







1. 介绍
当进行tb1 join tb2时,tb2的数据非常小,将tb2数据经过计算得到一个过滤条件,发送到tb1所在的节点,利用索引的功能,直接对tb1的数据进行过滤。来减少扫描的数据量,避免不必要的I/O 和网络传输,从而加速查询
2. 原理
Runtime Filter在查询规划时生成,在HashJoinNode中构建,在ScanNode中应用
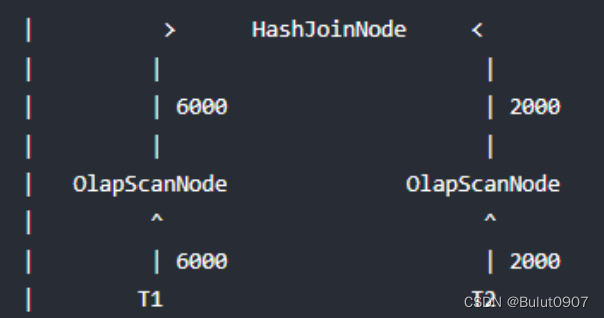
T1表的数据很大,比如100万条。等T2将扫描的数据记录交给HashJoinNode后,HashJoinNode根据T2的数据计算出一个过滤条件,然后将这个过滤条件发给T1的ScanNode,T1在储存引擎用索引对数据进行过滤,只需扫描6000条数据即可,T1再将数据返回给HashJoinNode
Runtime Filter是在运行时动态生成的过滤条件,即在查询运行时解析join on clause确定过滤表达式,并将表达式广播给正在读取左表的ScanNode
主要应用于join左表为大标,右表为小表。如果左表的数据量太小,或者右表的数据量太大,则Runtime Filter可能不会取得预期效果
3. 使用
指定RuntimeFilter类型。根据两表的数据分布情况,选择一个或多个。可以为
数字(1, 2, 4, 8)或者相对应的字符串(IN, BLOOM_FILTER, MIN_MAX, IN_OR_BLOOM_FILTER),默认8(IN_OR_BLOOM_FILTER),使用多个时用逗号分隔,注意需要加引号,或者将任意多个类型的数字相加
mysql> set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
Query OK, 0 rows affected (0.01 sec)
mysql>
查看执行计划
mysql> explain select * from click a join user_live b on a.user_id = b.user_id;
+------------------------------------------------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------------------------------------------------+
......省略部分......
| 2:VHASH JOIN |
| | join op: INNER JOIN(BROADCAST)[Tables are not in the same group] |
| | equal join conjunct: `a`.`user_id` = `b`.`user_id` |
| | runtime filters: RF000[in] <- `b`.`user_id`, RF001[bloom] <- `b`.`user_id`, RF002[min_max] <- `b`.`user_id` |
| | cardinality=0 |
| | vec output tuple id: 2 | |
| |----3:VEXCHANGE |
| | |
| 0:VOlapScanNode |
| TABLE: click(null), PREAGGREGATION: OFF. Reason: No AggregateInfo |
| runtime filters: RF000[in] -> `a`.`user_id`, RF001[bloom] -> `a`.`user_id`, RF002[min_max] -> `a`.`user_id` |
| partitions=0/2, tablets=0/0, tabletList= |
| cardinality=0, avgRowSize=56.0, numNodes=1
......省略部分......
+------------------------------------------------------------------------------------------------------------------------------+
33 rows in set (0.01 sec)
mysql>
生成了ID为RF000的IN predicate,其中b.user_id的key values仅在运行时可知,在VOlapScanNode使用了该IN predicate,用于在读取a.user_id时过滤不必要的数据
通过profile查看效果:
开启profile
mysql> show variables like '%enable_profile%';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| enable_profile | false |
+----------------+-------+
1 row in set (0.01 sec)
mysql>
mysql> set enable_profile=true;
Query OK, 0 rows affected (0.01 sec)
mysql>
再进行select的join查询,打开FE的Web界面,查看QueryProfile
在点击Query ID查看详细的信息。其中RuntimeFilter部分的信息如下:
RuntimeFilter:in:
- RealRuntimeFilterType: in
- AWaitTimeCost: 0ns
- EffectTimeCost: 19.709ms
RuntimeFilter:bloomfilter:
- AWaitTimeCost: 0ns
- EffectTimeCost: 19.699ms
RuntimeFilter:minmax:
- AWaitTimeCost: 0ns
- EffectTimeCost: 19.697ms
可以看到只要in这个Runtime Filter下推,其等待耗时为0、OLAP_SCAN_NODE 从prepare到接收到Runtime Filter的总时长为19.709ms
查看RuntimeFilter上面OlapScanner的RowsVectorPredFiltered和VectorPredEvalTime,可以查看Runtime Filter下推后的过滤效果和耗时
3. 参数说明
大多数情况下,只需要调整runtime_filter_type选项,其他选项保持默认即可
runtime_filter_type每个类型含义如下:
- Bloom Filter: 有一定的误判率而且开销较高,会导致过滤的数据比预期少一点,但不会导致最终结果不准确,在大部分情况下Bloom Filter都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。目前只有左表的Key列应用Bloom Filter才能下推到存储引擎
- MinMax Filter: 包含最大值和最小值,从而过滤小于最小值和大于最大值的数据。当join on clause中Key列的类型为varchar等时,应用MinMax Filter往往会导致性能降低
- IN predicate: 根据join on clause中Key列在右表上的所有值构建IN predicate,使用构建的IN predicate在左表上过滤,相比Bloom Filter构建和应用的开销更低。默认只有右表数据行数少于1024才会下推(可通过session变量中的runtime_filter_max_in_num调整)。当同时指定In predicate和其他 filter ,并且in 的过滤数值没达到runtime_filter_max_in_num时,会尝试把其他filter去除掉。因为已经够高效了
其他查询选项通常仅在某些特定场景下调整。通常只在性能测试后,针对资源密集型、运行耗时足够长且频率足够高的查询进行优化
- runtime_filter_mode: 用于调整Runtime Filter的下推策略,包括OFF、LOCAL、GLOBAL三种策略,默认设置为GLOBAL策略
- runtime_filter_wait_time_ms: 左表的ScanNode等待每个Runtime Filter的时间,默认1000ms
- runtime_filters_max_num: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10
- runtime_bloom_filter_min_size: Runtime Filter中Bloom Filter的最小长度,默认1048576(1M)
- runtime_bloom_filter_max_size: Runtime Filter中 Bloom Filter的最大长度,默认16777216(16M)
- runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2097152(2M)
- runtime_filter_max_in_num: 如果join右表数据行数大于这个值,我们将不生成 IN predicate,默认1024
4. 注意事项
下面摘自Doris官网,能明白个大概
- 只支持对join on clause中的等值条件生成Runtime Filter,不包括Null-safe条件,因为其可能会过滤掉join左表的null值
- 不支持将Runtime Filter下推到left outer、full outer、anti join的左表
- 不支持src expr或target expr是常量
- 不支持src expr和target expr相等
- 不支持src expr的类型等于HLL或者BITMAP
- 目前仅支持将Runtime Filter下推给OlapScanNode
- 不支持target expr包含NULL-checking表达式,比如coalesce/ifnull/case,因为当outer join上层其他join的join on clause包含NULL-checking表达式并生成Runtime Filter时,将这个Runtime Filter下推到outer join的左表时可能导致结果不正确
- 不支持target expr中的列无法在原始表中找到某个等价列
- 不支持列传导,这包含两种情况:
- 一是例如join on clause包含A.k = B.k and B.k = C.k时,目前C.k 只可以下推给B.k,而不可以下推给A.k
- 二是例如join on clause包含A.a + B.b = C.c,如果A.a可以列传导到B.a,即 A.a和B.a是等价的列,那么可以用B.a替换A.a,然后可以尝试将Runtime Filter下推给B(如果A.a和B.a不是等价列,则不能下推给B,因为target expr必须与唯一一个join左表绑定)
- Target expr和src expr的类型必须相等,因为Bloom Filter基于hash,若类型不等则会尝试将target expr的类型转换为src expr的类型
- 不支持PlanNode.Conjuncts生成的Runtime Filter下推,与HashJoinNode的eqJoinConjuncts和otherJoinConjuncts不同,PlanNode.Conjuncts生成的Runtime Filter在测试中发现可能会导致错误的结果,例如IN子查询转换为join时,自动生成的join on clause将保存在PlanNode.Conjuncts中,此时应用Runtime Filter可能会导致结果缺少一些行














 5695
5695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









