







 本文详细阐述了Doris存储引擎如何通过优化MemTable的写入、并行下刷机制,以及引入单副本导入功能来提升数据导入性能,特别是针对多副本导入场景,性能提升可达2-8倍。
本文详细阐述了Doris存储引擎如何通过优化MemTable的写入、并行下刷机制,以及引入单副本导入功能来提升数据导入性能,特别是针对多副本导入场景,性能提升可达2-8倍。
目录
一、概述
为提供快速的数据写入支持,Doris存储引擎采用了类LSM Tree结构。在进行数据导入时,数据会先写入Tablet对应的MemTable中,MemTable采用SkipList的数据结构,当MemTable写满之后,会将其中的数据刷写(Flush)到磁盘。数据从MemTable刷写到磁盘的过程中分为两个阶段,第一个阶段将MemTable中的行存结构在内存中转换成列存结构,并为每一列生成对应的索引结构;第二阶段是将转换后的列存结构写入磁盘,生成Segment文件。
具体而言,Doris在导入流程中会把BE模块分为上游和下游,上游BE对数据的处理分为Scan和Sink两个步骤:首先Scan过程对原始数据进行解析,然后Sink过程将数据组织并通过RPC分发给下游BE。当下游BE接受数据后,首先在内存结构MemTable中进行数据攒批,对数据进行排序、聚合、并最终下刷成数据文件(也称作Segment文件)到磁盘上来进行持久化存储。
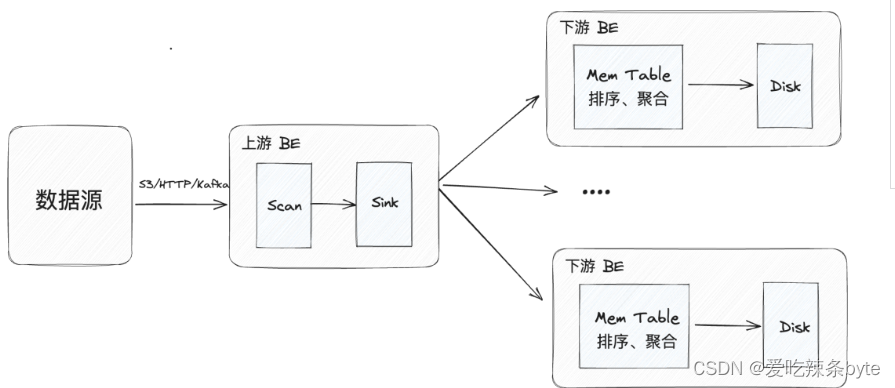
在实际的数据导入过程中,可能会出现以下问题:
- 因上游 BE 跟下游 BE 之间的 RPC 采用 Ping-Pong 的模式,即下游 BE 一个请求处理完成并回复到上游 BE 后,上游 BE 才会发送下一个请求。如果下游 BE 在 MemTable 的处理过程中消耗了较长的时间,那么上游 BE 将会等待 RPC 返回的时间也会变长,这就会影响到数据传输的效率。
-
当对多副本的表导入数据时,需要在每个Tablet副本上重复执行MemTable的处理过程。然而,这种方式使每个Tablet副本所在节点都会消耗一定的内存和 CPU 资源,不仅如此,冗长的处理流程也会影响执行效率。
为解决以上问题,为进一步提高数据导入性能,Doris-2.0版本对导入过程中MemTable的攒批、排序和落盘等流程进行优化,来提高上下游之间数据传输的效率。此外还提供了“单副本导入”的数据分发模式,面对Tablet多副本数据导入时,无需在多个BE上重复进行MemTable工作,有效提升集群计算和内存资源的利用率,进行提升导入的总吞吐量。数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。
二、MemTable 优化
2.1 写入优化
在 Doris 过去版本中,下游 BE在写入 MemTable 时,为了维护 Key 的顺序,会实时对 SkipList 进行更新。对于 Unique Key 表或者 Aggregate Key 表来说,遇到已经存在的 Key 时,将会调用聚合函数并进行合并。然而这两个步骤可能会消耗较多的处理时间,从而延迟 RPC 响应时间,影响数据写入的效率。
在 2.0 版本中对这一过程进行了优化。当下游 BE 在写入 MemTable 时,不再实时维护 MemTable中Key的顺序,而是将顺序的保证推迟到MemTable即将被下刷成 Segment 之前(Flush磁盘前,统一排序)。①
2.2 并行下刷
在导入过程中,当下游BE将一个 MemTable 写入一定大小之后(得到一定阈值,默认是100M),会把 MemTable下刷为Segment数据文件来持久化存储数据并释放内存。为了保证前文提到的 Ping-Pong RPC 性能不受影响,MemTable 的下刷操作会被提交到一个线程池中进行异步执行。
在 Doris 过去版本中,对于Unique Key模型的表来说,MemTable下刷任务是串行执行的,原因是不同 Segment 文件之间可能存在重复 Key,串行执行可以保持它们的先后顺序,而 Segment 序号是在下刷任务被调度执行时分配的。同时,在数据分片Tablet 数量较少无法提供足够的并发时,串行下刷可能会导致系统的 IO 资源无法重复被利用。
在Doris 2.0 版本中,由于我们将 Key 的排序和聚合操作进行了后置(文章中的①),除了原有的 IO 负载以外,下刷任务中还增加了 CPU 负载(即后置的排序和聚合操作)。此时若仍使用串行下刷的方式,没有足够多 Tablet分片来保证并发数时,CPU 和 IO会交替成为瓶颈,从而导致下刷任务的吞吐量大幅降低。
为解决上述问题,在下刷任务提交时就为其分配 Segment 序号,确保并行下刷生成的 Segment文件顺序依旧是正确的。此外,还对Rowset 构建流程进行了优化,使其可以处理不连续的 Segment 序号。通过以上改进,使得所有类型的表都可以并行下刷 MemTable,从而提高IO资源利用率和导入吞吐量。
2.3 优化效果
MemTable优化不仅适用于Stream Load ,还对Doris支持的其他导入方式同样有效,例如 Insert Into、Broker Load等,均在不同程度提升了导入的总吞吐量。
三、单副本导入优化
3.1 原理和实现
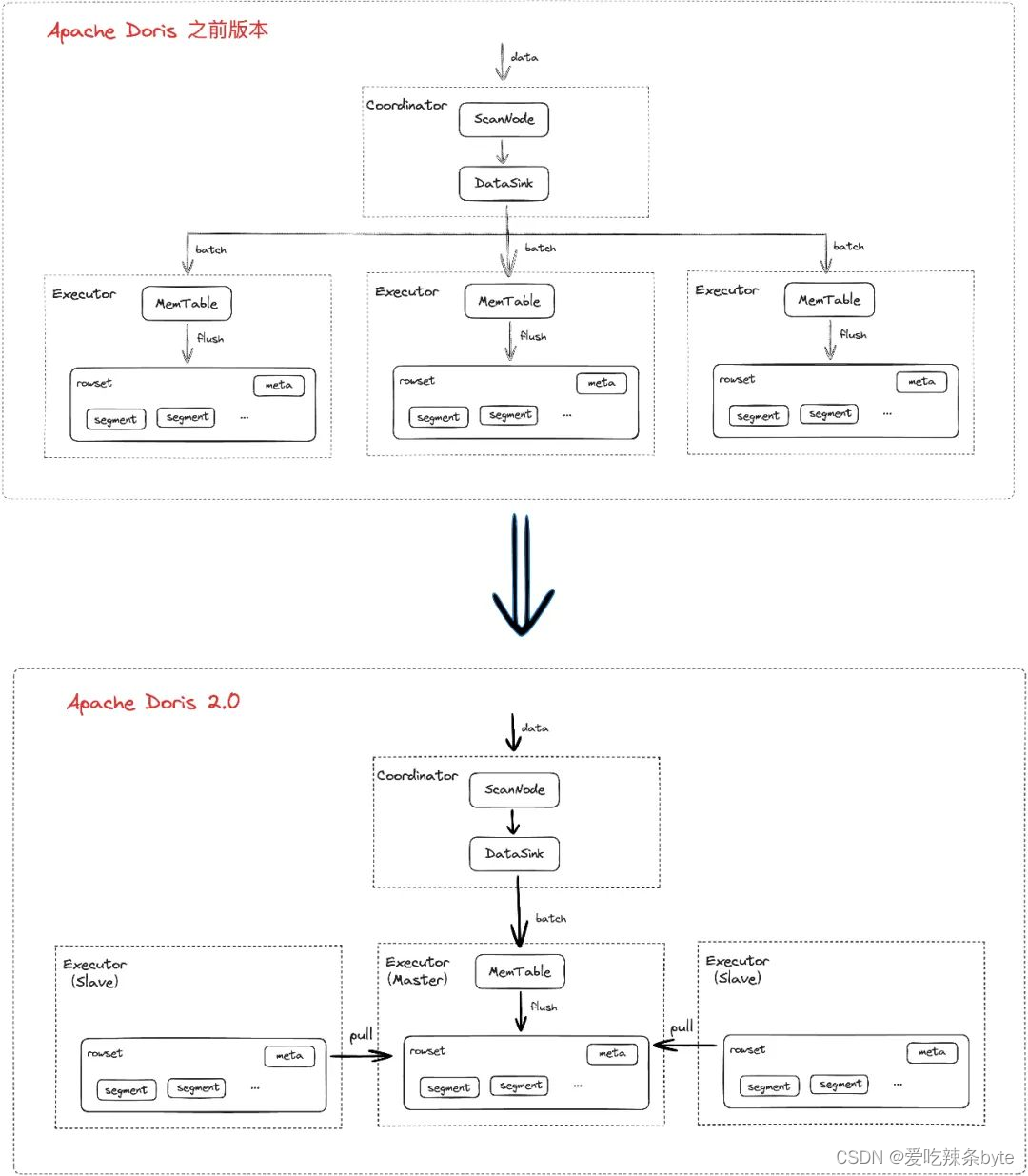
在之前版本中,当面对多副本Tablet数据写入时,Doris 的每个Tablet数据副本均需要在各自节点上进行排序和压缩,这样会造成较大的资源占用。为了节约 CPU 和内存资源, Doris 2.0 版本中提供了单副本导入的能力,该能力会从多个副本中选择一个副本作为主副本(其他副本为从副本),且只对主副本进行计算,当主副本的数据文件都写入成功后,通知从副本所在节点直接拉取主副本的数据文件,实现副本间的数据同步,当所有从副本节点拉取完后进行返回或超时返回(大多数副本成功即返回成功)。
单副本导入能力无需一一在节点上进行处理,减少了节点的压力,而节约的算力和内存将会用于其它任务的处理,从而提升整体系统的并发吞吐能力。
3.2 如何开启
FE 配置:enable_single_replica_load = true
BE 配置:enable_single_replica_load = true
环境变量(insert into): set experimental_enable_single_replica_insert = true;
3.3 优化效果
3.3.1 单并发导入
对于对于单并发导入任务,单副本数据导入能力可以有效降低资源消耗。单副本导入所占的内存仅为三副本导入的 1/3(单副本导入时只需要写一份内存,三副本导入时需要写三份内存)。同时从实际测试可知,单副本导入的 CPU 消耗约为三副本导入的 1/2,可有效节约 CPU 资源。
3.3.2 多并发导入
对于对于多并发导入任务,在相同的资源消耗下,单副本导入能力可以显著增加任务吞吐。同时在实际测试中,同样的并发导入任务, 三副本导入方式耗时 67 分钟,而单副本导入方式仅耗时 27 分钟,导入效率提升约 2.5 倍。
参看文章:
Apache Doris 2.0 如何实现导入性能提升 2-8 倍

















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









