






前言:目前在C语言的这块内容我并不打算讲述过于基础的东西,我会着重讲解一些易忘易错的知识点,而且我写博客的初衷是帮助我自己复习,同时若有人能从我的博客受益当然更好。我注重博客的质量而非数量,因此我一篇博客可能涵盖量较大,后面我可能会有调整,但目前来说我依然会采取这种写博客的方式。
1.嵌套函数和回调函数的区别
嵌套函数和回调函数都拥有在一个函数里调用另一个函数的功能,但它们在使用场景上有明显区别。
嵌套函数:嵌套函数是C语言高内聚写法原则的典型例子,将一个功能封装在一个函数里,调用这个函数实现一定功能。其实嵌套函数特别常见,因为在main函数里调用的任何函数都是嵌套函数。
注意:函数可以嵌套定义,但是不能在main函数里直接调用被嵌套定义的函数,因为被嵌套定义的函数的作用域只包含它的外部函数,main函数访问不了。
回调函数:回调函数是在调用一个函数时将一个函数指针传给形参,让这个函数在内部在某个条件下可以用这个函数指针找到对应的函数,并再通过找到的函数实现一部分功能。回调函数其实也是嵌套函数的一种。回调函数是在需要根据不同情况调用不同函数时使用,一般要和函数指针数组配合使用才有意义,因为这样可以根据不同选择将数组中相应的函数指针传给回调函数。
2.常用的头文件
(1)qsort,srand,rand要包含<stdlib.h>
(2)errno要包含<errno.h>
(3)isspace,isdigit,isupper,islower要包含头文件<ctype.h>
(4)offsetof要包含<stddef.h>
(5)size_t引用的头文件(选其一):<stddef> <stdio> <stdlib> <string> <time> <wchar>
(6)NULL引用的头文件(选其一):<stddef> <stdlib> <string> <wchar> <time> <locale> <stdio>
后续会不断添加
3.字符串函数细节
(1)strcpy和strncpy
strcpy拷贝时会把源字符串的\0一并拷过来,并且在\0被拷贝之后停止
strncpy拷贝时有num参数确定要拷贝多少个字符,源字符串大小<num时,默认补\0,
源字符串大小>num时,不会拷贝\0,这点要和strcpy区分
注意区分printf,strlen都是读到\0停止,并不会读取\0
(2)strcat和strncat
strcat覆盖目标字符串\0,并将源字符串包括\0一并追加过来,之后停止
strncat回将指定大小的字符追加过来,但最后还会补一个\0,追加的大小相当于num+1,如果追加的个数刚好是sizeof arr,最后会有两个\0,因为无论什么情况,strcat都会再加上一个\0
strncat中追加的num>源字符串大小时,只会将源字符串到\0追加,不会再多加\0
(3)strcmp和strncmp
strcmp不是比较字符串的长度,而是比较对应下标字符的ASCII码值谁大。比如"abcdef"和"acb",后面的字符串比前面的字符串大,因为同为下标1时,c的ASCII值比b大。
strncmp只比较num个字符,后续的不管,这个比较简单
(4)strstr
strstr是找到参数中后一个字符串在前一个字符串中出现的位置,找不到就返回NULL,找到就返回第一次出现的首元素的首地址
(5)strtok
这个函数比较难以理解,用于将字符串自定义分隔,其表达形式为
char* strtok ( char* arr1, const char* arr2);
arr2用于指向分隔字符,在arr1中若找到了arr2,就强制把arr1相应位置改为\0,所以一般arr1会复制一份留作备份
strtok在使用一次后会保留arr1被分隔处的地址,第二次开始 char* arr1 直接传NULL就行了,如果后面找不到分隔符,函数返回 NULL
#include <stdio.h>
#include <string.h>
int main()
{
char* ret = NULL;
char sep[] = ",";
char arr[] = "Hello,World,hello";
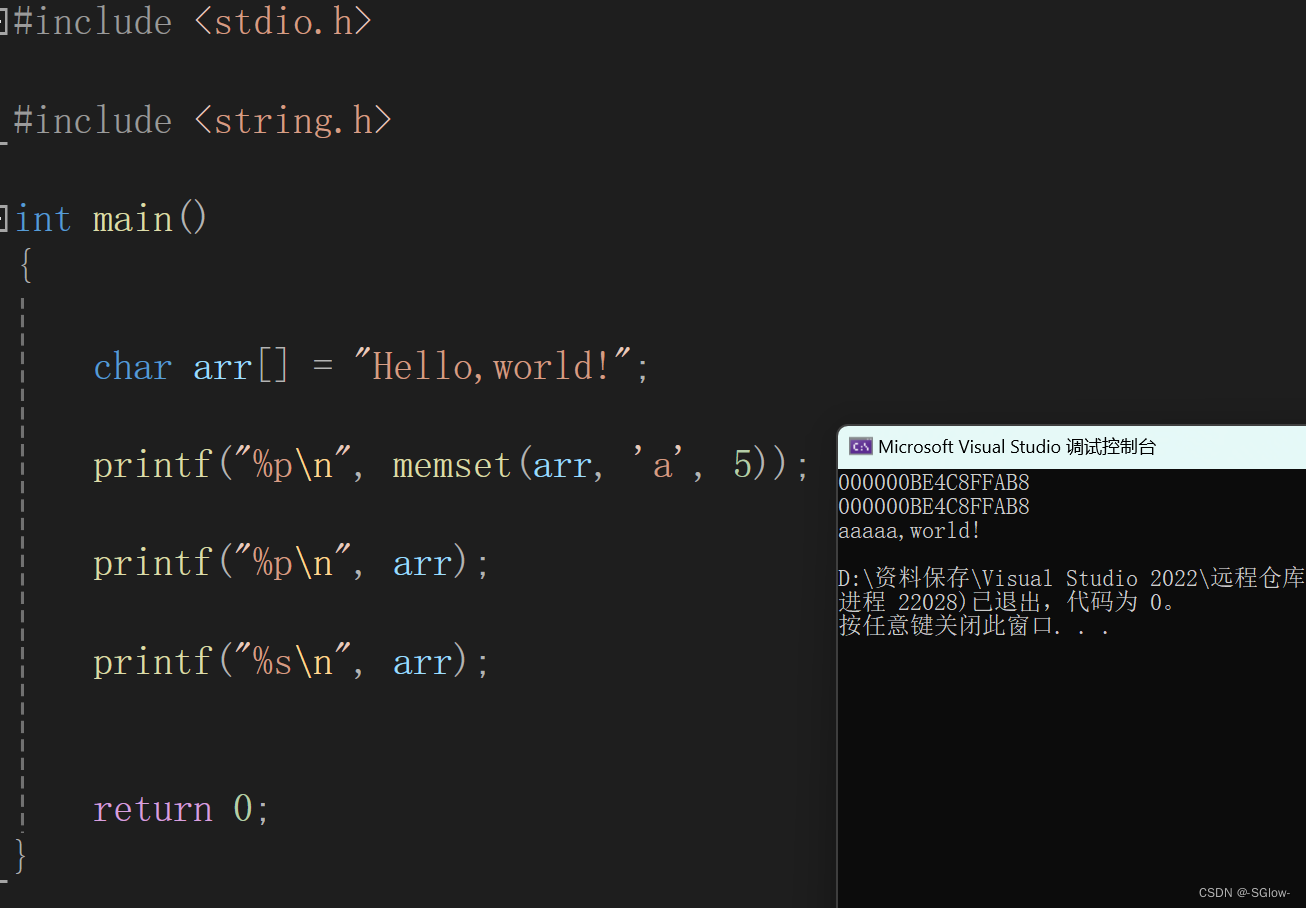
ret = strtok(arr, sep);
printf("%s\n",arr );
printf("%p\n", arr);
printf("%p\n", ret);
while (ret != NULL)
{
ret = strtok(NULL, sep);
printf("%s\n", ret);
}
return 0;
}
运行结果

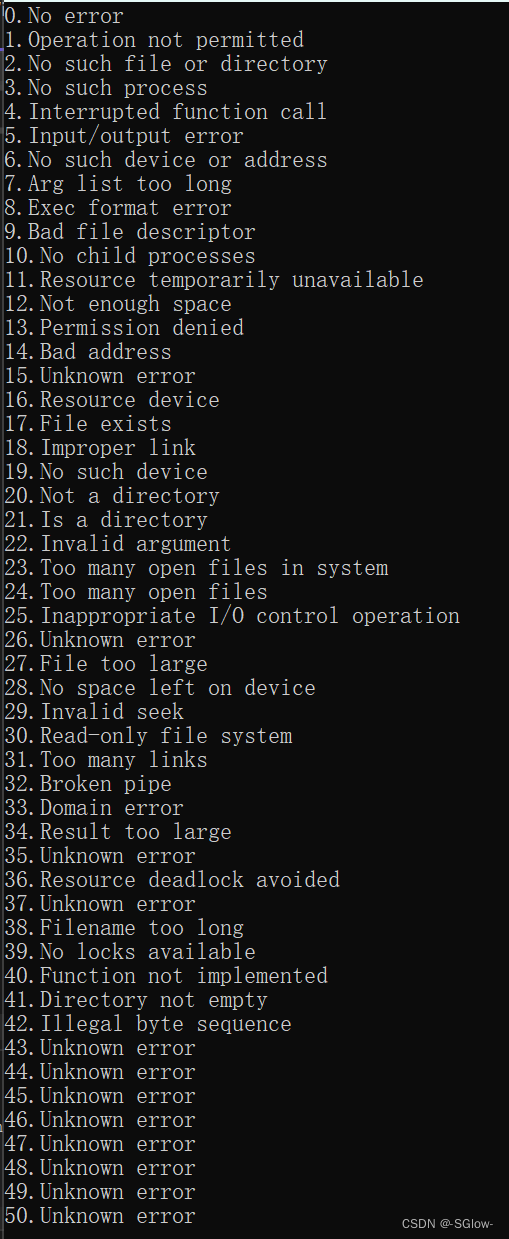
(6)strerror
这个字符串函数使用要包含<string.h>和<errno.h>,其中errno(全局变量)会记录程序运行时的错误(数字),开始时errno值默认为0,之后每遇到一个错误就会更新它的值,遇到连续的错误会存在覆盖现象,strerror(errno)函数返回的字符指针指向的是描述相应错误的字符串
#include <errno.h>
#include <stdio.h>
#include <string.h>
int main()
{
int i = 0;
for (i = 0; i <= 50; i++)
{
printf("%d.%s\n", i, strerror(i));
}
return 0;
}结果是
当然,你也可以用perror("你要输入的内容")直接打印错误信息,打印的时候会自动补上冒号
4.内存函数细节
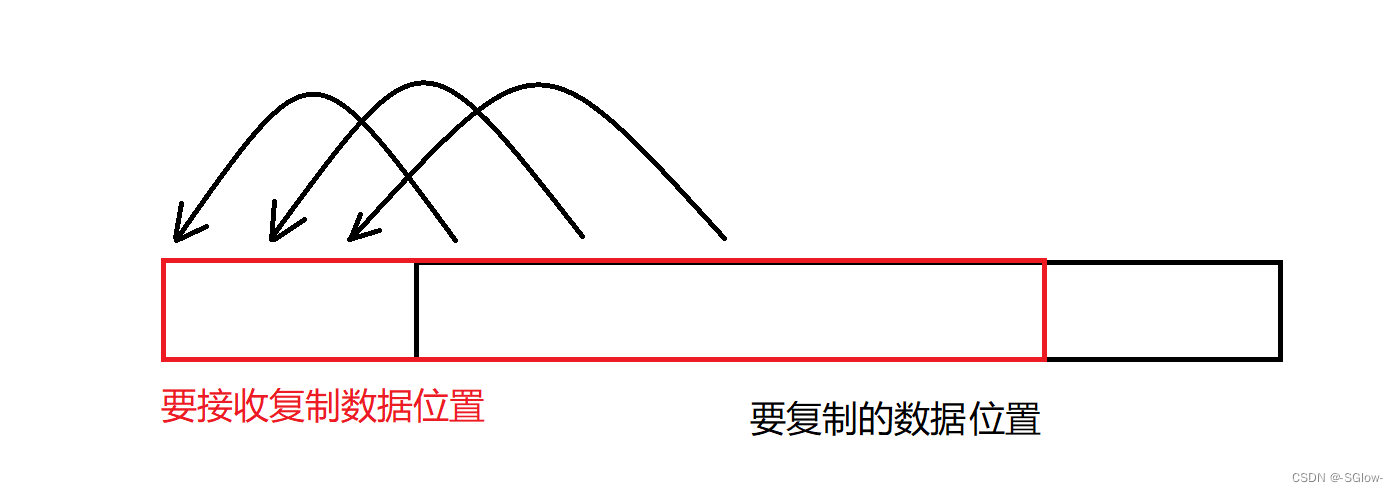
(1)memcpy和memmove
相较于strcpy,memcpy会严格复制对应字节的数据到目标数组中,不会自动停止,但是复制时会存在覆盖导致信息复制错误,这点问题在strcpy和strncpy也会出现,解决方法如下:
或
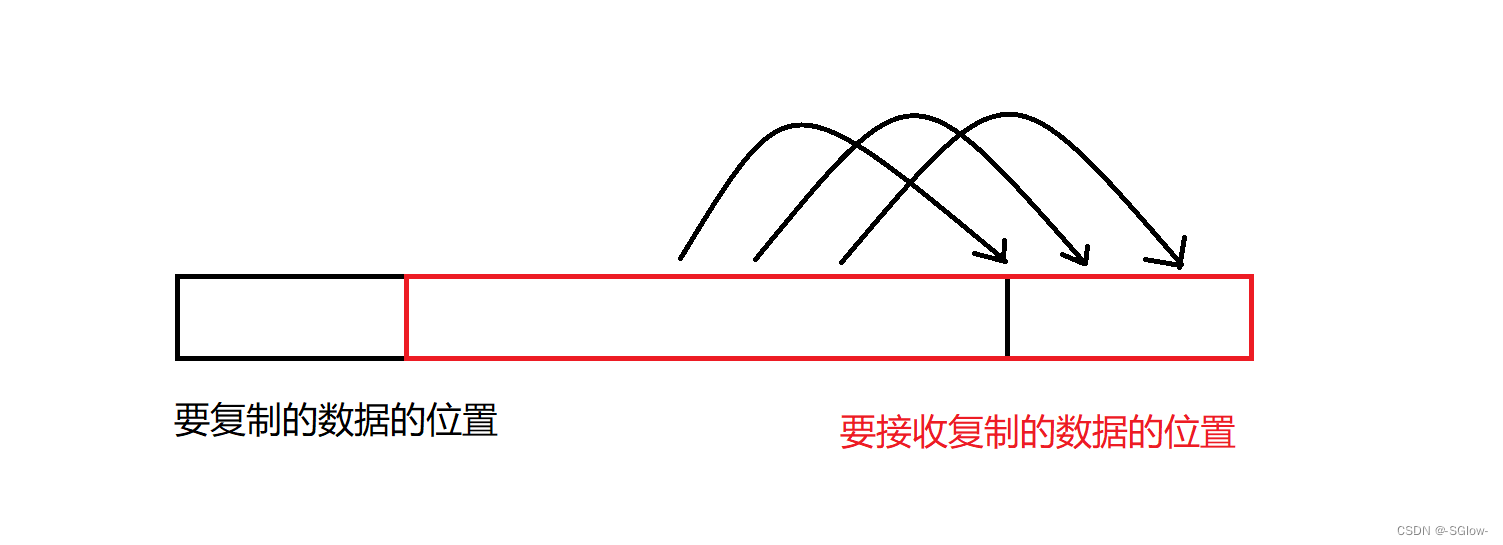
根据源地址和目标地址的大小关系,选择不同的复制顺序
memmove与memcpy基本原理一致,但是使用memmove就没有如上的问题了,平时可以多考虑使用memmove
(2)memset
这个函数形式是 void* memset ( void* arr, int i, size_t num ),返回arr地址
将arr数组内容中num个字节初始化为i,注意,第二个参数可以用字符表示,字符存储的是ASCII值,本质上也是整型家族的成员
(3)memcmp
int memcmp ( const void* ptr1, const void* ptr2, size_t num );
注意前(ptr1)小于后(ptr2)返回小于0的数,等于返回0,前大于后返回大于0的数
5.结构体的不完全声明(匿名结构体)
struct
{
int a;
int b;
}i;
struct
{
int a;
int b;
}* p;
int main()
{
i.a = 1;//可行
p = &i;//类型不兼容
return 0;
}在匿名下,该结构体完全独立,不能被取地址,就算指针对应的struct类型完全一致,也会被识别为两种不同的类型。同样,也无法在main函数创建变量,
为规避这样的问题,我们可以对它进行重命名,重命名时对应的参数的字母要完全相同,否则无法区分导致重命名后混乱。
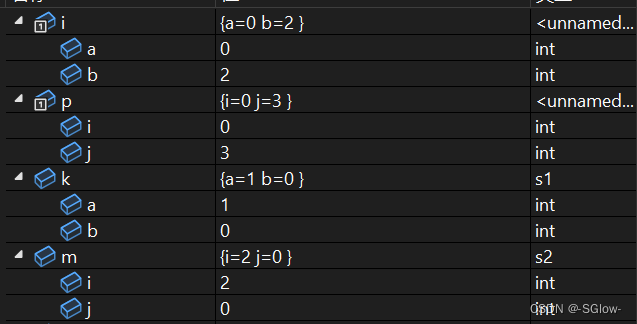
下面可以看看i,p,k,m这四个结构体分别存储的值
struct
{
int a;
int b;
}i;
struct
{
int i;
int j;
}p;
typedef struct
{
int a;
int b;
}s1;
typedef struct
{
int i;
int j;
}s2;
int main()
{
i.b = 2;
s1 k = { .a = 1 };
p.j = 3;
s2 m = { .i = 2 };
return 0;
}注意i在重复使用,这两个i的生命周期都一样,从程序开始到程序结束,但这两次出现的i的作用域不同,由struct创建的i相当于全局变量,整个程序都能使用,但后面struct内部的i作用域只能在括号{}内使用,因此它们不会相互影响
结果是
使用匿名结构体只有坏处,没有多余的好处,特别是在结构体的自引用中,自己写代码时不要用!
6.结构体的内存对齐
内存对齐的原因:有的硬件访问内存时,只能在特定内存处访问特定数据,如要取int类型数据只能在4的倍数的地址处读取,如果存的位置不是4的倍数,那么硬件要连续读取两次才能得到一个完整的int,这样大大降低了计算机的性能。因此,内存对齐本质上是用空间换取时间的做法。
对齐数:编译器默认的对齐数和要放入的一个成员变量的大小的较小值,因此每放入一个成员,对齐数都在不断地改变。Linux的gcc没有默认对齐数,对齐数就是变量自身的大小。
注意:如果有成员变量是数组,数组内每个元素的大小被当作成员变量的大小
如果有嵌套结构体,把该嵌套结构体中成员变量中最大对齐数当作该嵌套结构体的对齐数,嵌套结构体所占的大小可以单独挑出来计算,没有影响
偏移量(易混):用一种简单不混淆的话来说,放入成员变量时,截至要研究的地址处结构体占用的字节大小就是偏移量大小,在完全不放数据时,偏移量为0,放入一个char的数据后,char末尾处偏移量为1,但称这个char放在0偏移处,因为char的起始位置位于偏移量为0的位置。后续描述方法同理
可用offsetof检验,offsetof返回的是当前变量起始位置处的偏移量,要包含<stddef.h>
#include <stdio.h>
#include <stddef.h>
struct S1
{
char a;
char c[3];
int b;
};
int main()
{
printf("%zd\n", offsetof(struct S1, a));
printf("%zd\n", offsetof(struct S1, c[3]));
printf("%zd\n", offsetof(struct S1, c));
printf("%zd\n", offsetof(struct S1, b));
return 0;
}
结果是

注意c和c[3]不同,c[3]字面上已经越界了,但它实际上不会去访问的,这种表示形式也可用于sizeof(但原因不同)。c[3]的首地址表示为c[2]的末地址,可以看到在c[2]放完后,偏移量就是4,和我们之前的说法相吻合。
对齐规则:每个成员从相应对齐数的整数倍的偏移量处开始放,结构体总大小为每个成员变量中最大对齐数的整数倍,注意结构体,数组的对齐数
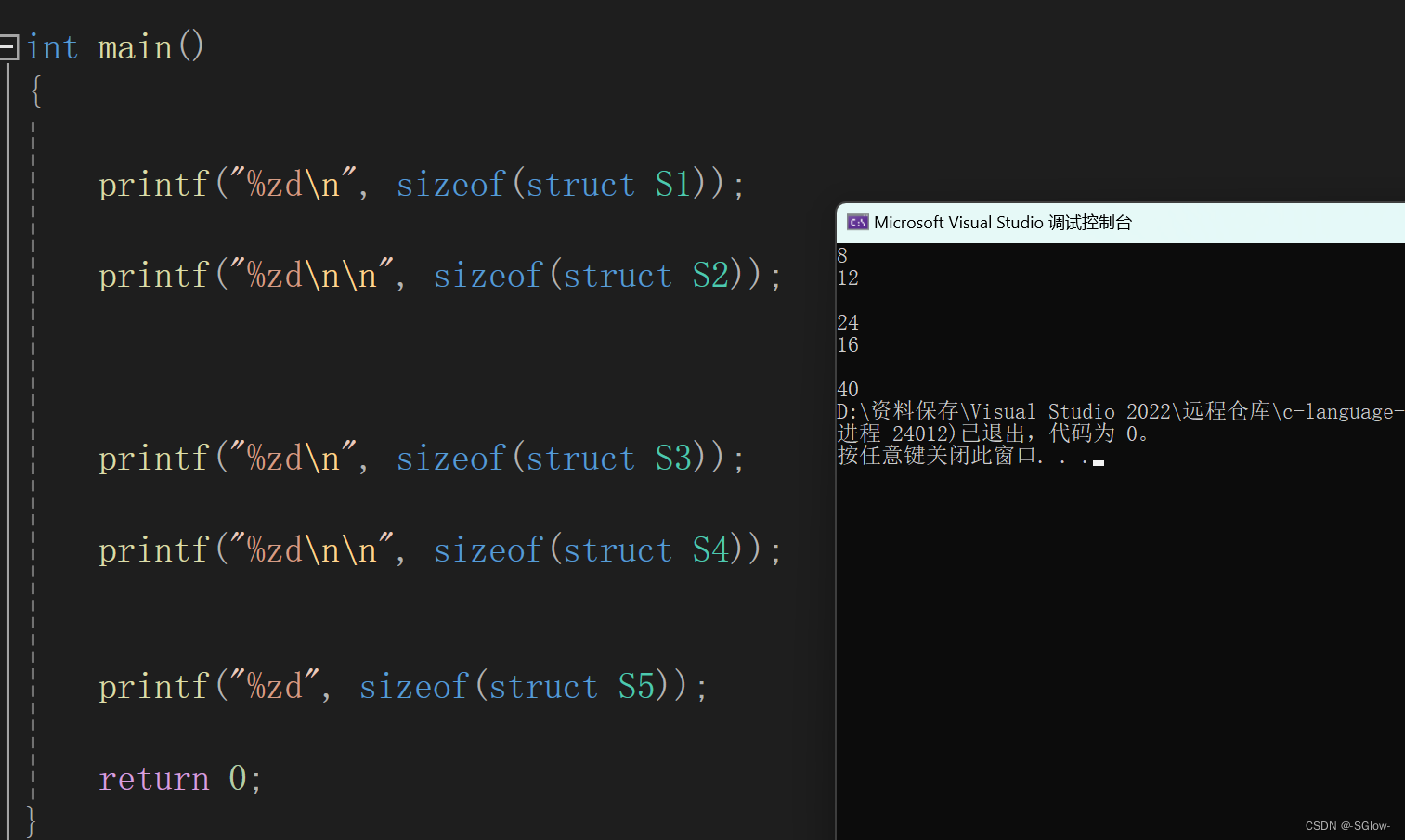
尝试解释下面的代码
#include <stdio.h>
struct S1
{
char a;
char c[3];
int b;
};
struct S2
{
char a;
int b;
char c[3];
};
struct S3
{
char a;
double c;
int b;
};
struct S4
{
char a;
int b;
double c;
};
struct S5
{
char a;
struct S4 c;
char b[15];
};
int main()
{
printf("%zd\n", sizeof(struct S1));
printf("%zd\n\n", sizeof(struct S2));
printf("%zd\n", sizeof(struct S3));
printf("%zd\n\n", sizeof(struct S4));
printf("%zd", sizeof(struct S5));
return 0;
}
结果是
7.结构体与链表的简单应用
结构体作为一个整体,内部可以存放不同的数据,表示不同含义。其中,如果我们在结构体中自引用,放入一个自己类型的指针变量,我们就可以在需要的条件下,由一个结构体从而访问到其它结构体,这一过程像是用链子将这些结构体连接起来,所以在数据结构里这些又叫做链表。这里就给出一种简单的应用,在以后写代码时,可以尝试使用。
#include <stdio.h>
struct num
{
int i;
struct num* next;
};
int main()
{
struct num s1 = { 1 };//不完全初始化
struct num s2 = { 2 };
struct num s3 = { 3 };
struct num s4 = { 4 };
struct num s5 = { 5 };
s1.next = &s3;
s2.next = &s5;
s3.next = &s2;
s4.next = &s1;
s5.next = &s4;
printf("%d\n", s1.next->i);
printf("%d\n", s2.next->i);
printf("%d\n", s3.next->i);
printf("%d\n", s4.next->i);
printf("%d\n\n", s5.next->i);
printf("%d\n", s1.next->next->i);//1->3->2
printf("%d\n", s1.next->next->next->next->next->i);//1->3->2->5->4->1
return 0;
}我们打印结果验证一下

注意:自引用需要在结构体中创建一个自类型的指针变量,而不是直接内部创建一个自类型的结构体。
8.enum枚举变量
枚举变量相当于更加实用的define,在C语言易错概念(1)中我就提过define不是C语言关键字,它是在编译过程中由编译器实现的,我们也知道C语言是要经过编译和链接才能生成可执行程序,所以define和我们在C语言中写出的enum有本质上的区别,下面展示它的用法
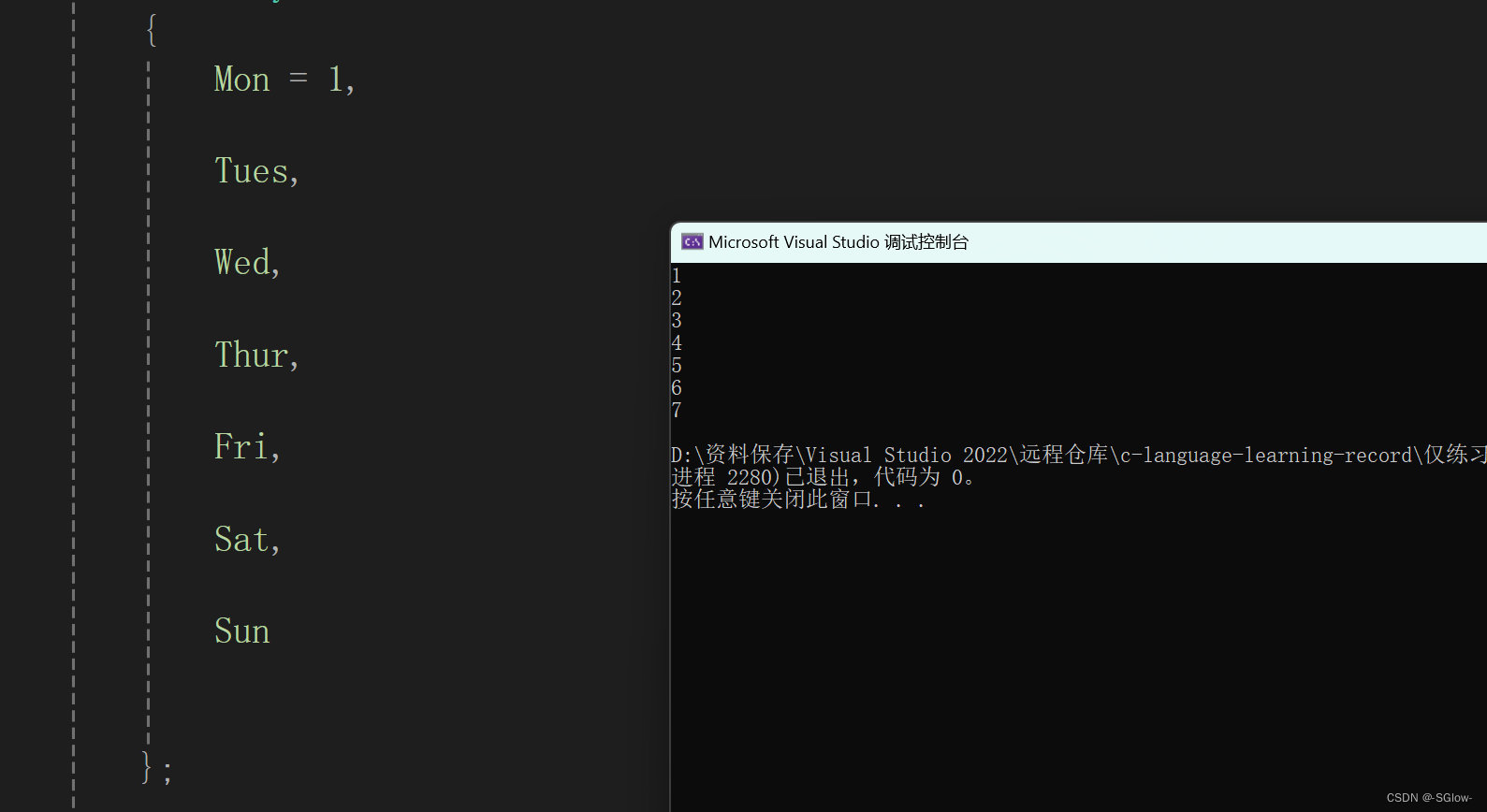
#include <stdio.h>
int main()
{
int j = 0;
if (1)
{
enum Day
{
Mon = 1,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int i = 0;
i = Mon;
printf("%d\n", i);
printf("%d\n", Tues);
printf("%d\n", Wed);
printf("%d\n", Thur);
printf("%d\n", Fri);
printf("%d\n", Sat);
printf("%d\n", Sun);
}
//j = Mon;//err
return 0;
}结果是
(1)enum创建的变量相当于常量,只能在enum中对它初始化,后续不能对它进行修改
(2)enum不初始化默认从0开始赋值
(3)enum存在作用域,所以要注意适用范围,当然我们可以利用这一点,这就是define做不到的了
9.栈区和堆区、静态区在管理内存上的区别
栈区用于创建临时变量,函数等。在进入作用域时会开辟栈帧,出作用域会被销毁,因此这会导致野指针问题,需要我们多加注意。一般来说不要在函数里返回栈空间的变量的地址。
对于堆区而言,由malloc、calloc、realloc开辟的空间除非通过free释放,否则只有在程序结束时才会被收回,由malloc、calloc、realloc开辟的空间在作用域外并不会被销毁。因此我们要注意内存泄漏问题,堆区开辟的空间一定要用指针接收并且要保存。
静态区上全局变量可以被任意访问,它和静态变量一样都存储在静态区,生命周期是整个程序的周期,但是要注意全局变量可以被修改,我们写代码时要防止全局变量被误改
#include <stdio.h>
int i = 10;
int main()
{
printf("%d\n", i);
{
i = 1;
printf("%d\n", i);
}
printf("%d\n", i);
return 0;
}
结果是
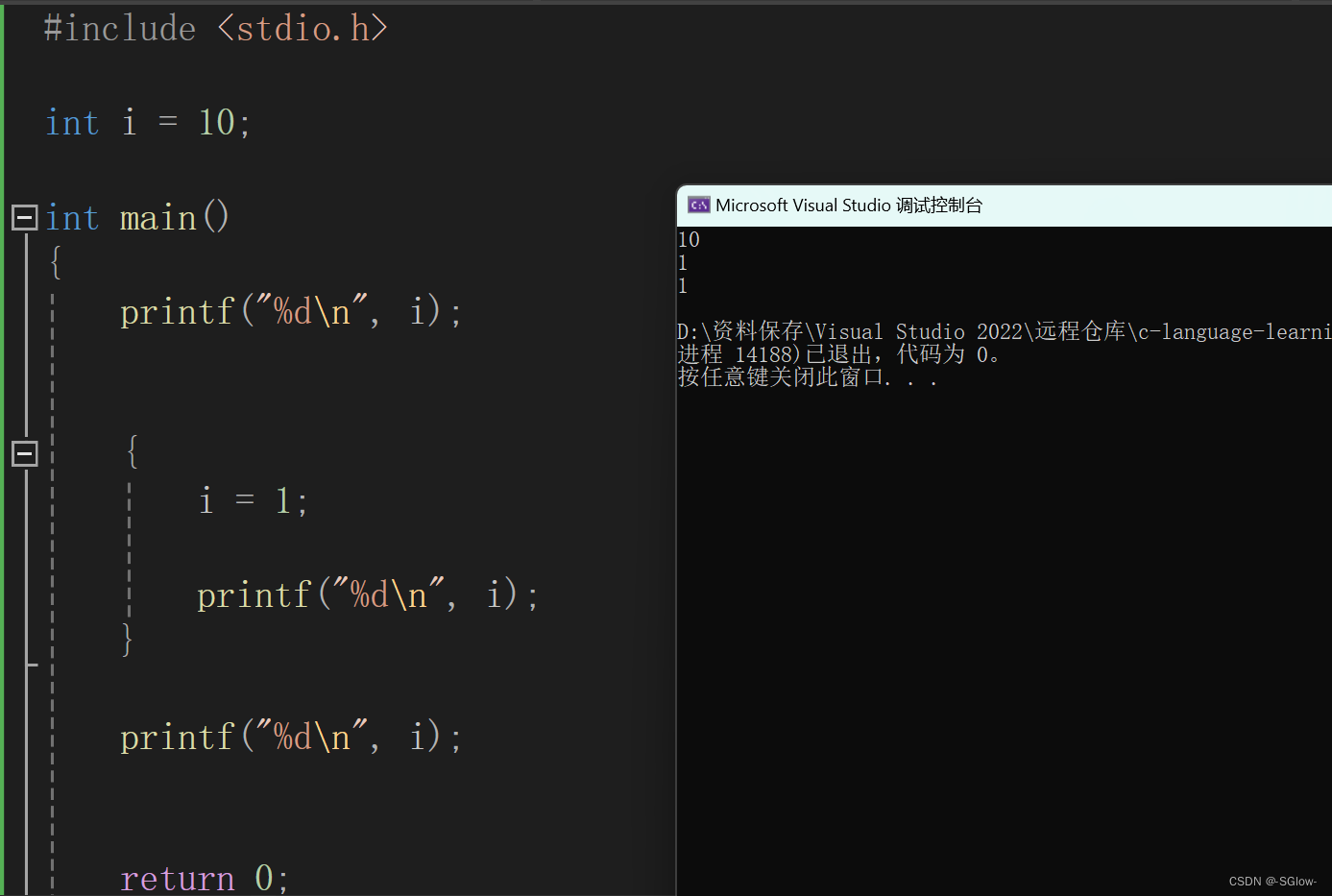
10.结构体实现位段
位段是一种优化内存的比较好的方法,其中指定的内存大小不应大于类型所对应的bit,即int最多分配32。位段分配原则没有统一规定,因此要根据不同编译器来选择不同的代码书写方式。
#include <stdio.h>
struct A
{
int i : 1;
unsigned int j : 1;
int m : 8;
unsigned int n : 8;
};
int main()
{
int b = 0;
int c = 0;
struct A a = { 0 };
scanf("%d", &b);
a.i = b;
a.j = b;
a.m = b;
a.n = b;
printf("%d %d %d %d\n", a.i, a.j, a.m, a.n);
printf("结构体的大小是:%d", sizeof(struct A));
return 0;
}
运行结果是
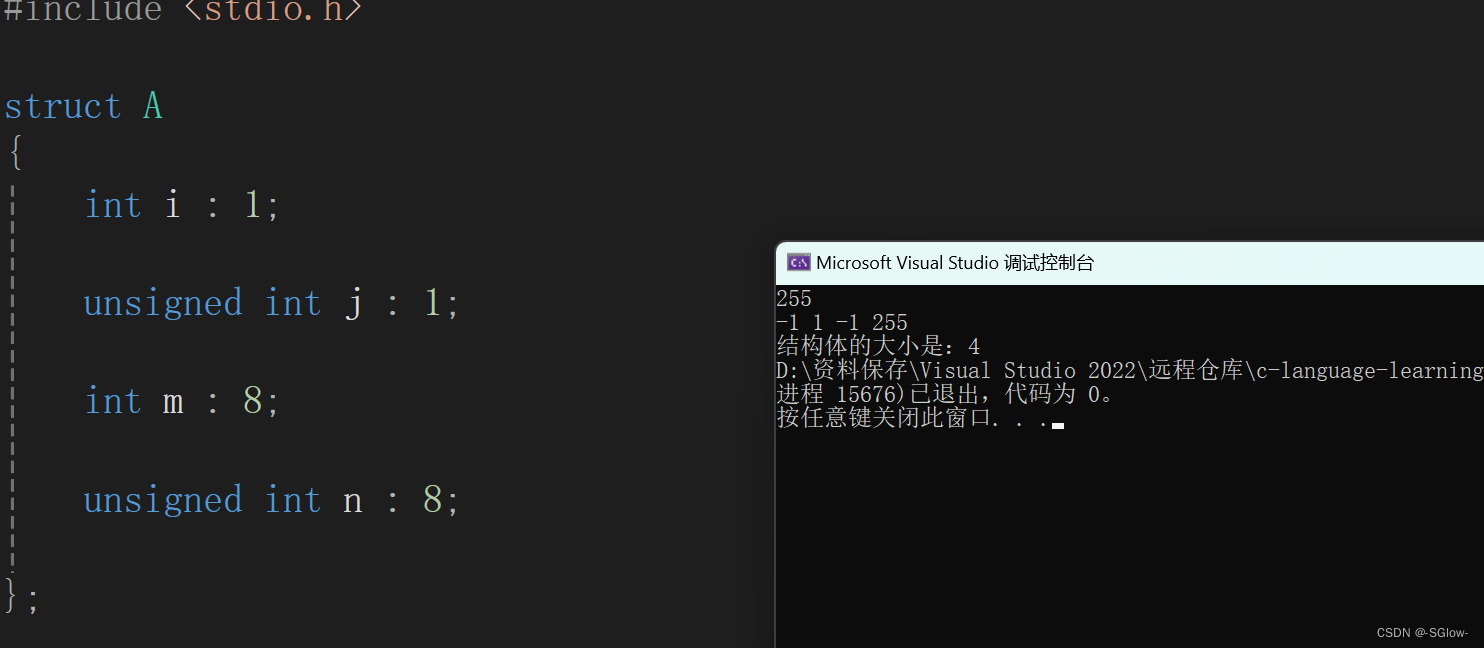
注意:结构体位段的成员分有符号和无符号,同时位段的成员不能直接取地址,因为地址是按字节来分配的,而不是比特位。应先用一个变量接收,再用访问结构体的方式进行赋值。
位段成员在内存中的存储方式不一样,以VS为例讲解:
先看以下代码
#include <stdio.h>
struct A
{
int i : 8;
int j : 24;
int m : 32;
char n : 1;
};
int main()
{
printf("结构体的大小是:%d", sizeof(struct A));//12
return 0;
}

先创建int i(32bit),(VS上)从右开始放8个bit的数据,int j : 24的大小是24bit,如果紧挨着放入i中刚好能放下,所以j的数据实际上放在了创建int i(32bit)的空间里,后面再存放m和n。
如果不能紧挨着放下数据,则会重新创建一个完整的int(根据实际情况)空间
注意:结构体大小也要是最大对齐数的整数倍(这里是4个字节)
下面尝试解释以下代码
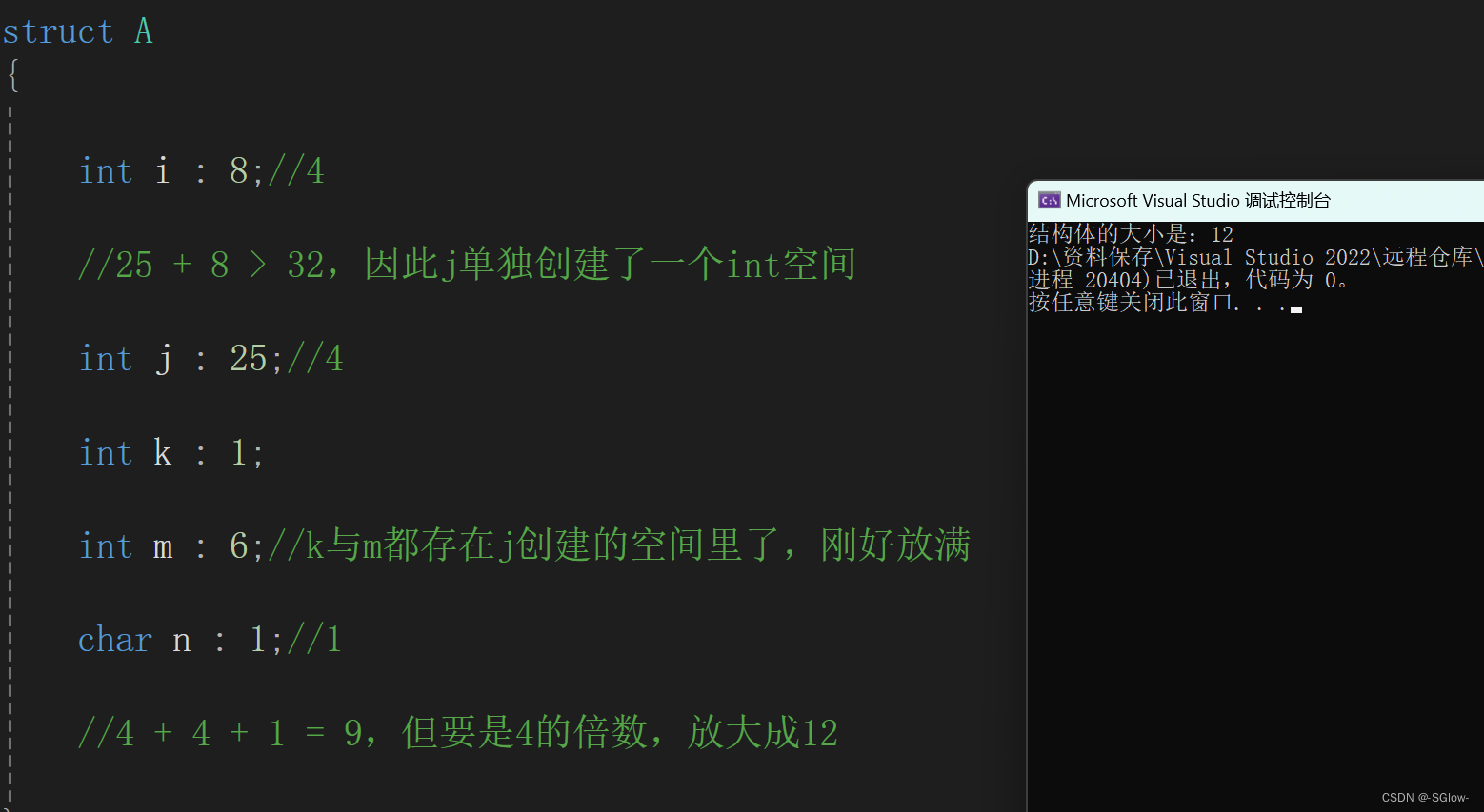
#include <stdio.h>
struct A
{
int i : 8;//4
//25 + 8 > 32,因此j单独创建了一个int空间
int j : 25;//4
int k : 1;
int m : 6;//k与m都存在j创建的空间里了,刚好放满
char n : 1;//1
//4 + 4 + 1 = 9,但要是4的倍数,放大成12
};
int main()
{
printf("结构体的大小是:%d", sizeof(struct A));
return 0;
}
验证结果
位段在网络传输运用广泛,可以多加了解















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









