







一、Llama3-Chinese-8B简介
LLaMA 3 (Large Language Model Meta AI) 是 Meta(原 Facebook)发布的一个大规模预训练语言模型系列的第三代版本。LLaMA 3 旨在推动自然语言处理(NLP)的研究和应用,其系列模型具有较强的语言理解和生成能力。
LLaMA 3-Chinese 是 LLaMA 3 系列中的一个专门针对中文进行优化的版本。这个版本的模型在大量中文文本上进行训练,因此在中文文本生成、理解和对话等任务上表现优异。
模型特点
- 高性能 :LLaMA 3-Chinese 模型使用了先进的模型架构和训练技术,使其在中文处理任务上具有较高的准确性和生成能力。
- 大规模预训练:该模型在大量的中文数据上进行预训练,因此具备了强大的语言理解和生成能力。
- 适应性强 :能够用于各种中文 NLP 任务,如文本分类、情感分析、机器翻译和对话生成等。
应用场景
- 中文对话系统 :可以用来构建聊天机器人和对话系统,支持自然流畅的中文对话。
- 内容生成 :适用于自动生成中文内容,如文章写作、新闻生成和社交媒体内容创作。
- 文本分析:用于中文文本分类、情感分析和信息提取等任务。
LLaMA 3-Chinese 实现 Meta-Llama-3-8B 为底座,使用 DORA (https://arxiv.org/pdf/2402.09353.pdf)+ LORA(https://arxiv.org/pdf/2402.12354.pdf)+ 的训练方法,在500k高质量中文多轮SFT数据 、100k英文多轮SFT数据和2k单轮自我认知数据训练创建的大模型。
二、模型搭建流程
1. 创建容器实例
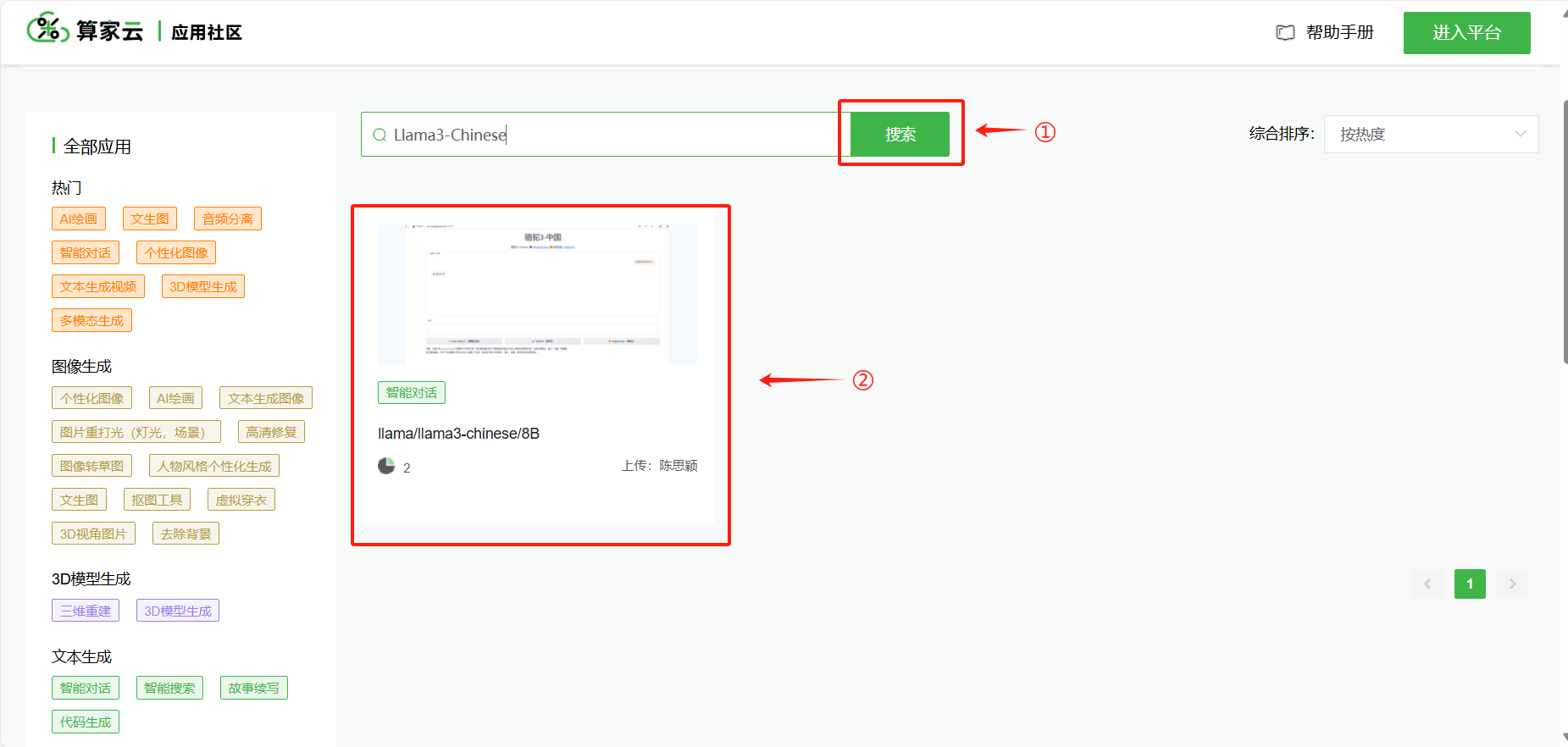
(1)进入算家云的“应用社区”,点击搜索找到"Llama3-Chinese-8B",点击“创建应用”,即可进入容器平台
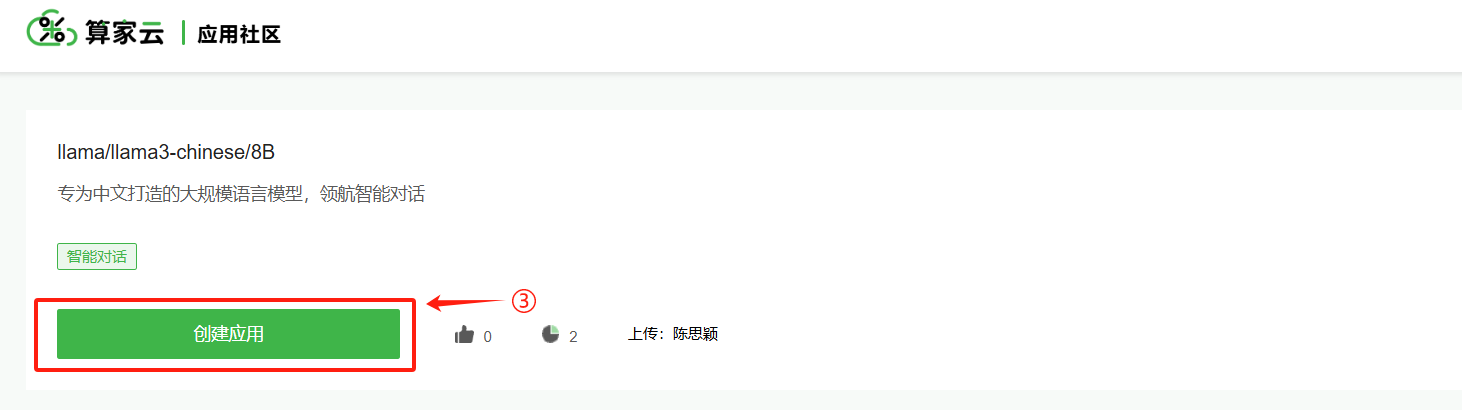
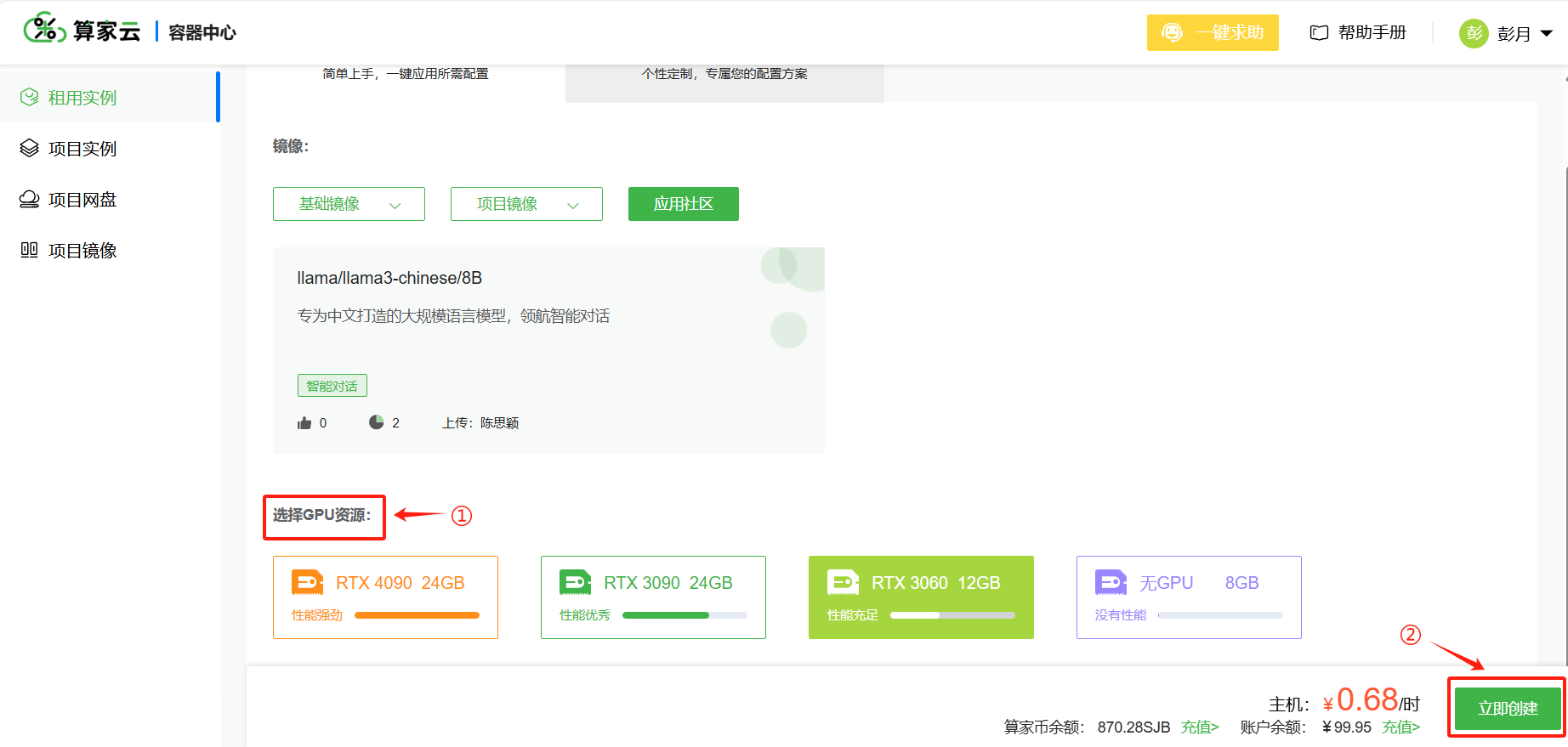
(2)点击进入之后会自动匹配模型,选择显卡,点击“立即创建”即可创建实例
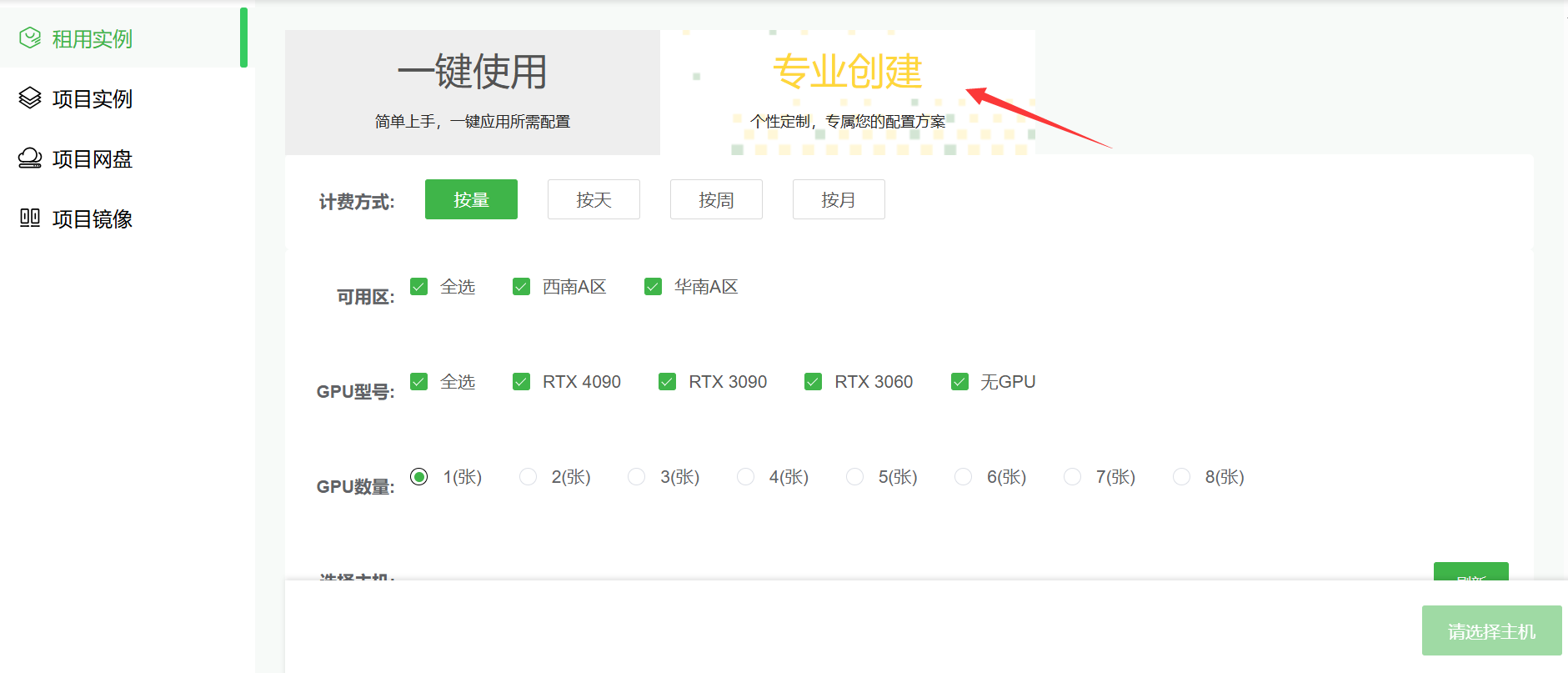
也可以点击”专业创建“,自主选择 GPU 型号、计费方式等配置
2. 启动项目
(1)点击“webssh”开启终端

(2) 终端操作
进入命令操作页后,输入或者复制粘贴一下命令
cd /llama3-chinese-main/
python web_demo.py --model_path /llama3-chinese-main/Llama3-Chinese/
如图:

3. 开启外部访问
返回“项目实例”列表,选择并点击对应实例的“开放端口”,然后按下图操作:
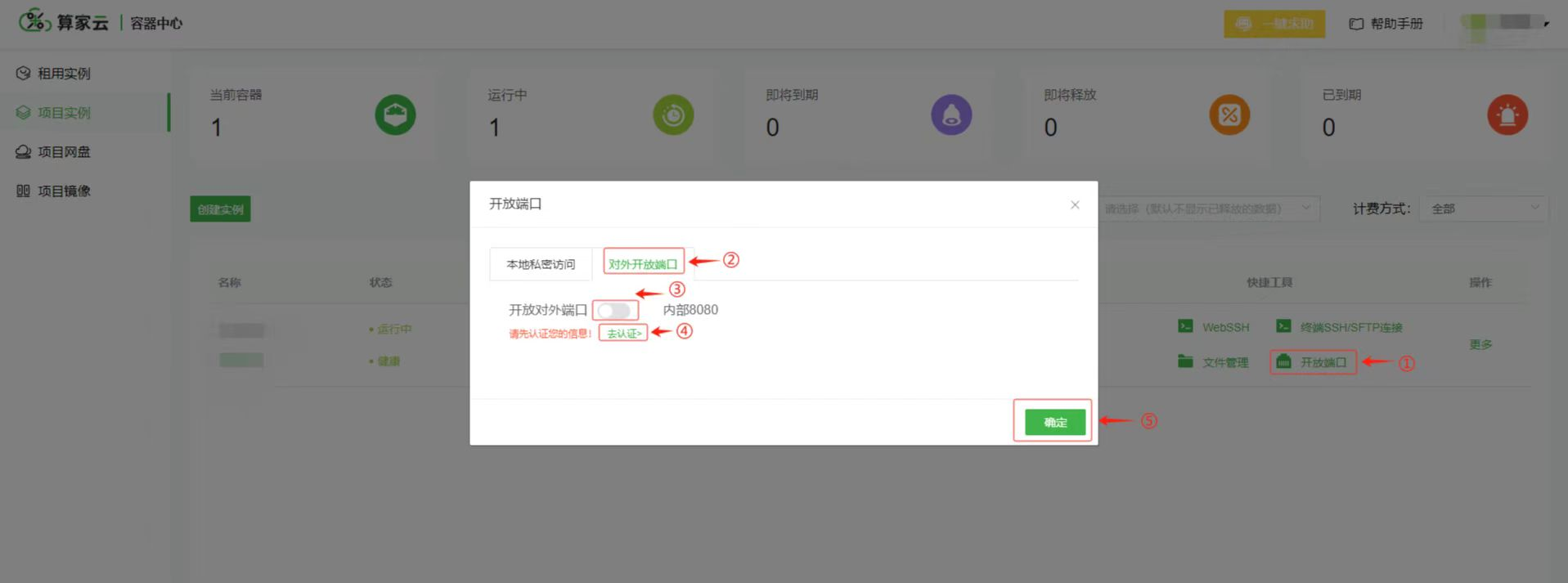
4. 获取访问地址,开始使用
打开浏览器,在地址栏 Ctrl+V 粘贴复制的访问地址进行访问,即可开始使用llama3-chinese。
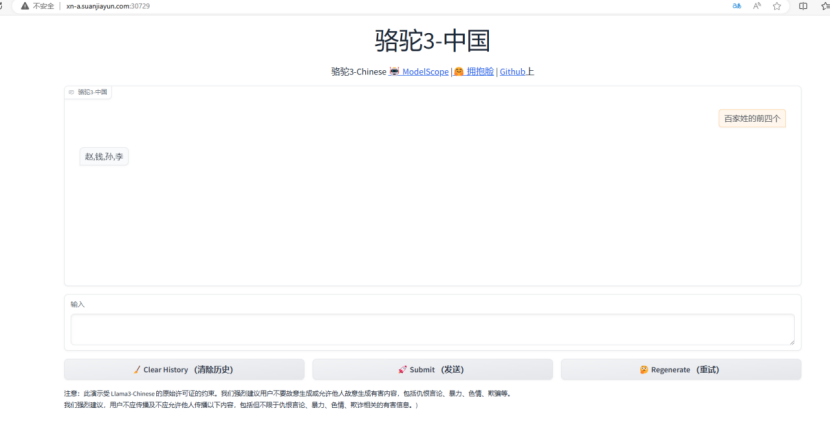
以上就是在算家云搭建 Llama3-Chinese-8B 的流程,具体使用方式可进入算家云应用社区查看该模型的使用说明。
复制下方网址,进入算家云,选择模型,一键开启 AI 之旅!
算家云应用社区 www.suanjiayun.com/container/#/mirror

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









