









目录
原文大佬写的这篇StarRocks实时数仓建设案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。如有侵权请告知~
前言
vivo需要基于移动终端的制造、物流、销售等各个方面的数据进行分析以满足业务决策。基于 Trino 的架构面临着数据时效、查询性能、并发能力、复杂运维等方面的瓶颈。
一、数据挑战
在数字化演进的过程中,vivo面临着业务诉求和技术架构方面的新挑战,主要包括时效性要求提升、访问量大、计算场景复杂和运维难等问题。vivo原有数据平台是基于Trino+Hive 的架构来实现,通过 Trino来抽取业务库里的数据(MySQL、Oracle、SQLserver 等),之后将抽取数据写入到Hive中,根据业务侧需求进行数仓的加工处理。
1.1 时效性挑战,业务分析决策需加速
基于Trino+Hive架构的小时级数据时效性已经无法满足业务需求,业务侧需要数仓架构能够实时抽取业务侧数据并加工,从而实现上层报表的实时呈现,以便更好地支持相关的决策分析。

1.2 访问量挑战,性能与稳定性亟待提高,支撑业务稳定运行
随着业务规模向全球发展,vivo 的分销代理系统覆盖用户量级飞速增长,营销、计价、订单、库存等业务系统均需要实时数据来保证销售业务精准稳定运营,这使得原有数仓架构的访问量持续增长,同时随着各种大数据分析相关新业务的上线, Trino 负载越来越高,逐渐无法满足访问量持续增长带来的查询压力。

1.3 计算场景挑战,难以满足业务复杂查询需求
在业务侧的实际分析需求中,经常会有十几张表 Join 的场景,业界存在 Flink 和 Trino两种方案。
方案一是在写入数仓前利用Flink等提前做好相关表的Join计算,将其加工成大宽表写入数仓中,但Join后的数据存储占用代价高。方案二是直接将各个维度存储在数仓中,分析查询的时候,分析查询的时候再进行Join计算,但 Trino 在处理多表Join时性能一般,难以满足业务侧实际的查询需求。这两种方案都没有办法很好的平衡表Join的性能和数据存储占用的问题。
1.4. 运维挑战,用户查询体验需优化
在实际运维使用Trino的过程中,发现Trino不支持高可用和多副本的问题,在业务高峰期,Trino 负载较高,会影响到数据平台的稳定性和用户查询体验,降低业务决策效率,甚至有可能收到用户对数据平台的投诉。
二、OLAP 选型与实践
IT 部门调研了几款当前比较流行的 OLAP 引擎,包括 Trino、Clickhouse、StarRocks 和 Doris,并从查询延迟、SQL 类型、并发性能、Join性能和运维成本等多个维度进行了对比:
- Trino 当前的查询性能和并发能力是无法满足需求的,且 Join 查询的能力也相对较弱。
- Clickhouse 虽然查询延迟表现很优秀,但由于其支持的 SQL 类型为非标准 SQL,可能会涉及到较多的业务改造,同时其并发能力和Join能力也无法满足需求,且运维起来比较复杂。
- StarRocks 在调研的各个维度上表现都非常好,能够很好地解决当前数仓架构所面临的问题。

经过深入调研与测试,IT 部门总结了 StarRocks 的一些优势:
-
查询性能优秀:查询延迟在亚秒级别,Join性能优秀,能满足vivo对实时大数据分析的需求
-
使用方便:支持数据导入、导出等功能
-
数据模型丰富:支持明细模型、聚合模型、更新模型、主键模型,其中主键模型能够很好地满足vivo大数据的场景
-
运维成本低:支持高可用、在线扩缩容、tablet数据分片自动均衡
基于以上的对比与考量,最终选择了使用 StarRocks 来作为数据平台的 OLAP 引擎。
三、应用实践
在过去2年里,IT部门深度应用 StarRocks,并通过 StarRocks进一步完善数据架构,帮助业务更好地使用和查询数据。
IT部门对接的业务主要有可视化报表、BI 数据探索、营销分析、驾驶舱、数据大屏等,另外对应的还有研发系统和运维系统。
vivo 的数据主要来自于手机相关的订单、ERP、MES 以及其他数据,在升级数据分析平台架构后,他们将StarRocks 应用在查询引擎中,为业务团队搭建数据桥梁,支撑上层业务应用更快地查询,更准地分析。

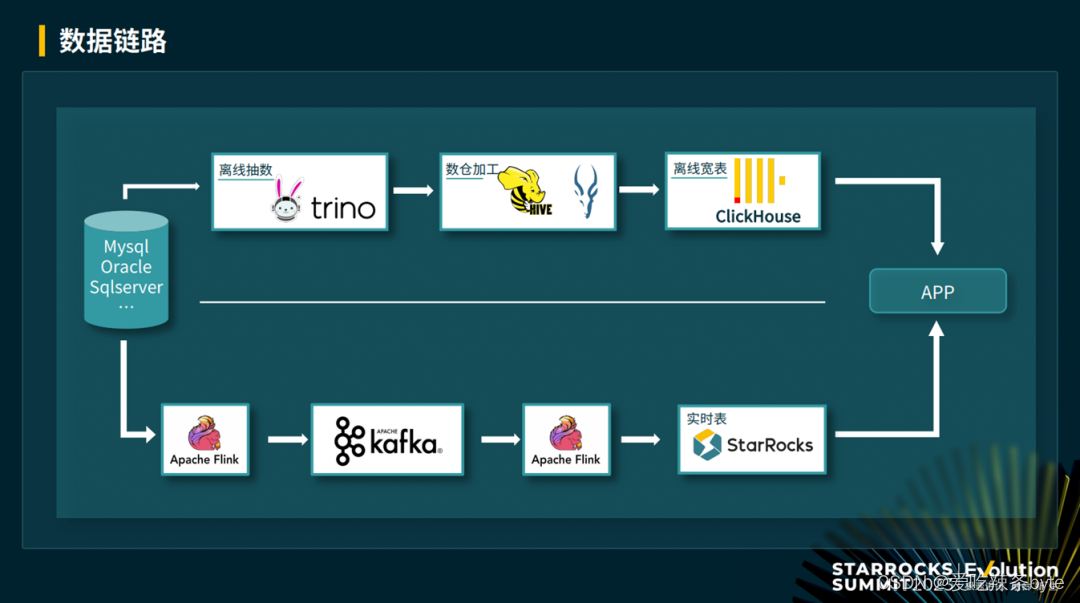
3.1 数据链路优化
vivo的数据链路分为离线和实时,其中离线链路主要是通过 Trino 进行离线抽数到 Hive 中,经过 Hive 加工处理为大宽表,再推到 Clickhouse 中进行离线场景数据的查询;
实时链路则通过 Flink 加工后写入到 Kafka 中,然后通过Flink消费处理写入到 StarRocks中进行实时表的查询。
3.2 列更新
StarRocks 的 Join 性能表现很好,频繁的Join查询会带来计算资源的大量消耗。基于此,vivo IT 部门使用Flink将多个维表打平为大宽表,写入 StarRocks 来进行查询,在节省 StarRocks 计算资源的同时,查询体验也更好。
针对维表历史数据变更的场景,他们使用 StarRocks 提供的部分列更新(Partial Update)功能,在 Flink 写入主键模型大宽表的过程中,通过一些简单的配置开启部分列更新,实现以较小的代价灵活地更新大宽表中对应的列数据。

3.3 集群监控告警
在常规的监控告警方面,由于StarRocks提供了丰富的Metrics接口,便于Prometheus 采集 StarRocks 集群各个节点的状态信息,以供 Grafana 生成各种可视化的监控大盘。
另外vivio IT部门还会对集群的审计SQL进行采集分析,通过ELK将各个FE节点的审计日志采集后写入到ES中,通过配置规则,筛选出其中的慢sql,推送到告警系统中,以提醒相应的同事关注及优化。
3.4 集群弹性部署
vivo的业务特点是业务访问量存在波峰波谷,且波峰波谷之间的访问量差异明显、时间界限明显,业务对访问持续时间更短的波峰期性能要求高,服务器资源使用率考核压力大。对于国内集群,vivo IT 部门采取了多集群的模式来分担高峰期的查询访问量,通过负载均衡将流量分摊到主备集群。

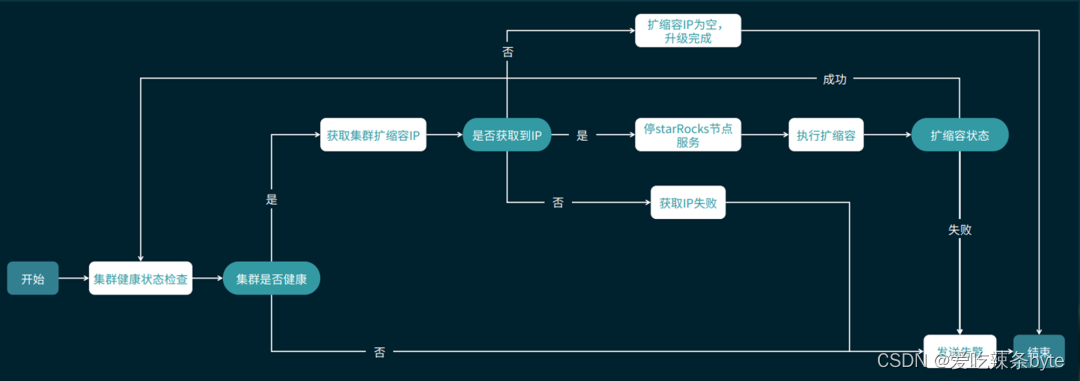
海外集群则依赖于StarRocks的多副本高可用机制,采用各个节点轮询升降配实现集群配置的扩缩容。具体的流程如下图所示,vivo IT 部门将整个流程通过代码的方式嵌入到运维平台里,通过程序自动化调度执行,提高扩缩容执行的效率。
四、结语
StarRocks 具有便捷运维、便捷部署与弹性扩缩容能力,同时提供了卓越的查询性能,足以应对vivo 高并发查询场景。
参考文章:














 6382
6382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









