







一、介绍
MimicMotion (运动模仿)是具有置信感知姿势指导的高质量人体运动视频生成模型。它可以在任何运动引导下生成任意长度的高质量视频。目前它支持以 576x1024 分辨率生成最多 72 帧的视频。
二、特点
首先,通过置信度感知姿态引导,可以实现时间平滑度,从而通过大规模训练数据增强模型鲁棒性。
其次,基于姿态置信度的区域损失放大显著缓解了图像的失真。
最后,针对长而流畅的视频生成,该文提出一种渐进式潜融合策略。通过这种方式,能以可接受的资源消耗生成任意长度的视频。
简而言之:就是通过一张静态照片和一段视频,实现静态照片人物模仿视频中人物动作的模型。
三、构建
VRAM要求和运行时间:
对于 35 秒的演示视频,72 帧模型需要16GB 显存 (4060ti),并在4090GPU上20分钟内能完成。
16 帧 U-Net 型号的最低显存要求为 8GB;但是VAE 解码器需要 16GB。您可以选择在 CPU 上运行 VAE 解码器。
环境推荐:python 3+ with torch 2.x 使用 Nvidia V100 GPU(显卡3090及以上也行)进行验证。
1. 环境搭建
(1)更新软件包
apt-get update
(2)安装所需命令及依赖
apt-get install sudo
sudo apt-get install -y git wget curl bzip2 build-essential ca-certificates gcc
(3)从github仓库克隆项目
git clone https://github.com/Tencent/MimicMotion.git
cd MimicMotion
mkdir models
(4)安装conda
下面需要使用Anaconda或Mimiconda创建虚拟环境,可以输入 conda --version进行检测,如果已安装请跳过该步。下面是Mimiconda的安装过程:
- 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
- 遵循安装提示并初始化
按 Enter 键查看许可证条款,阅读完毕后输入 yes 接受条款,安装完成后,脚本会询问是否初始化 Conda 环境,输入 yes 并按 Enter 键。
- 运行
source ~/.bashrc命令激活 Conda环境 - 再次输入
conda --version命令来验证时候安装成功,如果出现类似conda 4.10.3这样的输出就成功了。
(5)创建虚拟环境
安装好conda之后,输入下面命令构建项目环境:
conda env create -f environment.yaml
conda activate mimicmotion
如果 conda 版本较老则使用下面命令开启
source activate mimicmotion
2. 下载模型文件
(1)下载预训练模型:dwpose
DWPose 是一个用于姿势估计的模型,具有出色的姿势检测和估计能力,适用于姿势识别和估计任务。输入下面命令进行下载:
mkdir -p models/DWPose
wget https://huggingface.co/yzd-v/DWPose/resolve/main/yolox_l.onnx?download=true -O models/DWPose/yolox_l.onnx
wget https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx?download=true -O models/DWPose/dw-ll_ucoco_384.onnx
若无法访问"hugging face"则可通过"魔搭社区"手动下载模型,放到models/DWPose文件夹中
路径如下:MimicMotion/models/DWPose
(2)从 Huggingface 下载 MimicMotion 的预训练检查点
wget -P models/ https://huggingface.co/ixaac/MimicMotion/resolve/main/MimicMotion_1-1.pth
可通过"魔搭社区"手动下载MimicMotion_1-1.pth,放到models文件夹中
(3)SVD 模型 stabilityai/stable-video-diffusion-img2vid-xt-1-1 将自动下载。
也可"魔搭社区"手动下载文件,放置在stabilityai文件夹下(没有就在MimicMotion文件夹下创一个)
最终下载的模型文件目录结构应如下:
MimicMotion
├── models
│ ├── DWPose
│ │ ├── dw-ll_ucoco_384.onnx
│ │ └── yolox_l.onnx
│ └── MimicMotion_1-1.pth
└── stability
└── stable-video-diffusion-img2vid-xt-1-1
3. 进行推理
python inference.py --inference_config configs/test.yaml
提示:如果您的 GPU 内存有限,请尝试设置 env 。PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256
本项目官方并未自带ui界面,因此无需开放端口,需要自行在进行推理前后手动存取图片、视频。
但是本人为该项目提供ui界面,如果需要请看下面的步骤:
4. 添加UI界面
(1)在MimicMotion文件夹下创建一个 gradio_app.py文件,将下面的代码复制到里面:
import os
import argparse
import logging
import math
from omegaconf import OmegaConf
from datetime import datetime
from pathlib import Path
import numpy as np
import gradio as gr
import torch
from mimicmotion.utils.loader import create_pipeline
from mimicmotion.utils.utils import save_to_mp4
from inference import preprocess, run_pipeline
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#-----------------------------------------------------------------------
def run_MimicMotion(
ref_image_path,
ref_video_path,
num_frames,
resolution,
frames_overlap,
num_inference_steps,
noise_aug_strength,
guidance_scale,
sample_stride,
fps,
seed,
use_fp16,
):
if use_fp16:
torch.set_default_dtype(torch.float16)
infer_config = OmegaConf.create({
'base_model_path': 'stability/stable-video-diffusion-img2vid-xt-1-1',
'ckpt_path': 'models/MimicMotion.pth',
'test_case': [
{
'ref_video_path': ref_video_path,
'ref_image_path': ref_image_path,
'num_frames': num_frames,
'resolution': resolution,
'frames_overlap': frames_overlap,
'num_inference_steps': num_inference_steps,
'noise_aug_strength': noise_aug_strength,
'guidance_scale': guidance_scale,
'sample_stride': sample_stride,
'fps': fps,
'seed': seed,
},
],
})
pipeline = create_pipeline(infer_config, device)
for task in infer_config.test_case:
# Pre-process data
pose_pixels, image_pixels = preprocess(
task.ref_video_path, task.ref_image_path,
resolution=task.resolution, sample_stride=task.sample_stride
)
# Run MimicMotion pipeline
_video_frames = run_pipeline(
pipeline,
image_pixels, pose_pixels,
device, task
)
################################### save results to output folder. ###########################################
now_str = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
output_dir = os.path.dirname(os.path.abspath(__file__))
output_dir = os.path.join(output_dir, 'outputs')
if not os.path.exists(output_dir):
os.mkdir(output_dir)
filename = os.path.splitext(os.path.basename(task.ref_image_path))[0]
path_out_vid = os.path.join(output_dir, f'{filename}_{now_str}.mp4')
print(f'Video will be saved to: {path_out_vid}')
save_to_mp4(_video_frames, path_out_vid, fps=task.fps)
print('OK !')
return path_out_vid
#-----------------------------------------------------------------------
with gr.Blocks() as demo:
with gr.Row():
gr.Markdown("""
<h2><a href="https://github.com/Tencent/MimicMotion" target="_blank" style="text-decoration: none">MimicMotion</a>:利用置信度感知姿势引导生成高质量人体运动视频</h2>
""")
with gr.Row():
with gr.Column():
gr_ref_img = gr.Image(label='参考图片', type='filepath')
gr_ref_vid = gr.Video(label='参考视频')
with gr.Column():
gr_out_vid = gr.Video(label='生成结果', interactive=False)
with gr.Accordion(label='参数设置'):
gr_num_frames = gr.Number(label='总帧数', value=16)
gr_resolution = gr.Number(label='分辨率', value=576)
gr_frames_overlap = gr.Number(label='重叠帧数', value=6)
gr_infer_steps = gr.Number(label='推理步数', value=25)
gr_noise_aug_strength = gr.Number(label='噪声强度', value=0.0)
gr_guidance_scale = gr.Number(label='引导系数', value=2.0)
gr_sample_stride = gr.Number(label='采样步长', value=2)
gr_fps = gr.Number(label='帧率', value=15)
gr_seed = gr.Number(label='种子', value=42)
gr_use_fp16 = gr.Checkbox(label='使用float16', value=True)
gr_btn = gr.Button(value='生成视频')
gr_btn.click(
fn=run_MimicMotion,
inputs=[
gr_ref_img,
gr_ref_vid,
gr_num_frames,
gr_resolution,
gr_frames_overlap,
gr_infer_steps,
gr_noise_aug_strength,
gr_guidance_scale,
gr_sample_stride,
gr_fps,
gr_seed,
gr_use_fp16,
],
outputs=gr_out_vid,
)
demo.launch()
(2)根据自己的实际路径更改文件中 infer_config的 base_model_path和 ckpt_path的路径(如果严格按照步骤走的话就不用改)
(3)通过UI脚本启动模型:
cd MimicMotion/
python gradio_app.py
四、网页演示
运行成功后获取访问链接,进入webUI界面后操作如下:
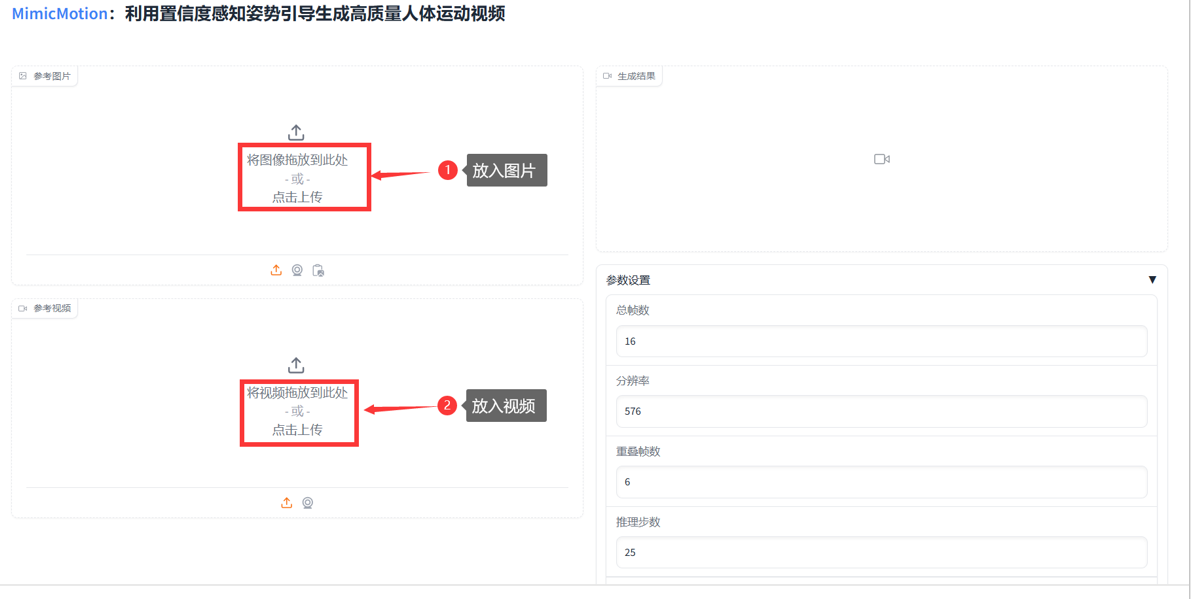
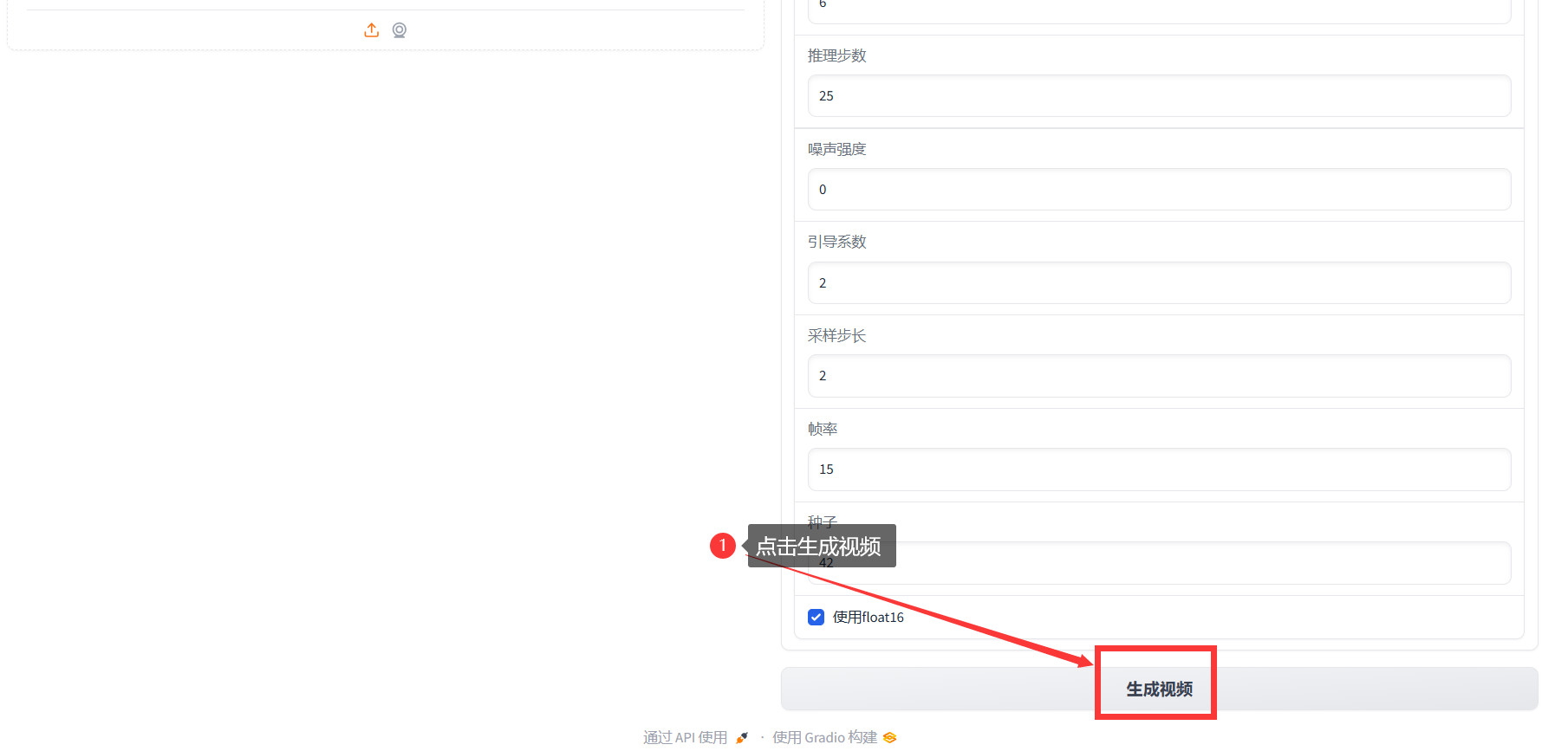


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









