







其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
物体检测(Object Detection)的任务是找出图像或视频中的感兴趣目标,同时实现输出检测目标的位置和类别,是机器视觉领域的核心问题之一,学术界已有将近二十年的研究历史。随着深度学习技术的火热发展,目标检测算法也从基于手工特征的传统算法转向了基于深度神经网络的检测技术。从最初 2013 年提出的 R-CNN、OverFeat,到后面的 Fast/Faster R-CNN、SSD、YOLO 系列,以及Mask R-CNN、RefineDet、RFBNet等(图 1,完整论文列表参见[1])。短短不到五年时间,基于深度学习的目标检测技术,在网络结构上,从 two stage 到 one stage,从 bottom-up only 到 Top-Down,从 single scale network 到 feature pyramid network,从面向 PC 端到面向移动端,都涌现出许多好的算法技术,这些算法在开放目标检测数据集上的检测效果和性能都很出色。

图 1 目标检测领域重要论文
物体检测过程中有很多不确定因素,如图像中物体数量不确定,物体有不同的外观、形状、姿态,加之物体成像时会有光照、遮挡等因素的干扰,导致检测算法有一定的难度。进入深度学习时代以来,物体检测发展主要集中在两个方向:two stage算法如R-CNN系列和one stage算法如YOLO、SSD等。两者的主要区别在于two stage算法需要先生成proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而one stage算法会直接在网络中提取特征来预测物体分类和位置。
two stage算法以及部分one stage算法(SSD系列),都需要对Region Proposal去重。比如经典的Faster RCNN算法会生产2000的Region Proposal,如果对所有的检测检测框进行分类和处理,会造成大量无效计算。使用某些算法对检测框去重,是目标检测领域的一个重要方向。
本文主要介绍在目标检测中使用的检测框去重,包括NMS,Soft-NMS,Softer-NMS,以及Relation Netwrok,ConvNMS,NMS Network,Yes-Net等,详细讲述NMS算法的演变和最新进展。
1、传统NMS算法
1.1 NMS介绍
在目标检测中,常会利用非极大值抑制算法(NMS,non maximum suppression)对生成的大量候选框进行后处理,去除冗余的候选框,得到最佳检测框,以加快目标检测的效率。其本质思想是其思想是搜素局部最大值,抑制非极大值。非极大值抑制,在计算机视觉任务中得到了广泛的应用,例如边缘检测、人脸检测、目标检测(DPM,YOLO,SSD,Faster R-CNN)等。即如图 2所示实现效果,消除多余的候选框,找到最佳的bbox。
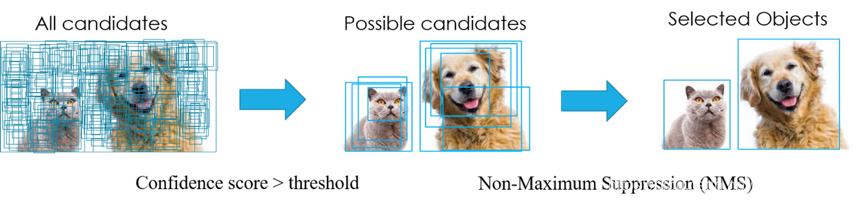
图 2 NMS消除冗余候选框
以图 2为例,每个选出来的Bounding Box检测框(既BBox)用(x,y,h,w, confidence score,Pdog,Pcat)表示,confidence score表示background和foreground的置信度得分,取值范围[0,1]。Pdog,Pcat分布代表类别是狗和猫的概率。如果是100类的目标检测模型,BBox输出向量为5+100=105。
值得注意的是,RCNN有一句话的NMS介绍,Fast-RCNN无任何NMS的解释,Faster有大量篇幅对NMS的效果分析。
1.2 NMS算法过程
NMS主要就是通过迭代的形式,不断的以最大得分的框去与其他框做IoU操作,并过滤那些IoU较大(即交集较大)的框。如图 3图 4所示NMS的计算过程。
1、根据候选框的类别分类概率做排序,假如有4个 BBox ,其置信度A>B>C>D。
2、先标记最大概率矩形框A是算法要保留的BBox;
3、从最大概率矩形框A开始,分别判断ABC与D的重叠度IOU(两框的交并比)是否大于某个设定的阈值(0.5),假设D与A的重叠度超过阈值,那么就舍弃D;
4、从剩下的矩形框BC中,选择概率最大的B,标记为保留,然后判读C与B的重叠度,扔掉重叠度超过设定阈值的矩形框;
5、一直重复进行,标记完所有要保留下来的矩形框。

图 3猫和狗两类目标检测

图 4 NMS算法过程
如果是two stage算法,通常在选出BBox有BBox位置(x,y,h,w)和confidence score,没有类别的概率。因为程序是生成BBox,再将选择的BBox的feature map做rescale (一般用ROI pooling),然后再用分类器分类。NMS一般只能在CPU计算,这也是two stage相对耗时的原因。
但如果是one stage作法,BBox有位置信息(x,y,h,w)、confidence score,以及类别概率,相对于two stage少了后面的rescale和分类程序,所以计算量相对少。
1.3 优缺点分析
NMS缺点:
1、NMS算法中的最大问题就是它将相邻检测框的分数均强制归零(既将重叠部分大于重叠阈值Nt的检测框移除)。在这种情况下,如果一个真实物体在重叠区域出现,则将导致对该物体的检测失败并降低了算法的平均检测率(average precision, AP)。
2、NMS的阈值也不太容易确定,设置过小会出现误删,设置过高又容易增大误检。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









