







本文字数:5425字
预计阅读时间:14 分钟
字符编码的奥秘
本文旨在讲解常见的字符编码,如:Unicode、UTF-8、GBK字符集,以及emoji。
起初计算机在美国发明,自然大家考虑的是如何表示英文,英语字母总共26个,加上特殊字符,用128个字符,一个byte即足以表示出来。这个就是大家所熟知的ASCII编码。对应关系很简单,一个字符对应一个byte。
但很快人们发现,其他非英语国家的文字远远超过ASCII码,不同国家推出了自己不同的编码方式,中国的gb2312就是我们国家自己推行的编码方式,这样下去每个国家都有自己的编码方式,来回转换太麻烦了;这时候大家当然想统一字符编码,这时候出现了新的编码方式,unicode编码方式,将编码统一,规定了每个字符对应的unicode码。
Unicode概述
Unicode(统一码,万国码)是基于通用字符集(Universal Character Set)的标准发展。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足语言、跨平台进行文本转换、处理的要求。
Unicode是1988年由Apple和Xerox共同建立的一项标准。1991年,成立专门的协会来开发和推动Unicdoe。
Unicode用数字0到0X10FFFF来映射这些数字,最多容纳1114112个字符。1114112是怎么计算出来的?将0X10FFFF分成0X10和0XFFFF两部分。我们知道0XFFFF是65535,那么 [0,65535] 区间内,总共是65536个。同理,0X10用10进制表示为16,那么 [ 0,16 ] 左右闭区间,总共是17个(我们称之为17个平面)。所以17乘以65536 = 1114112。
这里需要注意:第0平面最为重要,后面第1,2…16所有平面都是通过第0平面中的一个代理区表示的(详见图4)。
世界上各种字符,用 Unicode 排布
当我们看到0X10FFFF的时候,会产生一个疑问。怎么是三个字节呢?现代计算机都是32位或者64位了吧。如果是32位的话,第一个字节干什么用,是全用0填充么?怎么第二个字节也就用到0x10?
前面我们提到“通用字符集”。目前世界上有两个标准UCS-2用2个字节编码和UCS-4用4个字节编码。那么0X10FFFF即UCS-4了。
把0x10FFFF用二进制表示:0000-00000001-00001111-11111111-1111
如上所示,UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行第4字节有256个码位(cell)。每个平面有2^16=65536个码位。如图1:
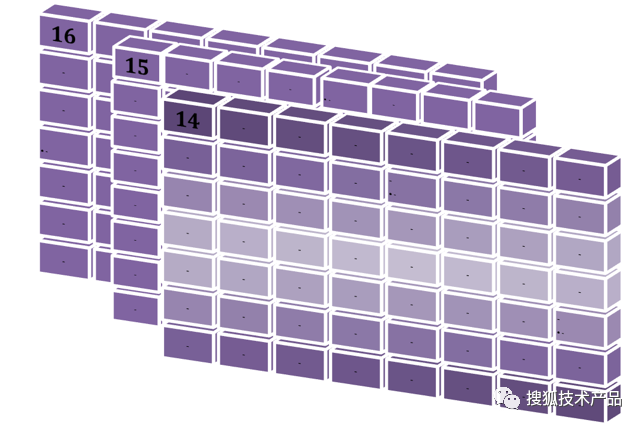 (图1)
(图1)
上面我们讲过,14-15-16平面基本都是PUA,最重要的是下面的0-1-2三个平面,特别是第0个平面,也就是下图中色彩斑斓的平面;

(图2)
图中每层代表一个平面。Unicode计划使用了17个平面,一共有17*65536=1114112个码位。在Unicode 5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其他平面尚未使用,如下图所示:
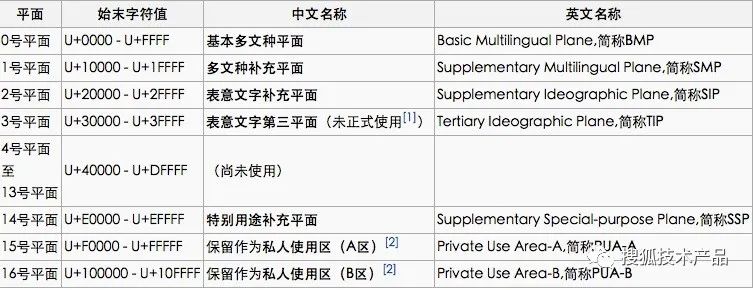
(图3)
其中,平面15和16上定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。下图说明了第0平面的字符分布:
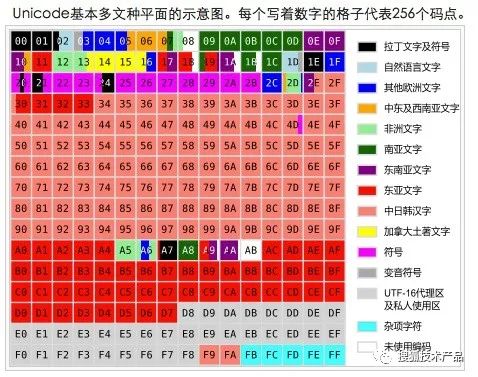
(图4)
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位(见上图),是一个被称作代理区(Surrogate)的特殊区域。代理区的目的是:用两个UTF-16字符表示BMP以外的字符。如前所述在Unicode 5.0.0版本中,238605-65534*2-6400-2048=99089。余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,它们对应着Unicode目前定义的99089个字符。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。中国汉字的Unicode位置,71226个汉字分别分布在两个平面上,第0个平面上有27973个常用汉字,第2个平面43253个汉字,你会发现第2个平面上清一色都是汉字。
UTF-8 编码
回到本文的重点UTF-8编码,utf-8是Unicode的一种存储、传输方式,是一种可变长编码方式;是Unicode实现方式之。UTF是“Unicode/UCS Transformation Format”的首字母缩写。Unicode是字符集也是编码集,UTF-8是编码集;UTF-8以字节为单位对Unicode进行编码。它是可变长的编码方式的从表1中也能开出来。从Unicode到UTF-8的编码方式如下:
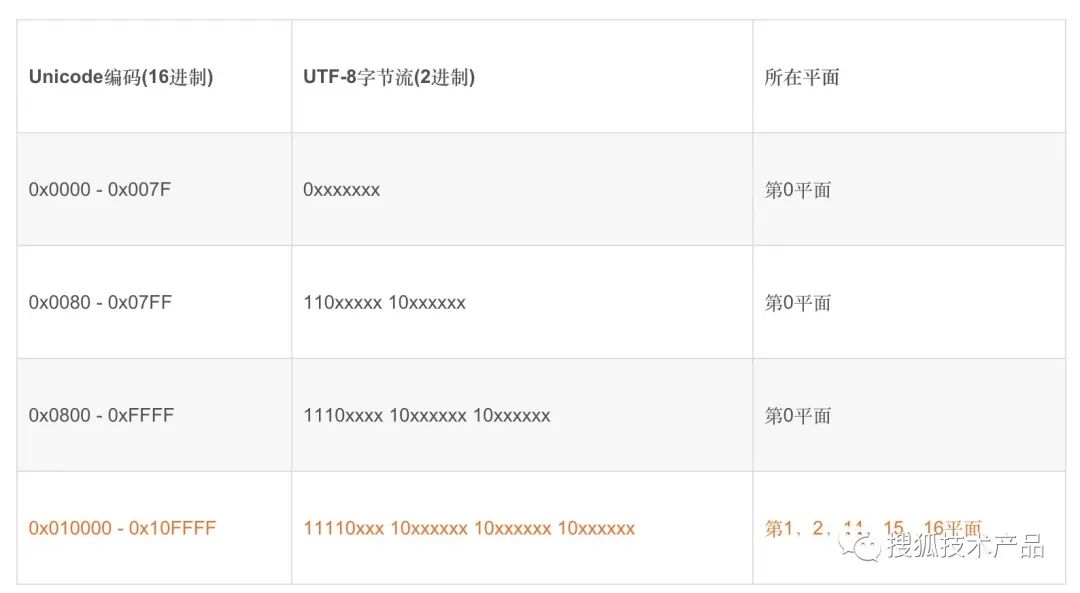
(图5)
例:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。因为,常用汉字第一个的编码从0X3e00,所以常用汉字的UTF8都是三个字节。如果在平面2中的汉字必须4个字节了。如果你用C语言做过协议栈,就会清楚记得,给汉字开辟内存时候要使用4个字节。
此外,使用正则表达式来区分汉字,通常使用下面的代码:
NSPredicate* predicate = [NSPredicate predicateWithFormat:@"SELF MATCHES %@",@"[\u4e00-\u9fa5]"];
**_判断是否为中文的正则表达式_**
if([predicate evaluateWithObject:name]){
是中文
}else{
不是中文
}那么对于一些生僻字,就不灵了,如下图:
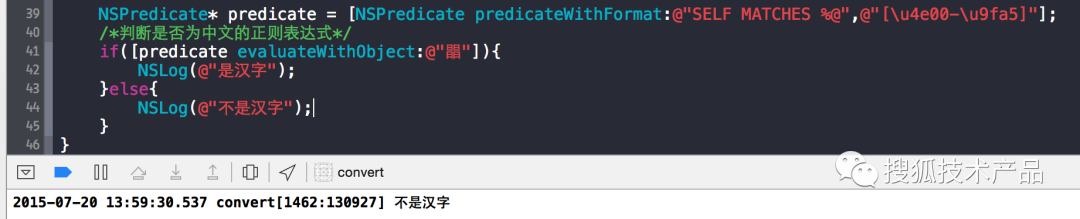
(图6)
如四个日组成的汉字,运行结果却“不是汉字”,因为它的Unicode编码是0xD84C-DEAB(这是代理区)。不在[e4E00-9FA5]区间。但,此正则表达式对于鉴别常用汉字已经是足够使用了。
代理区
第0平面中,0xD800-0xDFFF,共2048个码位用于表示代理区。在输入框输入一个emoji——😊微笑,然后通过UTF-8转化工具,看看它的编码是这样:
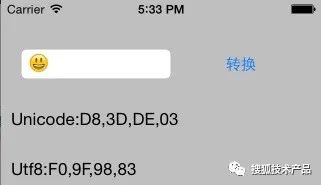
(图7)
可以看到Unicode编码是 D83D-DE03。utf-8的编码是F09F-9883。常见字符Unicode很少四个字节的,这个不寻常的。通常utf-8是1到3个字节的,也就是说在Unicode编码空间的第0个平面上。可以简单推测:既然emoji的utf-8是4个字节,说明在1,2…16个平面中的某一个 我们再看看“微笑”的emoji符号的Unicode:D83D-DE03,已经超过了表格中最大的0X10FFFF了,怎么回事???下面我们根据utf-8的值:F09F-9883.来反推Unicode对应的数值吧,看看究竟是为什么:
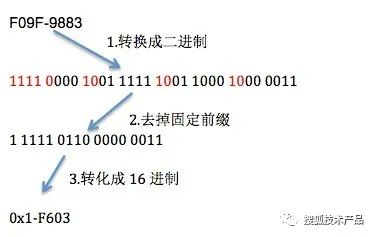
(图8)
得出的结果是0x1-F603,这个结果跟Unicode:D83D-DE03的值相差很大,所以,中间肯定经过了一些转换步骤,这个转换就是utf-16的代理!!!
UTF-16
UTF是“Unicode/UCS Transformation Format”的首字母缩写,即把Unicode字符转换为某种格式之意。
正常情况下,一个Unicode两个字节,在转化uft-8的时候,根据协议,两个两个字节,对应一个uft-8这样完成转化或者称为映射!
其实在第0个平面中,专门有一个代理区域,不表示任何字符,只用于指向第1到第16个平面中的字符,这段区域是:D800——DFFF。其中0xD800——0xDBFF是前导代理(lead surrogates),0xDC00——0xDFFF是后尾代理(trail surrogates)。
一个代理对儿(前导,后尾),就表示一个utf-16的字符。就那emoji的微笑来说,前导是代理:D83D;后尾代理是:DE03。根据下图可以得出utf-16的值是:0x1-F603。这就照应上了。
具体的公式是:0x10000 + (前导-0xD800) * 0x400 + (后导-0xDC00) =utf-16编码。
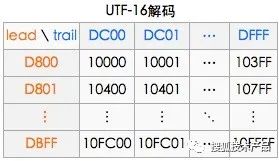
(图9)
笔者做一个形象的比喻:这对儿(前导代理,后尾代理)就像一个指针,指向了第1——16平面上的每一个码位。经过计算,不难得出:16个平面 * 每个平面码位65536 = 1,048,576个,前导X后尾代理,可以表示的码位也是1,048,576个(哈!真是一个完美的解决方案)如图9所示。
if(Unicode第一个字节 >=0xD8 && Unicode <=0xDB){
这是代理区域,表示第1——16平面的字符。每四个字节表示一个单元
}
else{
这是正常映射区域,表示第0个平面。每两个字节表示一个单元。
}Emoji并不都是四个字节。举个例子有些复杂表情会更长:比如👩👩👦👦,使用NSString标示时候:str.length 是11,data.length是25:他是由四个emoji组成的。只不过在编码的开始加入了特殊的控制字符。👩👩👦👦=👩+👩+👦+👦
NSString* str = @“👩👩👦👦”;
NSData* data = [str dataUsingEncoding:NSUTF8StringEncoding];
NSLog(@“emoji str-len:%d data-len:%d”,str.length,data.length);结果是:emoji str-len:11 data-len:25。
详细查看网站https://apps.timwhitlock.info/unicode/inspect
iOS 上实现显示汉字的 Unicode 和 UTF8 代码
主要思想:
使用NSString的方法dataUsingEncoding,参数可以选择NSUnicodeStringEncoding 和NSUTF8StringEncoding然后得到NSData;
如果用GBK需要自己生成一个NSStringEncoding,代替NSUTF8StringEncoding。
NSStringEncoding gbkEncoding =CFStringConvertEncodingToNSStringEncoding(kCFStringEncodingGB_18030_2000);NSData包含了首地址和长度。比如“联通”经过Unicode后是4个字节,UTF-8之后是6个字节,都可以从NSData中得到。然后,用char*指向NSSdata后,逐个将char打印出来就行。如下图所示:
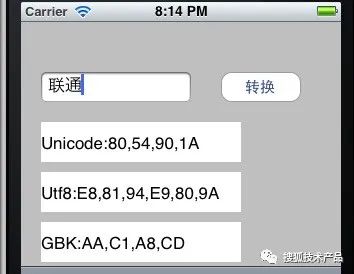
(图10)
注意:由于intel cpu是采用小端,所以如果不进行大端转换,视觉上是颠倒的,这里我已经给转成大端的了,大端即正常视觉模式。小故事:早期window电脑用记事本存储“联通”两个字,关闭再打开,显示乱码。原因就是windows默认保存的编码是ANSI(在中国是GB2312),而 “联”ANSI编码是 0xC1AA 二进制排列是 1100 0001 1010 1010;“通”ANSI编码是 0xCDA8 二进制排列是 1100 1101 1010 1000;开头是110开头,再次打开记事本,系统会使用utf8打开。就会异常。现在的操作系统会存储一个BOM,来表明是那种编码避免了乱码的问题。
GBK 简单介绍
GBK——专门为解决汉字的编码而生成的解决方案。那么,一个汉字究竟被存储为什么,就需要:先查unicode码表,然后根据在码表的位置进行计算。例如:“电”字,在码表中是3575,而在GB2312的码表中为B5E7。GBK的中文编码是双字节来表示的,英文编码是用ASCII码表示的,即用单字节表示。但GBK编码表中也有英文字符的双字节表示形式,所以英文字母可以有2种GBK表示方式。为区分中文,将其最高位都定成1。英文单字节最高位都为0。当用GBK解码时,若高字节最高位为0,则用ASCII码表解码;若高字节最高位为1,则用GBK码表解码。
编码方式:
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。具体来说,定义的是下列字节:
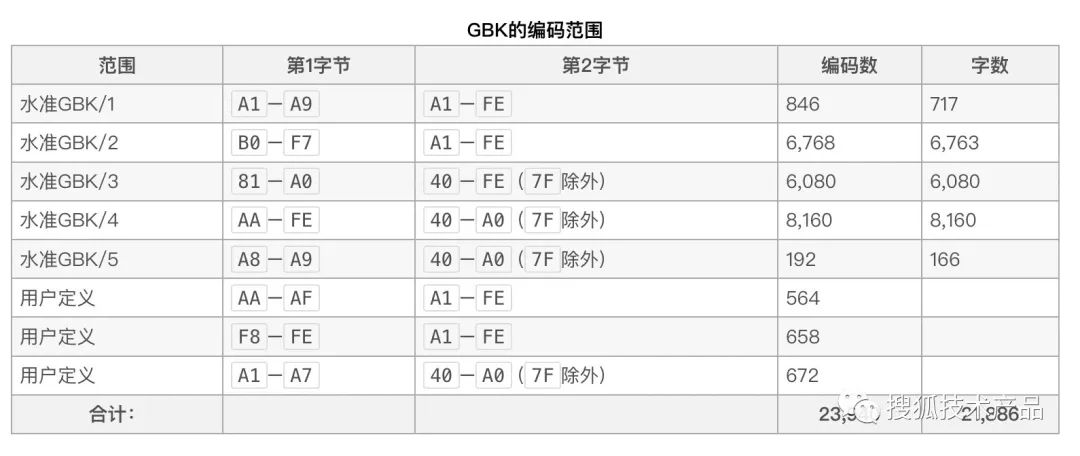
(图11)
双字节符号可以表达的64K空间如下图所示。绿色和黄色区域是GBK的编码,红色是用户定义区域。没有颜色的区域是不正确的代码组合:

(图12)
要点总结
GBK编码是GB2312编码的超集,向下完全兼容GB2312。GB18030编码向下兼容GBK和GB2312,GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换。GBK,GB2312以及Unicode都既是字符集,也是编码方式,而UTF-8只是编码方式,并不是字符集。















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









