






1、桶排序
核心思想如下,将每个桶对应一个数组元素,数组元素的下标等于桶的序号,数组元素的值等于桶中所装内容:

优点:常数时间就能完成元素的查询和赋值操作,时间复杂度为O(N)。
缺点:空间复杂度极高,不适合大规模计算。
2、冒泡排序
核心思想如下,每次比较两个相邻的元素,如果它们的顺序错误就把它们交换过来:
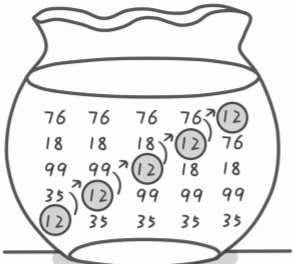
类似于图中的元素12,每次和相邻的元素进行比较,直到到达属于自己的位置。就像一个气泡一样一步一步向上走。
顾名思义---冒泡排序。
伪代码如下:
for(int i=1;i<=n-1;i++) //仅需要N-1次计算就能排好序
for(int j=1;j<=n-i;i++) //每次比较相邻两个数
if(a[j]>a[j+1]){
swap(a[j],a[j+1])
}
优点:算法简单,容易理解。
缺点:时间复杂度极高,为O(N^2)。
3、快速排序
由图灵奖获得者东尼.霍尔于1960提出。
核心思想如下,抓住三个核心:基准数、左、右探测器、二分法,每次将一个元素归位。

这个图对于理解这个算法实在是太好啦,举个例子来阐述一下这个算法:
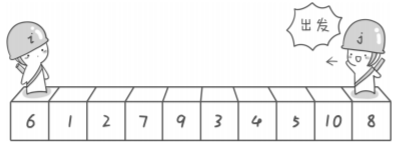
First step
对于序列6 1 2 7 9 3 4 5 10 8,假设以最左边数为基准数,左探测器i的初始位置在最左边,右探测器j的初始位置在最右边。
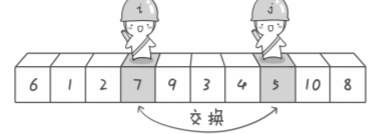
The second
右探测j首先寻找比基准数小的数,找到后停下,然后左探测器i寻找比基准数大的数,找到后停下。如果i != j,交换两个位置的元素。
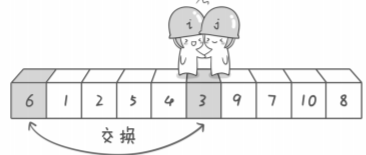
The third
如果两个探测器相遇,则交换基准数和相遇位置i所在元素。
The last
根据二分的思想在分段的序列两边重复以上步骤即可。
附代码如下:
# include <iostream>
using namespace std;
int a[101],n;
void quicksort(int left ,int right){
int i=left;
int j=right;
int temp=a[left];
if(i>=j){
return ;
}
while(i!=j){
while(a[j]>=temp&&j>i) //此处要注意寻找小于基准数应该用>=
j--;
while(a[i]<=temp&&j>i)
i++;
if(j>i){
int xx=a[j];
a[j]=a[i];
a[i]=xx;
}
}
a[left]=a[j];
a[j]=temp;
quicksort(left,j-1); //在序列两边重复以上步骤
quicksort(j+1,right);
}
int main(){
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
quicksort(1,n);
for(int i=1;i<=n;i++){
cout<<a[i]<<" ";
}
return 0;
}
样例:6 1 2 7 9 3 4 5 10 8
输出:1 2 3 4 5 6 7 8 9 10
优点:时间复杂度低,适用于大规模计算,是一个比较实用的排序算法。时间复杂度在最差情况下为O(N^2),一般为O(N*log(N))。
4、堆排序算法
本算法由J.W.J.Williams在1964年发明,本算法的核心是在建堆上,RobertW.Floyd在同年提出了建立堆的线性时间算法。
核心思想如下,抓住三个核心:元素插入与删除、向上调整、向下调整。
建立堆:
向上调整: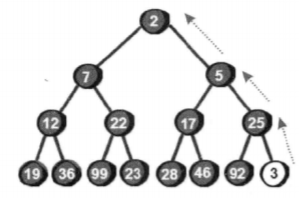
向下调整: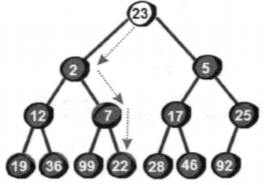
本算法利用了二叉树的特性:每个子节点的序号除以2等于父亲节点的序号,父节点的两个子节点分别等于父节点序号乘以2和乘以2加1。
附代码如下:
# include <iostream>
# include <cstring>
# include <string.h>
# include <iomanip>
using namespace std;
int n;
int a[101];
void swap(int x,int y){ //交换两个元素
int xx=a[x];
a[x]=a[y];
a[y]=xx;
}
void shiftdown(int i){ //向下调整,此处的i就是节点编号
int t,flag=0;
while(i*2<=n&&flag==0){
if(a[i]>a[i*2]){
t=2*i;
}
else
t=i;
if(i*2+1<=n&&a[t]>a[i*2+1]){
t=2*i+1;
}
if(t!=i)
swap(i,t);
else
flag=1;
i=t;
}
}
void shiftup(int i){ //向上调整
int t,flag=0;
if(i==1)
return ;
while(i!=1&&flag==0){
if(i==1)
return ;
if(i/2>=1){
if(a[i]<a[i/2])
t=i/2;
else
t=i;
}
if(i!=t)
swap(i,t);
else
flag=1;
i=t;
}
}
int main(){
freopen("最小堆.txt","r",stdin);
cin>>n;
int l=n;
for(int i=1;i<=n;i++){
cin>>a[i];
shiftup(i);
}
// for(int i=n/2;i>=1;i--)
// shiftdown(i);
cout<<endl;
while(n>=1){
cout<<a[1]<<endl;
a[1]=a[n];
shiftdown(1);
n--;
}
return 0;
} 堆排序算法的神奇之处在于,假设有1亿个数,进行1亿次删除最小数并且增加一个数的操作,使用冒泡的方法需要大约1亿的平方次,而堆排序只需要1亿*log(1亿次)即27亿次数就可以完成,以计算机每秒10亿次的计算量来算,使用堆排序仅仅需要2.7s就可以完成计算,而原来的方法需要115天才能完成计算,由此可见算法的奇妙之处。
参考书籍--《啊哈算法》、《图论算法理论、实现及应用》















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









