







 本文介绍了使用Python进行WebShell检测的实践,探讨了numpy, SciPy, NLTK和Scikit-Learn等库在机器学习中的应用。通过特征提取、数据预处理和朴素贝叶斯算法,对WebShell进行检测,实验结果显示三折交叉验证的准确率约80%,而十折交叉验证则达到77%。通过对函数调用特征的改进,准确率进一步提升到85.7%。"
111106269,10294875,Swift初学者指南:创建你的第一个项目,"['swift项目', 'iOS开发', 'Xcode教程', '应用程序创建', 'UI设计']
本文介绍了使用Python进行WebShell检测的实践,探讨了numpy, SciPy, NLTK和Scikit-Learn等库在机器学习中的应用。通过特征提取、数据预处理和朴素贝叶斯算法,对WebShell进行检测,实验结果显示三折交叉验证的准确率约80%,而十折交叉验证则达到77%。通过对函数调用特征的改进,准确率进一步提升到85.7%。"
111106269,10294875,Swift初学者指南:创建你的第一个项目,"['swift项目', 'iOS开发', 'Xcode教程', '应用程序创建', 'UI设计']
本文主要参考自兜哥的《Web安全之机器学习入门》
前段时间在研究WebShell的检测查杀,然后看到兜哥的著作中提到的几个机器学习算法中也有实现WebShell检测的,主要有朴素贝叶斯分类、K邻近算法、图算法、循环神经网络算法等等,就一一试试看效果吧。
Python中的几个机器学习的库
1、numpy:
安装:pip install --user numpy
2、SciPy:
专为科学和工程设计的Python包,包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等。
安装:pip install --user numpy scipy matplotlib iPython jupyter pandas sympy nose
3、NLTK:
在NLP自然语言处理领域中最常用的一个Python库,包括图形演示和示例数据。
安装:pip install -U nltk
加载数据:
import nltk
nltk.download()将提示要下载的包都下载安装完成即可。
用法示例:
分句:
import nltk
sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
sentence = "This is the first sentence, and the second sentence is follow. This is the second sentence."
sentences = sent_tokenizer.tokenize(sentence)
print sentences

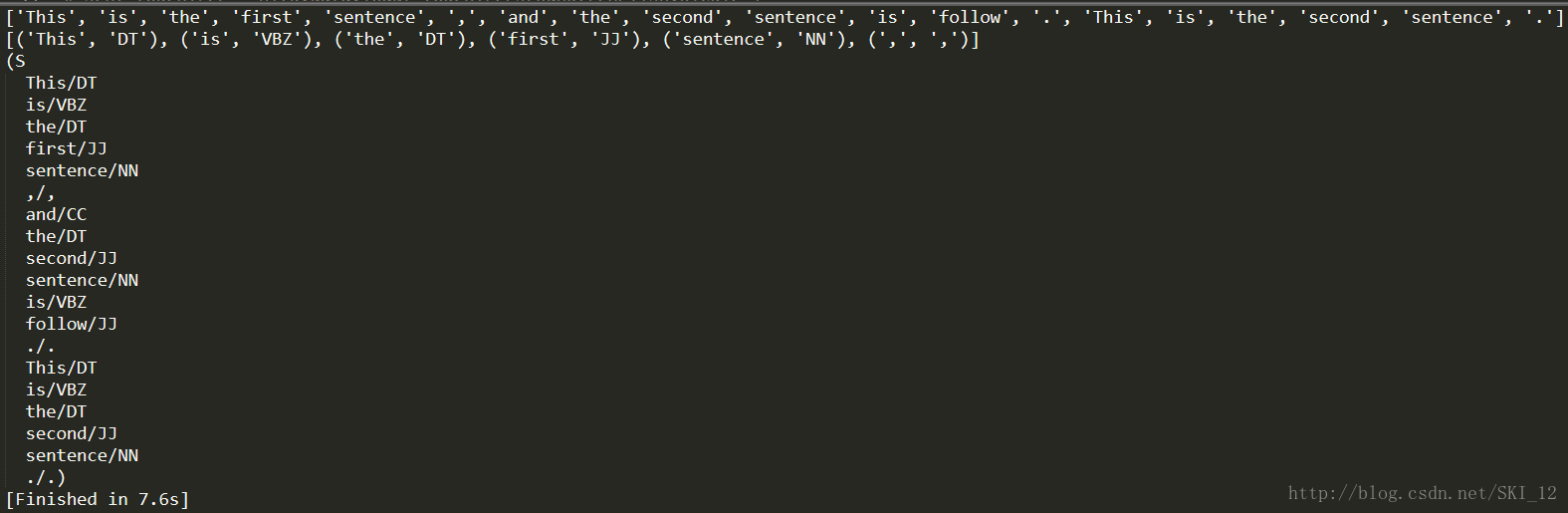
分词与标识、标识名词实体:
import nltk
sentence = "This is the first sentence, and the second sentence is follow. This is the second sentence."
tokens = nltk.word_tokenize(sentence)
print tokens
tagged = nltk.pos_tag(tokens)
print tagged[0:6]
entities = nltk.chunk.ne_chunk(tagged)
print entities
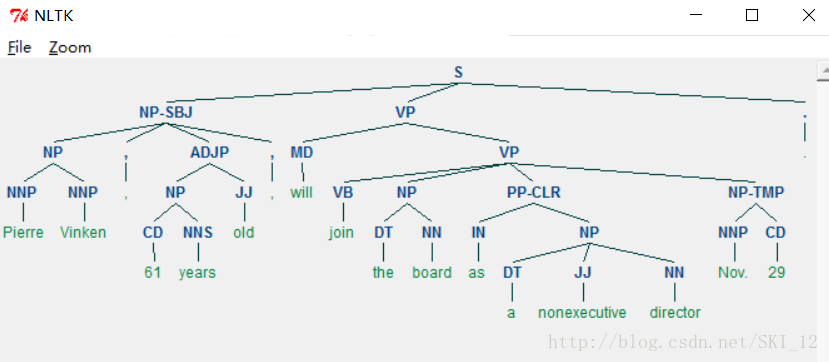
展现语法树:
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()
4、Scikit-Learn:
是基于Python的机器学习模块,基于BSD开源许可证,基本功能包括分类、回归、聚类、数据降维、模型选择、数据预处理等。
依赖的环境:
Python>=2.6 or >=3.3
NumPy>=1.6.1
SciPy>=0.9
安装:pip install -U scikit-learn
Scikit-Learn数据集:
最常见的是iris数据集,iris指鸢尾植物,其存储了其萼片和花瓣的长宽,共4个属性,且鸢尾植物又分为3类。iris里有两个属性:iris.data和iris.target。data里是一个矩阵,每一列代表了萼片或花瓣的长宽,共4列,一共采样150条记录;target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,所以数组长度是150,不同的值只有3个。
用法示例:
#coding=utf-8
from sklearn import datasets
iris = datasets.load_iris()
# iris.data共四列,一共采样150条记录;iris.target数组长度为150
print iris.feature_names # 显示特征名称
# print iris.data # 显示数据
print iris.data.shape
print iris.data.size # 显示数据的大小
# print iris.target
print iris.target_names # 显示分类名称
print iris.target.shape
print iris.target.size

特征提取:
1、数字型特征提取:
数字型特征是可以直接作为特征的,但可能存在少量的一些特征的取值范围较为异常,这时就需要进行预处理。常见的数字型特征预处理方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









