







写论文见到的一篇文章
感觉很有用处
原文链接
这个链接不知道是不是他自己的原文链接,我在他下边的博客地址里翻了半天也没找到,但是博客的名字是一样的(应该是一样的叭,如果大家又看到原文,麻烦把正确的链接贴在评论区,我来修改一下嘻嘻,感谢)
刚刚发现他有博客欸,整理的很不错哇,适合我这种菜鸡(啊哈哈哈)
这里附上他的博客地址
详细代码可以去GitHub看他的博客内容
下面是我的粗糙的学习笔记整理概括
1.tomotopy简介
 tomotopy 是 tomoto(主题建模工具)的 Python 扩展,它是用 C++ 编写的基于 Gibbs 采样的主题模型库。支持的主题模型包括 LDA、DMR、HDP、MG-LDA、PA 和 HPA, 利用现代 CPU 的矢量化来最大化速度。
tomotopy 是 tomoto(主题建模工具)的 Python 扩展,它是用 C++ 编写的基于 Gibbs 采样的主题模型库。支持的主题模型包括 LDA、DMR、HDP、MG-LDA、PA 和 HPA, 利用现代 CPU 的矢量化来最大化速度。
实例代码
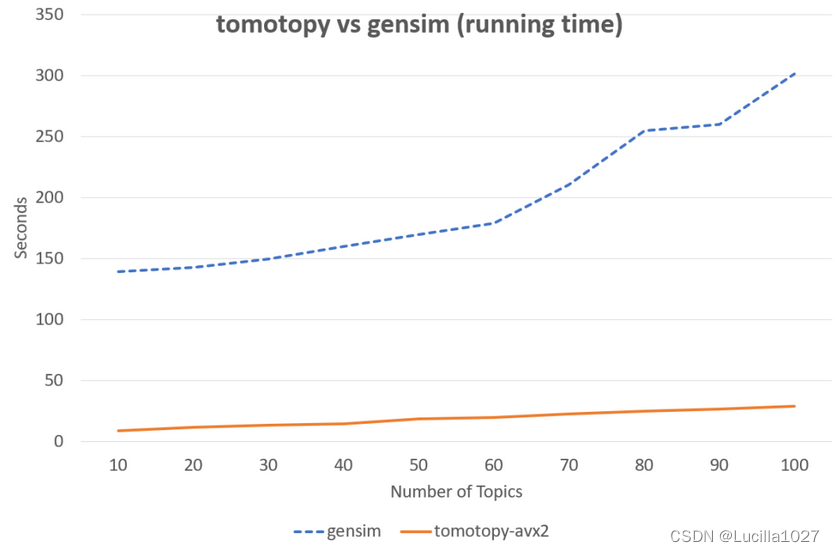
下图中同样的数据集, tomotopy迭代200次,gensim迭代10次的情况下, tomotopy与gensim耗时对比图,由此可见tomotopy训练主题模型速度之快。
 当前版本的 tomotopy 支持的主题模型包括
当前版本的 tomotopy 支持的主题模型包括
潜在狄利克雷分配(LDAModel)
标记的 LDA(LLDA 模型)
部分标记的 LDA(PLDA 模型)
监督LDA(SLDA模型)
Dirichlet 多项回归 (DMRModel)
广义狄利克雷多项回归 (GDMRModel)
分层狄利克雷过程 (HDPModel)
分层LDA(HLDA模型)
多粒 LDA(MGLDA 模型)
弹珠盘分配(PAModel)
分层 PA (HPAModel)
相关主题模型(CTModel)
动态主题模型 (DTModel)
基于伪文档的主题模型(PTModel)。
2.安装
!pip3 install tomotopy==0.12.2
!pip3 install pyLDAvis==3.3.1
#目前,tomotopy 可以利用 AVX2、AVX 或 SSE2 SIMD 指令集来最大程度利用PC的
import tomotopy as tp
tp.isa
#将会输出'avx2'
如果 tp.isa 返回 None,则训练过程可能需要很长时间。
3.数据的导入
import pandas as pd
df = pd.read_csv('disaster_news.csv')
df.head()

4.数据预处理
import re
import jieba
from cntext import STOPWORDS_zh
def segment(text):
words = jieba.lcut(text)
words = [w for w in words if w not in STOPWORDS_zh]
return words
#####test可以设置为读取一个文件什么的,按自己需要的情况修改
test = "云南永善县级地震已致人伤间民房受损中新网月日电据云南昭通市防震减灾局官方网站消息截至日时云南昭通永善县级地震已造成人受伤其中重伤人轻伤人已全部送医院救治民房受损户间倒塌户间个乡镇所学校不同程度受损目前被损毁电力交通通讯设施已全部抢通修复当地已调拨帐篷顶紧急转移万人月日时分云南昭通永善县发生里氏级地震震源深度公里当地震感强烈此外成都等四川多地也有明显震感"
print(segment(test))
#####这句应该是说写成一个列表,就是第一列是原本的text内容后边追加的第二列是做好预处理的文本
df['words'] = df['text'].apply(segment)
df.head()
####贴了原文的图,对比一下上下的图片

5.找最佳主题数
正常的步骤应该认真对待这步,在一定区间范围内,根据模型得分找到合理的K。这里使用tomotopy提供的主题一致性coherence得分假装找一下。
我们期望的图应该的topic coherence随着 number of topics增加而增加,然后到某个topic值趋于平稳。
tomotopy每次运行得到的图形状不一样,为了保证运行结果具有可比性,设置了随机种子seed为555,你也可以根据需要改为自己需要的随机状态(这里有点像炼丹)。经过运行发现k=5比较合适。
def find_k(docs, min_k=1, max_k=20 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









