






因为Doris这个框架越来越火,行业内已经成为了必不可少的框架,面试当然也是重点考察。
Doris性能优化不要慌,分为几个部分掌握回答就好了。
关于Doris的优化是一个很大的课题,我们可以从几个方面进行回答。例如:导入、查询、Join优化等等。
我们起一个小的系列,专门回答这个问题。
我们先从Join优化说起。
一、Doris数据划分
在介绍Doris中多种Join方式及优化原理之前,先回顾下Doris的数据划分及tablet多副本机制。
Doris 支持两层的数据划分,第一层是Range Partition,第二层是Hash Bucket(Tablet)。
Doris的数据表按照分区分桶规则,被水平切分成若干个数据分片(Tablet,也称作数据分桶 Bucket)存储在不同的be节点上,每个tablet都有多个副本(默认是3副本)。
各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。Tablet 是数据移动、复制等操作的最小物理存储单元。
下图说明 Table、Partition、Bucket(Tablet) 的关系:
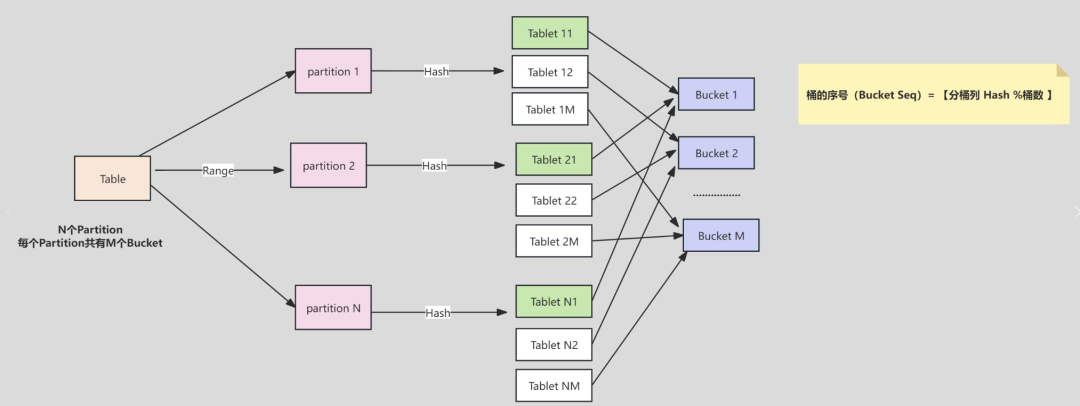
假设Table按照 Range的方式按照date字段进行分区,得到了 N 个 Partition
每个 Partition 通过相同的 Hash 方式将其中的数据划分为 M 个 Bucket(Tablet)
从逻辑上来说,Bucket 1 可以包含 N 个 Partition 中划分得到的数据,比如下图中的 Tablet 11、Tablet 21、Tablet N1
分区
逻辑概念,分区用于将数据划分成不同的区间,主要作用是将一张表按照分区键拆分成不同的管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
分桶
物理概念,Doris一般采用Hash算法作为分桶算法。在同一分区内,分桶键哈希值相同的数据会划分到同一个tablet(数据分片),tablet以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位,数据导入和查询最终都下沉到所涉及的tablet副本上。
二、Join方式
2.1 总览
作为分布式的MPP数据库,在Join的过程中是需要进行数据的Shuffle,数据需要拆分调度,才能保证最终的Join结果是正确的。
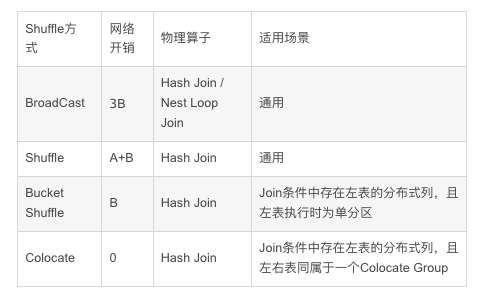
目前Doris支持的Join方式有 Broadcast Join、Shuffle Join、Bucket Shuffle Join 和Colocate Join 这4种,这4种方式灵活度和适用性是从高到低的,对数据分布的要求越来越严,但Join计算的性能则通过降低网络开销而越来越好。
Join 方式的选择是FE生成分布式计划阶段会考虑的事项之一。在 FE 进行分布式计划时,优先选择的顺序为:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。很明显,Colocate 以及 Bucket Shuffle 是可遇不可求的。当无法使用它们时,Doris会自动尝试进行 Broadcast Join(大表join 小表),如果预估小表过大则会自动切换至 Shuffle Join。
但是用户也可以通过显式 Hint来强制使用期望的Join类型,比如:
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2;2.2 Broadcast Join
SELECT * FROM A,B WHERE A.column=B.column通过将B表的数据全量广播到A表的机器上,在A表的机器上进行Join操作,相比较于Shuffle join 节省了A表数据Shuffle,但是B表的数据是全量广播,适合B表是个小表的场景。
如下图,根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是3B,它的内存开销也是3B。
2.3 Shuffle Join
SELECT * FROM A,B WHERE A.column=B.columnShuffle Join是根据表A和表B执行join的列进行hash,相同hash值的数据分发到同一个节点上。它的网络开销是A+B,内存开销是B。
2.4 Bucket Shuffle Join
SELECT * FROM A,B WHERE A.distributekey=B.anycolumn基于上面Broadcast Join、 Shuffle Join网络传输开销的痛点,Doris引入了更好的操作:Bucket shuffle join。Bucket Shuffle Join是在Broadcast的基础上进一步优化,将B表按照A表的分布方式,Shuffle到A表机器上进行Join操作,B表Shuffle的数据量全局只有一份,比Broadcast少传输了很多倍数量。所以它的网络开销是B,内存开销是B。
Doris 的表数据本身是通过 Hash 计算分桶的,假如两张表需要做 Join,并且 Join 列是左表的分桶列,那么左表的数据不用移动,B表按照A表的分布方式,Shuffle到A表机器上进行Join操作,B表Shuffle的数据量全局只有一份,比Broadcast少传输了很多倍数量。它的网络开销是B,内存开销是B。Bucket Shuffle Join 通过对左表实现本地性计算优化,来减少左表数据在节点间的传输耗时,从而加速查询。
2.5 Colocation Join
SELECT* FROM A,B WHERE A.colocatecolumn=B.collocatecolumn它与Bucket Shuffle Join相似,通过建表时指定 A 表和B表是同一个 Colocate Group,确保 A、B 表的数据分布完全一致,那么,计算节点只需做本地 Join,减少跨节点的数据移动和网络传输开销,提高查询性能。Colocate Join 十分适合几张大表按照相同字段分桶的场景,这样可以将数据预先存储到相同的分桶中,实现本地计算。所以它的网络开销是0,数据已经预先分区,直接在本地进行Join 计算。
2.6 四种 Shuffle 方式对比
Runtime Filter优化
3.1 Runtime Filter概述
除了通过索引来加速过滤查询的数据,Doris中还额外加入了动态过滤机制,即 Runtime Filter。
在多表关联查询时,我们通常将右表称为 BuildTable、左表称为 ProbeTable,左表的数据量会大于右表的数据。在实现上,会首先读取右表的数据,在内存中构建一个 HashTable(Build)。之后开始读取左表的每一行数据,并在 HashTable 中进行连接匹配,来返回符合连接条件的数据(Probe)。
而 Runtime Filter 是在右表构建 HashTable 的同时,为连接列生成一个过滤结构,可以是 Min/Max、IN 等过滤条件。之后把这个过滤列结构下推给左表。 这样一来,左表就可以利用这个过滤结构,对数据进行过滤,从而减少 Probe 节点(左表)需要传输和比对的数据量。
在大多数 Join 场景中,Runtime Filter 可以实现节点的自动穿透,将 Filter 穿透下推到最底层的扫描节点或者分布式 Shuffle Join 中。大多数的关联查询 Runtime Filter 都可以起到大幅减少数据读取的效果,从而加速整个查询的速度。
3.2 Runtime Filter Join 原理
Doris 在进行 Hash Join 计算时会在右表构建一个 Hash Table,左表流式地通过右表的 Hash Table 从而得出 Join 结果。而 Runtime Filter 就是充分利用了右表的 Hash Table 构建阶段去做一些额外的事情。
在右表生成 Hash Table的时候,同时生成一个基于Hash Table数据的一个过滤条件,然后下推到左表的数据扫描节点。通过这样的方式,Doris可以在运行时进行数据过滤。
假如左表是一张大表,右表是一张小表,那么利用下推到左表的过滤条件就可以把绝大多数 Join 层要过滤的数据在数据读取时就提前过滤,从而大幅度地提升Join查询的性能。
3.3 Runtime Filter 类型
3.3.1 IN
将一个 hashset 下推到数据扫描节点。
优点:过滤效果明显,且快速。
缺点:只适用于 BroadCast;如果右表超过一定数据量时就失效了,当前 Doris目前配置的是1024,即右表如果大于1024,IN 的 Runtime Filter 就直接失效了。
3.3.2 Bloom Filter
利用哈希表的数据构造一个 BloomFilter,然后把这个 BloomFilter 下推到查询数据的扫描节点。
优点:通用,适用于各种类型、效果也比较好。
缺点:配置比较复杂并且计算较高。
3.3.3 MinMax
通过右表数据确定 Range 范围之后,下推给数据扫描节点。
优点:开销比较小
缺点:对数值列还有比较好的效果,但对于非数值列,基本上就没什么效果。
四、Join Reorder
4.1 Join Reorder概述
数据库一旦涉及到多表Join,Join的执行顺序对整个Join查询的性能是影响很大的。Join Reorder 用于推断多表 Join 的执行顺序,数据库需要尽可能地先执行一个高选择度的 Join,这样就能减少后续Join的输入数据,从而提升性能。
4.2 Join Reorder 算法
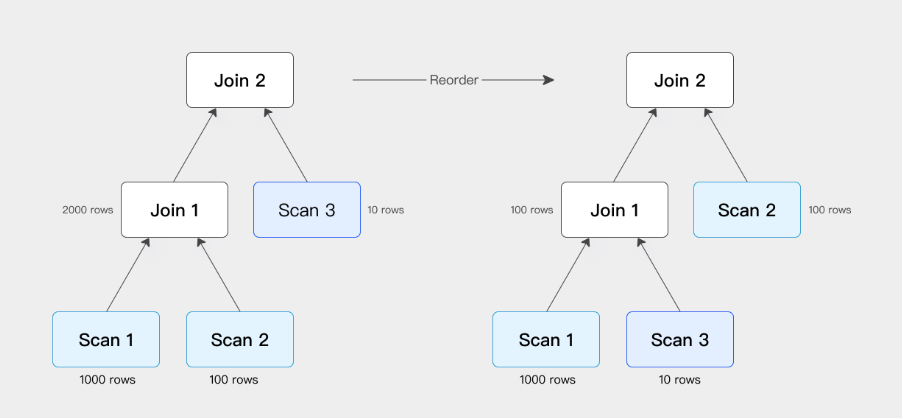
数据库一旦涉及到多表 Join,Join 的顺序对整个 Join 查询的性能是影响很大的。假设有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,然后与 c 表再进行 Join 计算。
接下来看图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。
Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是:
让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的。
五、Join 调优
5.1 Join 调优建议
Join 列最好是相同的简单类型;同类型避免 Cast 操作,简单类型则有不错的 Join 计算性能
Join 列最好是Key列,原因是Key列能够充分利用Doris延迟物化的特性,减少 IO 提升性能
大表之间的Join最好能够利用上Colocate,相当于已经做好了预 Shuffle,实际查询的时候可以直接进行本地Join 计算不再有Shuffle操作,彻底避免了大表的Shuffle网络开销和数据交换
合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著,根据 3 种 Runtime Filter 特点选择最适合的
涉及多表 Join,需要判断 Join 的合理性。尽量保证“左大右小”的原则,HashJoin 优于 NLJ(Nest Loop Join)。必要的时可以通过 SQL Rewrite,利用 Hint 去调整Join的顺序。
5.2 Join 调优方法
Doris Join官方给出了调优的方向性建议:
利用 Doris 本身提供的 Profile,去定位查询的瓶颈。Profile 会记录 Doris 整个查询当中各种信息,这是进行性能调优的一手资料。
了解 Doris 的 Join 机制,这也是第二部分跟大家分享的内容。知其然知其所以然、了解它的机制,才能分析它为什么比较慢。
利用 Session 变量去改变 Join 的一些行为,从而实现 Join 的调优。
查看 Query Plan 去分析这个调优是否生效。
上面的 4 步基本上完成了一个标准的 Join 调优流程,接着就是实际去查询验证它,看看效果到底怎么样。
如果前面 4 种方式串联起来之后,还是不奏效。这时候可能就需要去做 Join 语句的改写,或者是数据分布的调整、需要重新去 Recheck 整个数据分布是否合理,包括查询 Join 语句,可能需要做一些手动的调整。当然这种方式是心智成本是比较高的,也就是说要在尝试前面方式不奏效的情况下,才需要去做进一步的分析。
我们从具体开发的角度也可以这么做:
Join 列最好是相同的简单类型;同类型避免 Cast 操作,简单类型则有不错的 Join 计算性能;
Join 列最好是 Key 列,原因是 Key 列能够充分利用 Doris 延迟物化的特性,减少 IO 提升性能;
大表之间的 Join 最好能够利用上 Colocate,相当于已经做好了预 Shuffle,实际查询的时候可以直接 Join 计算不再有 Shuffle 操作,彻底避免了大表的 Shuffle 网络开销;
利用 Runtime Filter,Join 过滤性高时效果显著。根据 3 种 Runtime Filter 特点选择最适合的;
涉及多表 Join,需要判断 Join 的合理性。尽量保证“左大右小”的原则,HashJoin 优于 NLJ。必要时可以通过 SQL Rewrite,通过 Hint 来调整 Join 顺序。

如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











