 和 3.1。这意味着我们现在可以使用高级函数将这些自定义提取数提高到 11。请参阅下面的一些 XPath 函数示例以及如何使用它们从站点抓取信息的示例。希望这些会激发您创建自己的自定义提取以实现一些惊人的分析。
string-join()
功能: 该功能将符合 XPath 查询的多个内容组合在一起,并用指定的分隔符分隔。
语法:
string-join([Target XPath],"[delimeter]")
例如: 提取 <p> 标记中用空格分隔的所有文本:
string-join([//p," ")
这对于杂乱无章的 HTML 模板来说尤其方便。你不用再处理零散的数据,而是可以得到一个干净的字符串。
distinct-values()
功能: 删除提取结果中的重复值,只返回唯一值。
语法:
distinct-values([Target XPath])
示例 1: 获取页面上使用的所有唯一 CSS 类的列表:
distinct-values(//@class)
这将返回页面上使用的每个类的去重列表。在抓取整个网站时,你可以将列表与 CSS 文件进行比较,看看是否有未使用的样式可以删除,从而加快网站的加载速度。
示例 2: 您可以将它与 count() 函数结合使用,以识别出含有臃肿 HTML 的页面:
count(distinct-values(//@class))
这将计算每个页面上的唯一类的数量。这样做的目的是,唯一类的数量越多,HTML 就越臃肿,就越有机会创建更简洁的代码,使加载速度更快,更易于搜索引擎呈现。
starts-with()
功能: 在最新版本发布之前,搜索引擎优化蜘蛛其实就支持这个小工具了,但我也是刚刚才发现它。它可以过滤搜索结果,以包含以特定字符或字符串开头的内容。
语法:
starts-with([Target XPath] 'lookup string’)]
例如: 一个非常强大的功能是提取所有相对 URLS,这意味着你可以从每个页面获取所有内部链接的列表,如下所示:
//a[starts-with(@href, '/')]/@href
这将从页面上的每个链接中提取以开头的每个 URL,以便审核内部链接策略或导航审核。
ends-with()
功能: 该函数的工作原理与此相同,但会搜索属性末尾的字符串。
语法:
ends-with([Target XPath] 'lookup string’)]
例如: 可用于查找某些文件类型(如 PDF 文档)的所有链接:
//a[ends-with(@href, '.pdf')]/@href
matches()
功能: 它使您能够将 XPath 与 Regex 结合起来,为您的自定义提取提供更多动力。 该规则的优点是可以同时使用多个条件,根据一系列条件进行提取。
语法:
matches([Target XPath], '[regex rule]')]
示例 1: 提取图像文件的链接:
//a[matches(@href, '\.(jpg|png|gif)$')]/@href
这将返回任何包含 jpg、png 或 gif 的链接的 URL。 由于图片链接一般不会增加价值,因此这有助于找到导航的死胡同。
示例 2: 您可以用它来识别任何包含 UTM 参数的链接,这些参数会对您的分析跟踪造成严重影响:
//a[matches(@href, 'utm_')]/@href
exists()
功能: 检查页面上的某个 HTML 片段是否实际存在,如下所示:
语法:
exists([Target XPath])
例如: 可用于识别重要 HTML 片段的缺失位置,如元描述:
exists(//meta[@name='description'])
如果元素存在,则输出一个布尔值 “true”;如果不存在,则输出一个布尔值 “false”。
format-dateTime()
功能: 您可以格式化您的发布日期,使其更容易按日期进行组织。 这取决于您的文章是否有一个属性,该属性以 XPath 可以读取的格式包含日期和时间。
语法:
format-dateTime([Target XPath], '[Y0001]-[M01]-[D01]')
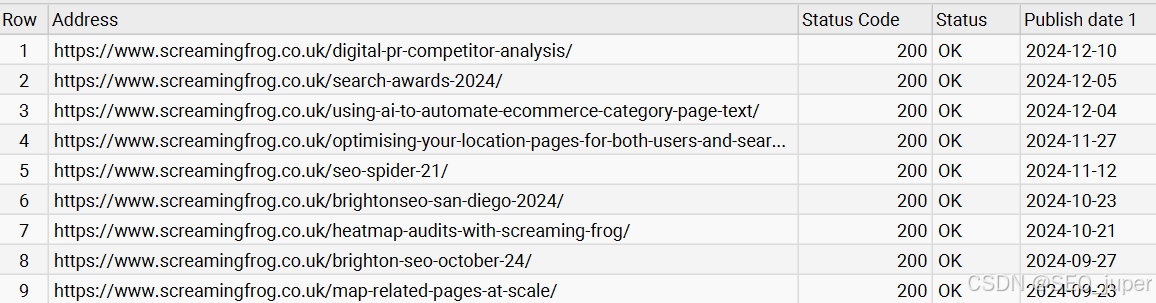
例如: 以下示例将日期整理为 YYYY-MM-DD 格式:
format-dateTime(//time/@datetime, '[Y0001]-[M01]-[D01]')
或者,您也可以通过以下方式从开放式图表数据中获取日期:
format-dateTime(//meta[@property="article:published_time"]/@content, '[Y0001]-[M01]-[D01]')
结果如下:
if()
功能: 这个功能强大的函数只有在满足特定条件时才会返回 XPath 的值。
语法:
if([conditional XPath]) then [Target XPath] else ''
例如: 使用以下 XPath 规则检查带有 noindex 标记的页面的规范 URL:
if(contains(//meta[@name='robots']/@content, 'noindex')) then //link[@rel='canonical']/@href else 'Not noindexed'
这一概念可用于各种不同的应用,从不连贯的 canonical 标记、缺失的 alt 描述、到社交资料的 nofollow 链接等等。
您可以使用比较运算符(如或)来筛选结果,从而提高效率。 让我们看看下面的示例,该示例通过计算文章中的 <> <p> 标记数量来识别薄内容,然后返回这些内容以进行快速分析:
if(count(//p) < 4) then string-join(//p, ' ') else ''
tokenize()
功能: 该函数用分隔符分割提取的值,类似于 Google Sheets 中 SPLIT() 函数的工作方式。 可能需要几次操作才能正确使用,请耐心等待。
语法:
[Target XPath] ! tokenize(., '[delimiter]')
例如: 使用以下 XPath 规则检查带有 noindex 标记的页面的规范 URL:
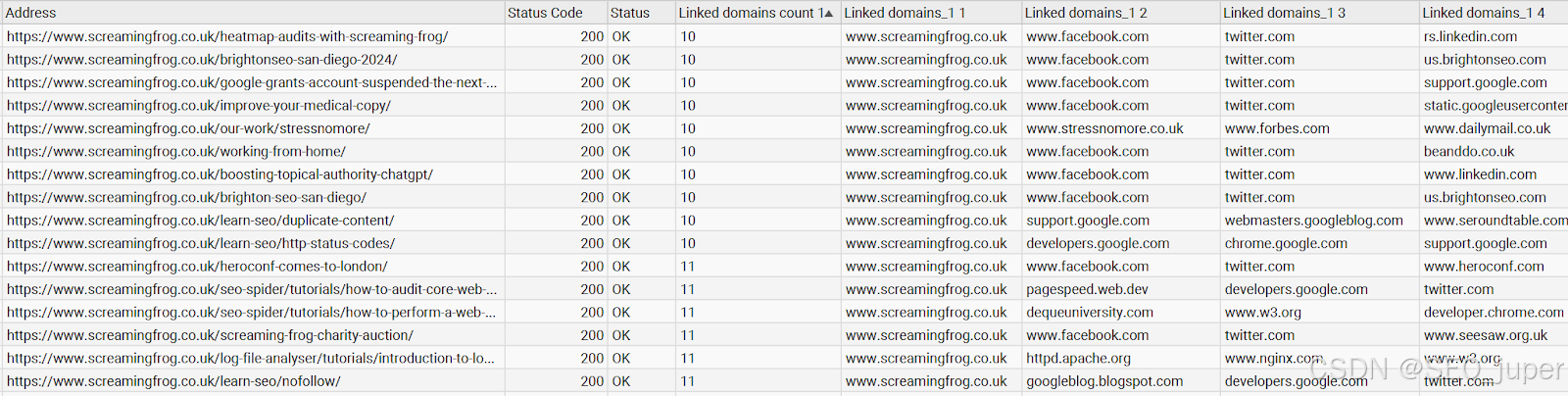
//a[contains(@href,"http")]/@href ! tokenize(., '/')[3]
因此,第一部分是要提取的目标 XPath,在本例中是 URL 中包含 "http "的所有链接。 第二部分会在每次出现斜线时将其分割出来。 我在末尾添加了 [3],以便只返回第三个提取内容实例(即域名)之后的结果。
在此示例中,我还添加了 distinct-values() 函数,以删除列表中的重复内容,从而得到以下结果:

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









