










自注意力机制(self-attention)
介绍
-
当我们需要对一段文字进行处理的时候,我们需要将文字转变成一种可以放进神经网络里的形态
-
主流的有两种方法可以完成这个,就是以下两种方法
-
one-hot编码
-

-
word embedding
-
-
-
当我们将我们的词汇转变成了一个个的向量的时候,我们就可以将向量作为输入放入神经网络中进行训练了
-
那么我们会有什么样的输出呢?
-
有大概以下三种情况:
- 输入多少个向量就输出多少个标签,也就是输入和输出的长度是一样的
-

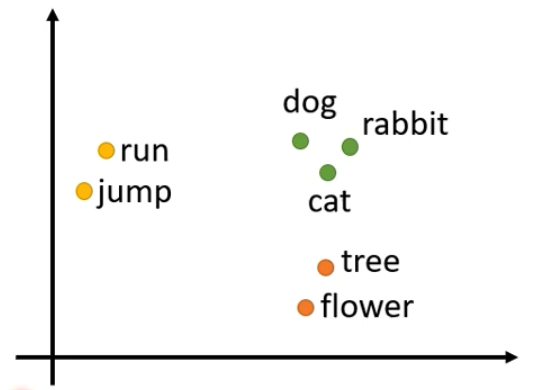
- 举例来说,词性标注:
-
- 可以看到每个单词都有对应着它的词性,也就是输入输出长度是一样的
-
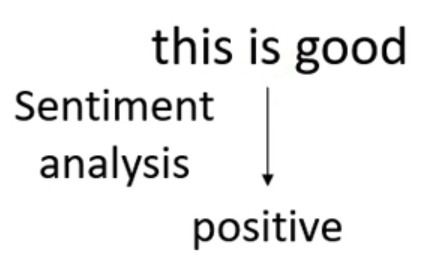
- 无论输入多少向量,都只输出一个标签
-

- 例如:情绪分析,也就是判断一句话是积极还是消极的
-
-
- 无论输入的向量有多少类,由机器来自行判别输出多少标签
-

- 例如:翻译任务
- 因为输入输出是不同的语言,所以他们之间的词汇肯定也不一样的
-
- 输入多少个向量就输出多少个标签,也就是输入和输出的长度是一样的
-
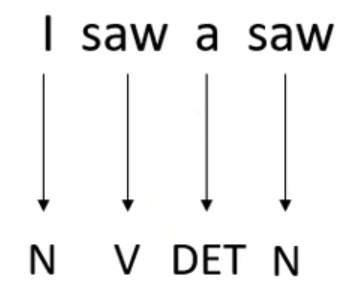
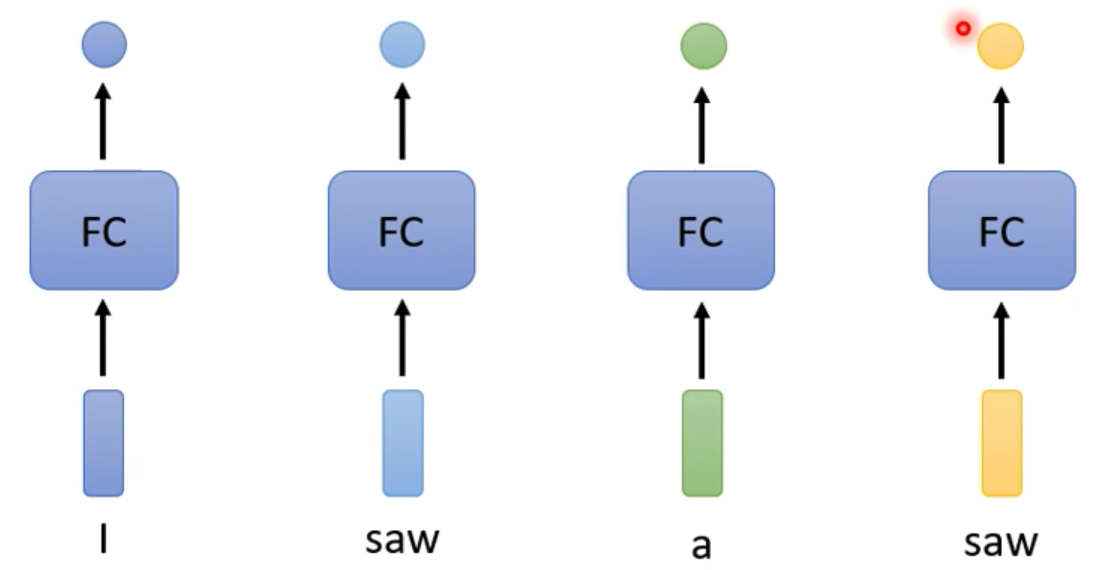
假如我们要做一个词性标注任务的时候,我们通过上述方法获取到了我们所要标注的序列的词向量表示,然后我们可以直接将这些词向量逐个放到全连接层去训练,最后神经网络会给出一个个的输出
-
-
但是这样有一个非常大的弊端,就是对于上图所示,可以看出第一个saw是动词,而第二个saw是名词,但是由于他俩长得一样,所以他俩的词向量按道理来说就应该是一样的,从而导致他俩的输出就是一样的,但是实际上,我们想要第一个saw输出动词,第二个saw输出名词
-
为了解决上述问题,所以这就要引出我们的注意力机制了
-
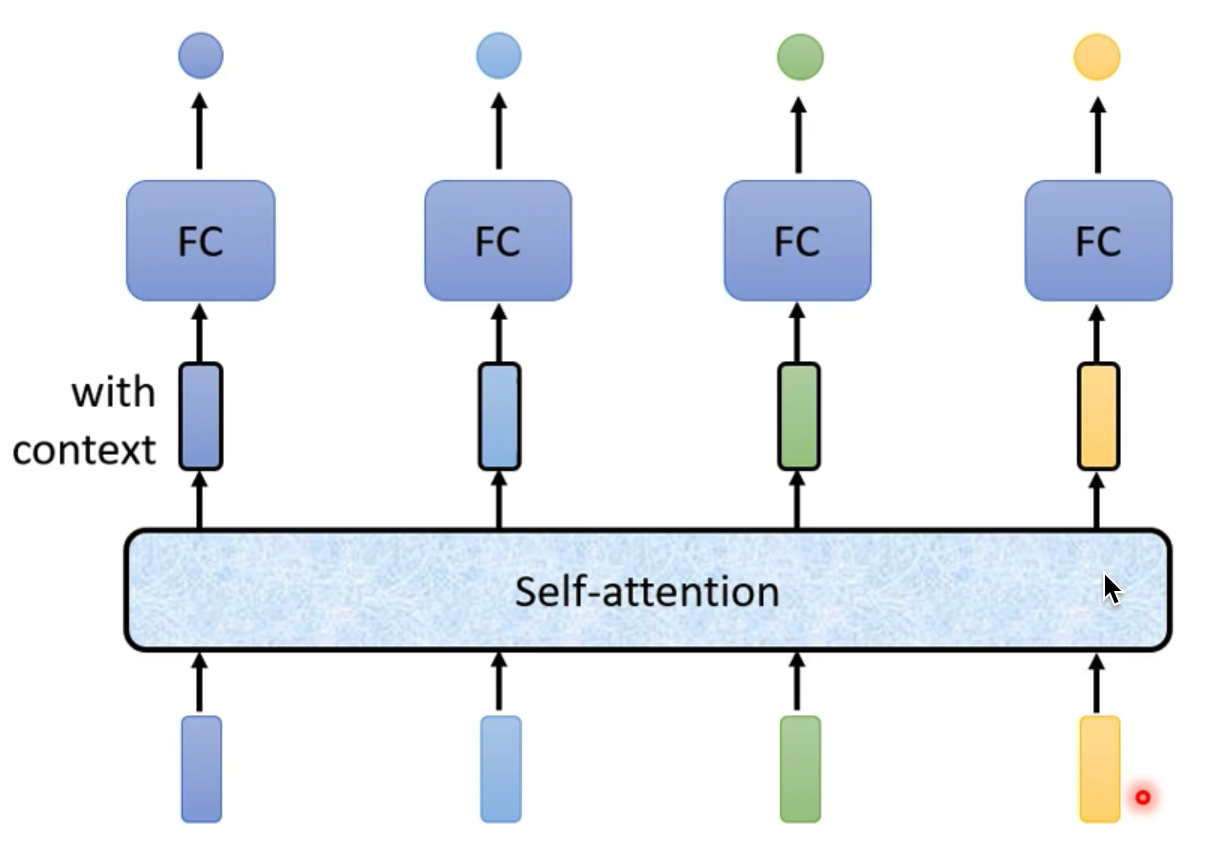
注意力机制在做什么呢?可以通过下图进行解释
-
-
当我们输入了一个向量,他会在考虑整个序列的情况下输出一个相对应的向量
-
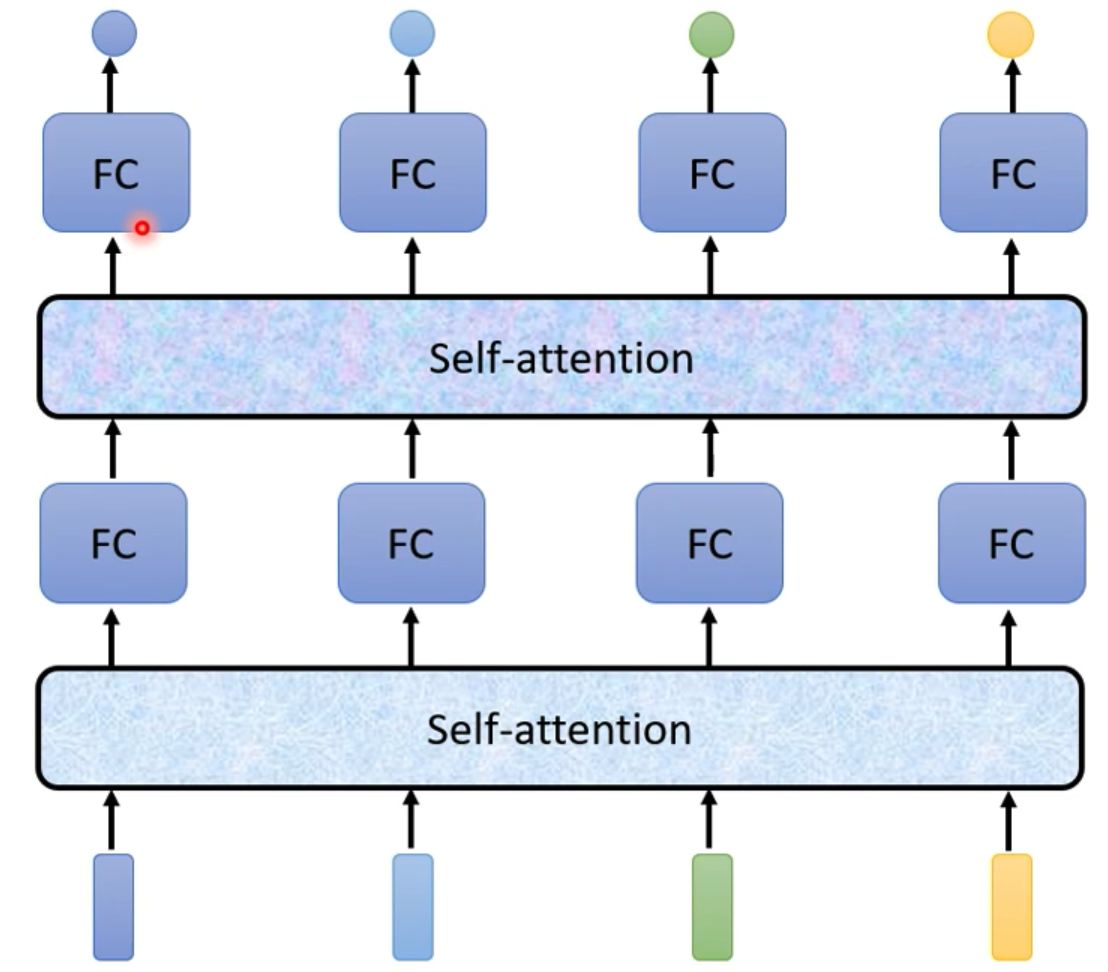
就像我们读书一样,我们在阅读的时候,读完全篇和只读到一半的时候对这本书的理解是不一样的,同理,我们也可以添加多个注意力机制的层,类比我们一本书读多遍一样,如下图所示
-
-
那么注意力机制这一层到底干了啥事捏?
具体运算
- 如下所示
-
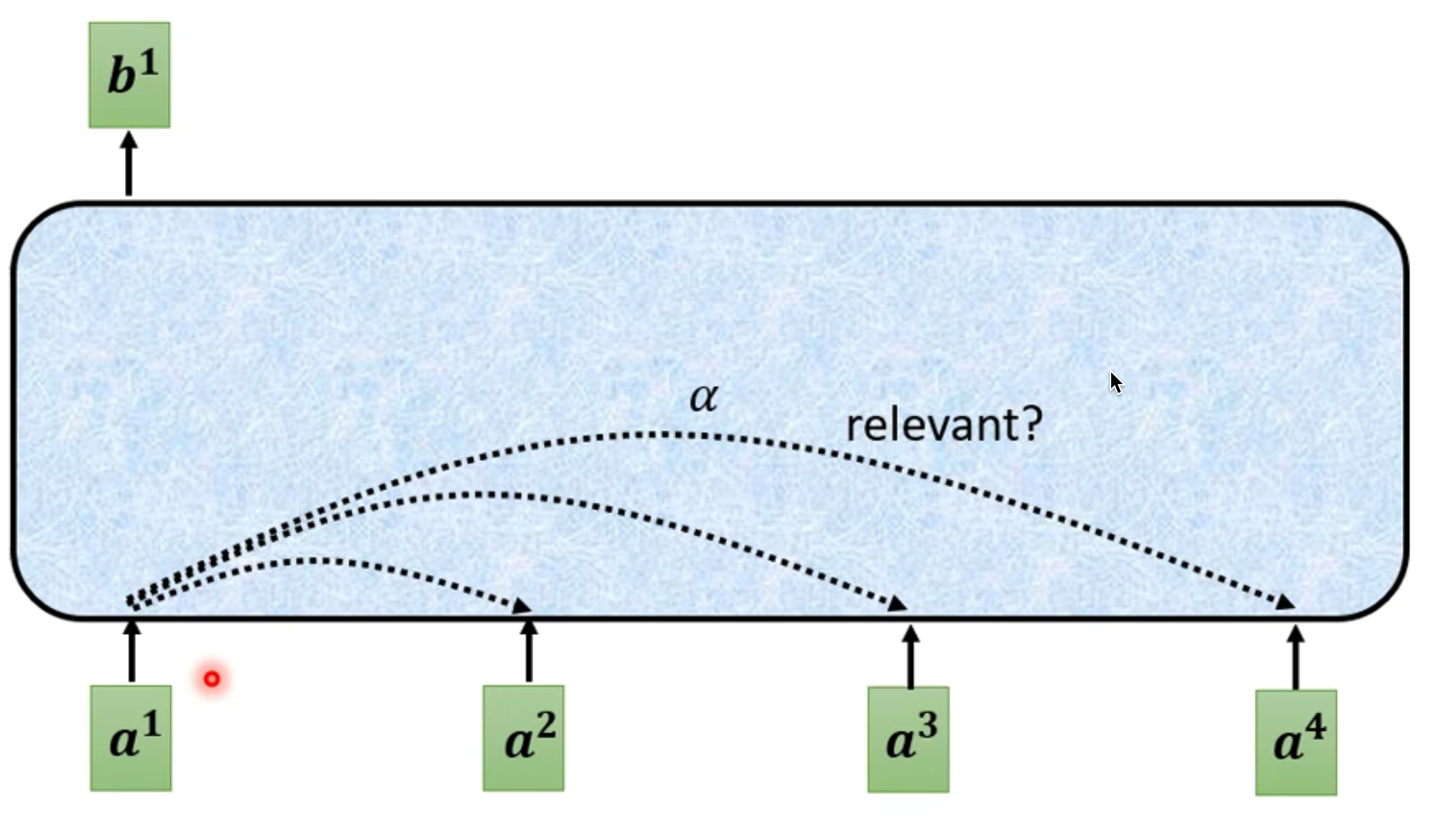
- 其中的a1,a2,a3,a4为我们的输入,b1是a1所对应的输出,也就是考虑了整个序列a1-a4才输出的对应a1的向量
- 假如我们要找出a1所对应的向量b1,那么我们就先得看a1-a4里哪些和a1相关,也就是哪些部分对a1来讲重要,哪些不重要,这个相关度用 α \alpha α来表示
- alpha有几种计算方法,举最常用的一种计算方法:Dot - product
-
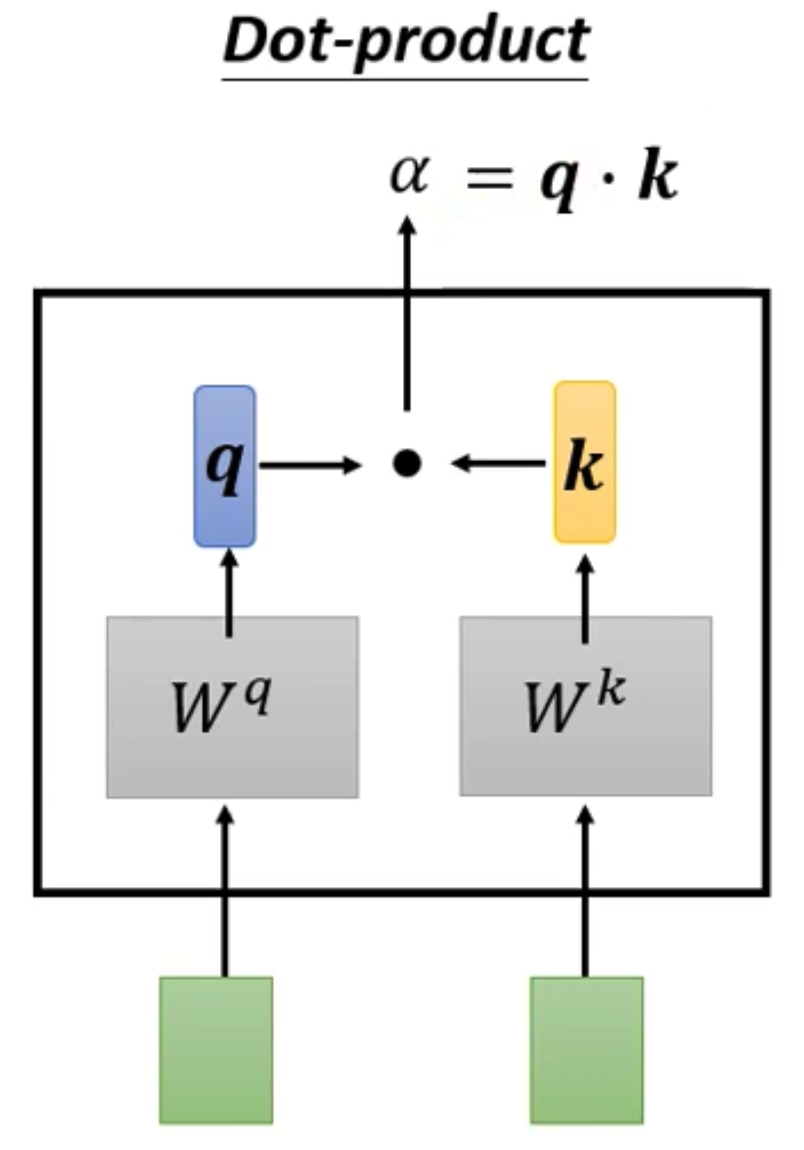
- 假如要计算两个向量的关联程度,那么就用该向量乘上一个Wq矩阵得出q,用另一个向量乘上wk矩阵得出k,再将q和k做一个内积运算,最后就能得出alpha
- 这里的wq和wk均为训练中得出的参数
-
- 用上述方法进行计算a1和其他所有向量的相关度,可得到下图
-
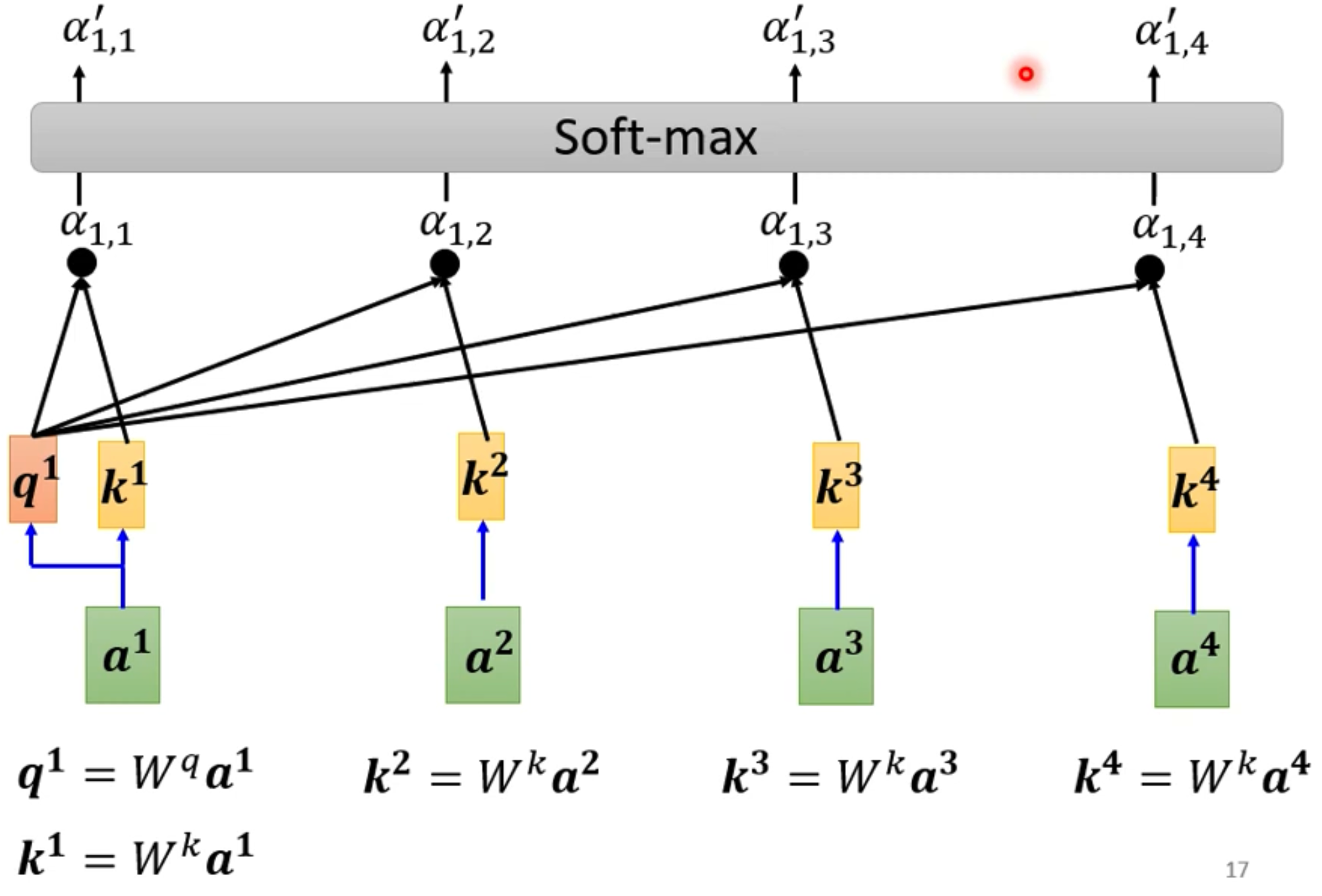
- 当求得a1对所有向量的相关度后,我们对它用一个softmax激活函数,用softmax激活函数的目的是为了表现出他们相关度的权重比例,也可以使用一些其他的激活函数,比如relu
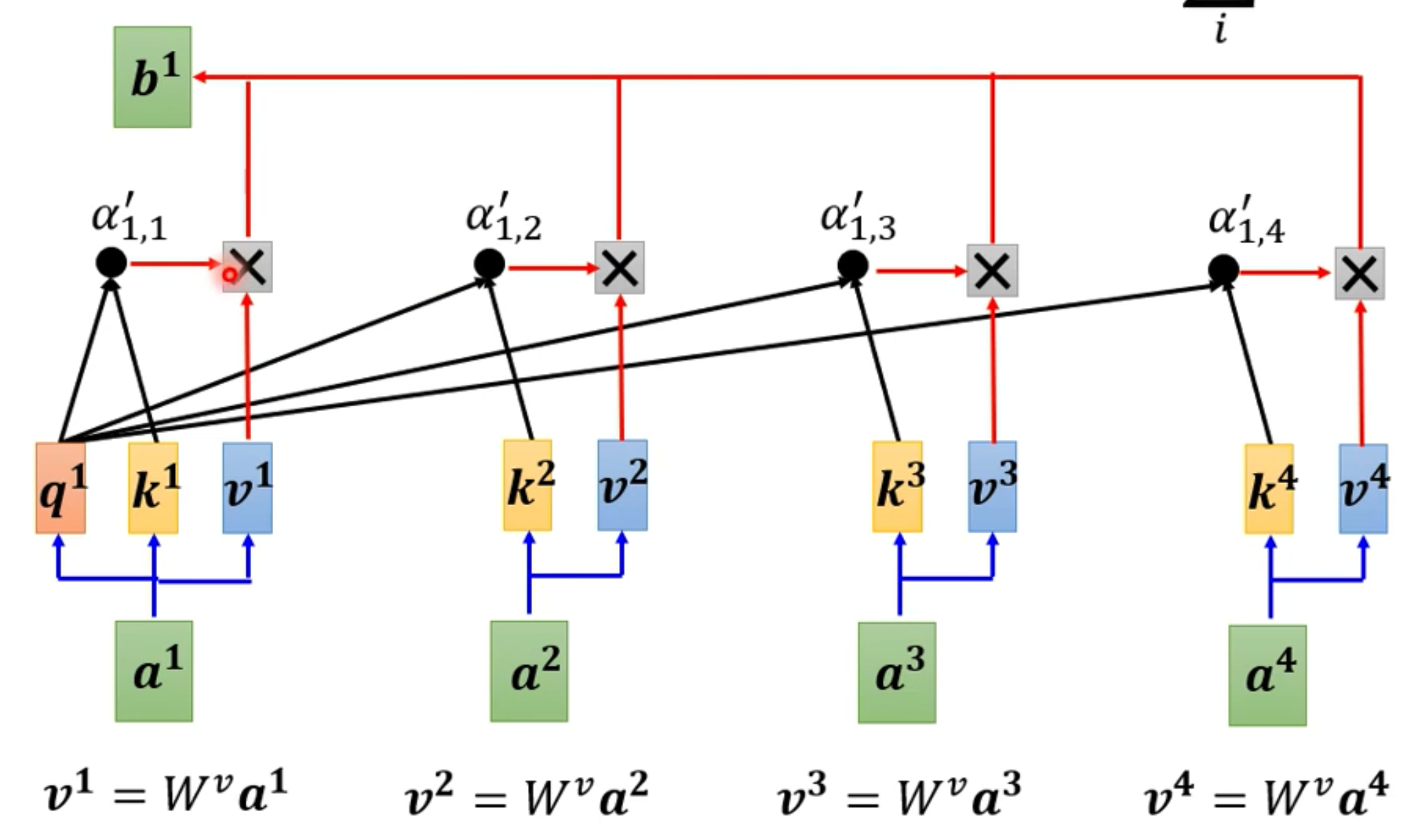
- 当我们做完上面步骤后,我们就可以知道哪些向量对a1相关性高,然后我们就可以通过alpha来抽取出重要的信息了
- 我们对每一个向量a1-a4创建出v1-v4向量, v 1 = W v a 1 , v 2 = W v a 2 , v 3 = W v a 3 , v 4 = W v a 4 v_1=W^va^1,v_2=W^va^2,v_3=W^va^3,v_4=W^va^4 v1=Wva1,v2=Wva2,v3=Wva3,v4=Wva4
- 然后将每一个v乘上alpha撇再全部进行相加,就能得出b1,也就是 b 1 = ∑ i α 1 , i ′ v i b^1=\sum\limits_i\alpha_{1,i}'v^i b1=i∑α1,i′vi
-
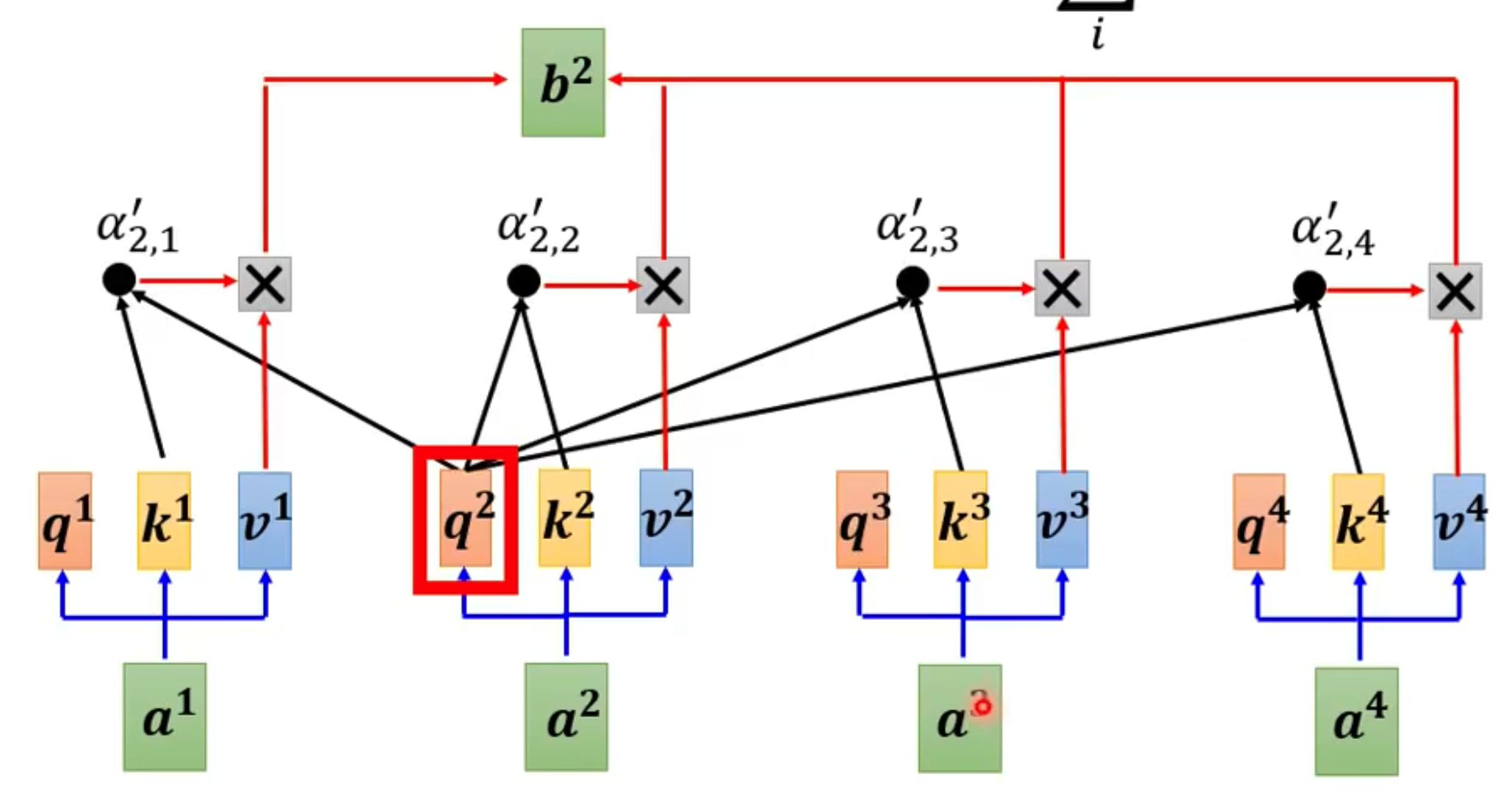
- 同理可得b2、b3、b4
-
self-attention向量化
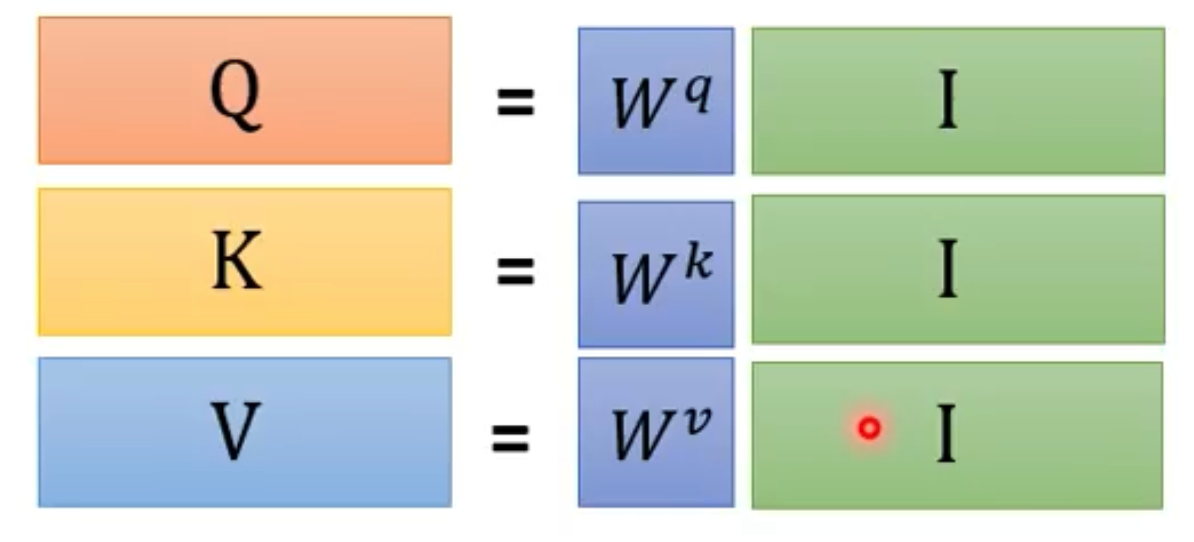
- 首先我们有三个需要训练的矩阵 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv
- 而且每个输入进来的词向量都有q, k, v
- 可以看到每一个q1-q4都是是由a1-a4分别乘上Wq矩阵得来的
- 于是我们可以将a1-a4放进一个矩阵I当中,然后用Wq*I就可以得到大矩阵Q,如下图所示
-
- 每个k和每个v同理
-
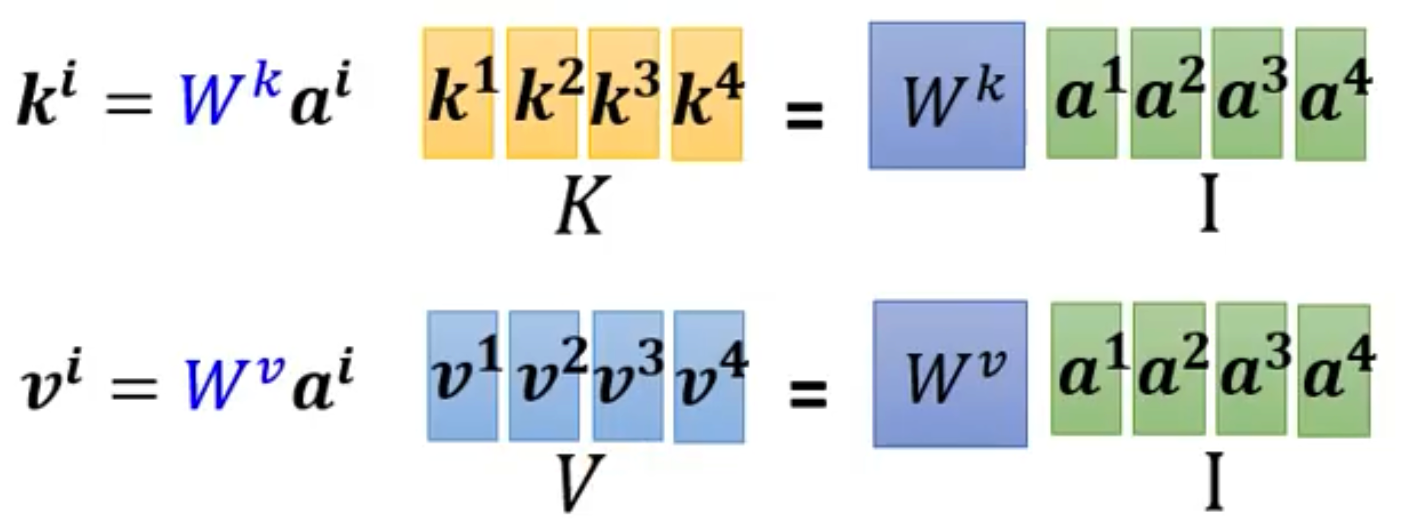
- 怎样一步计算出每个alpha呢
- 通过之前的方法求是这样子的
-
- 可以看到 α 1 , 1 − α 1 , 4 \alpha_{1,1}-\alpha_{1,4} α1,1−α1,4都是用q1乘上k1-k4,于是我们直接将K.T乘q1,于是就可以一步求出所有的 α 1 , 1 − α 1 , 4 \alpha_{1,1}-\alpha_{1,4} α1,1−α1,4
-
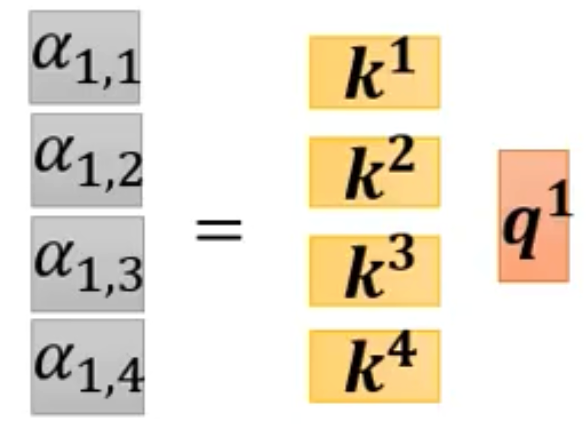
- 同理可得,如果用q2乘上k1-k4这个向量,最终会得到 α 2 , 1 − α 2 , 4 \alpha_{2,1}-\alpha_{2,4} α2,1−α2,4
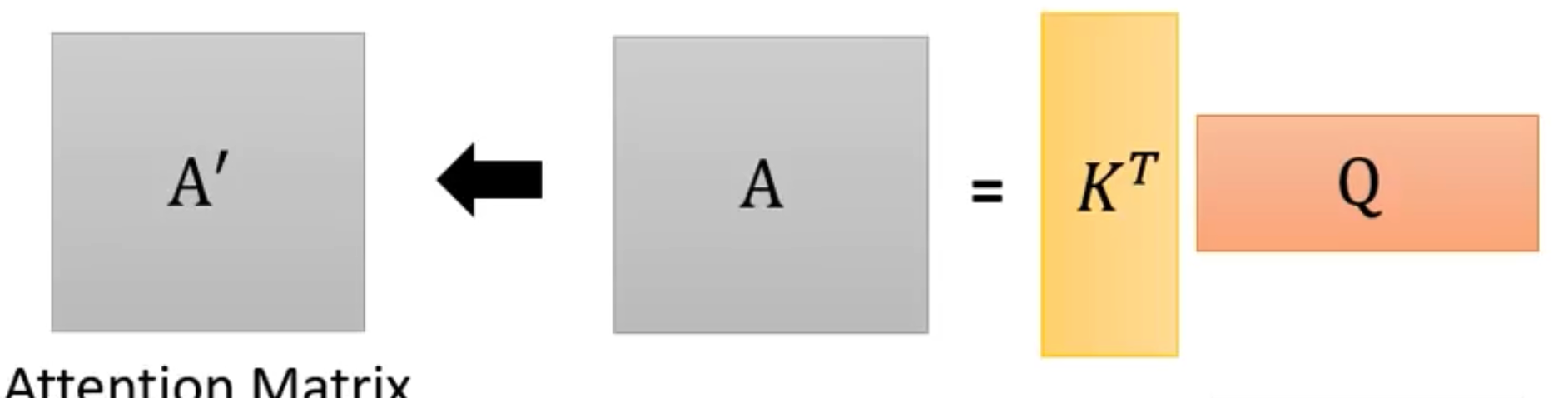
- 于是我们可以直接用K.T和Q做乘法,就得到了所有 α \alpha α矩阵,称它为A矩阵
- 由于一般算出来的A矩阵内的值会变的比较大,这样在后续计算过程中容易形成梯度消失,所以在这里会让A矩阵除上一个 d k \sqrt{d_k} dk,其中的dk是词向量的维度
- 再将该矩阵套入softmax激活函数当中,就能得到所有的代表相关度的权重比 A ′ A' A′矩阵了
-

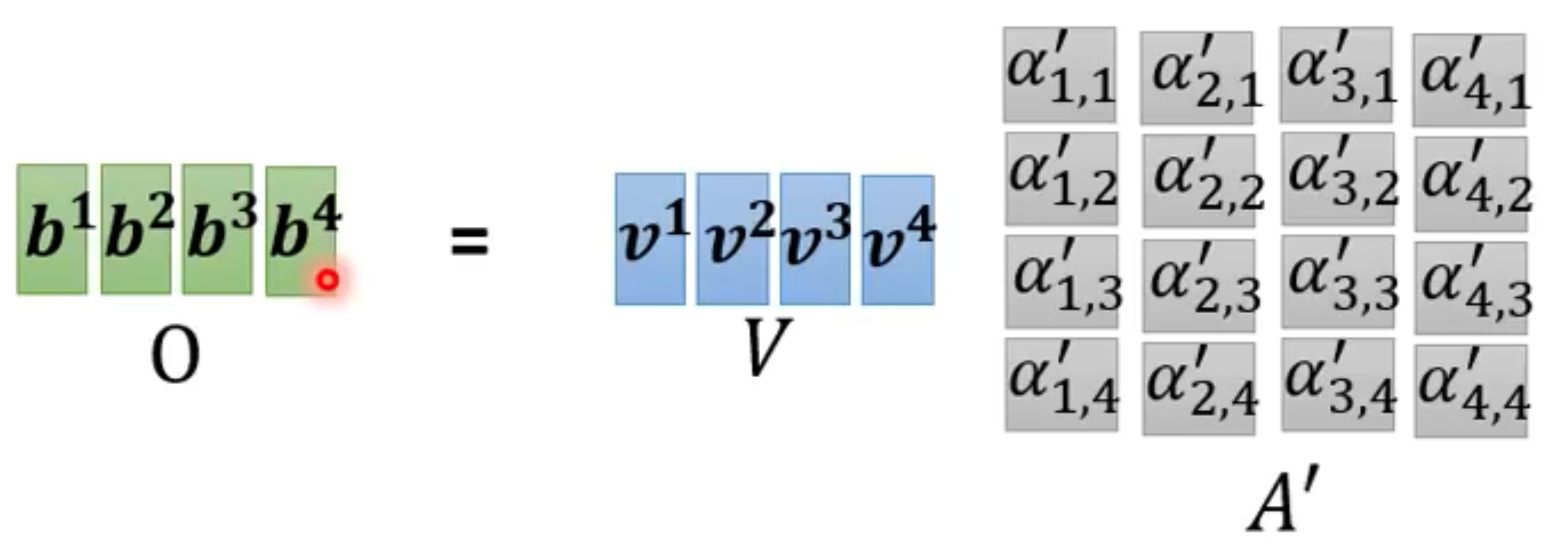
- 最后我们再将 A ′ A' A′和V乘起来就能得到我们I矩阵所对应的O,也就是a1-a4经过对整体序列进行学习后所输出的b1-b4
-
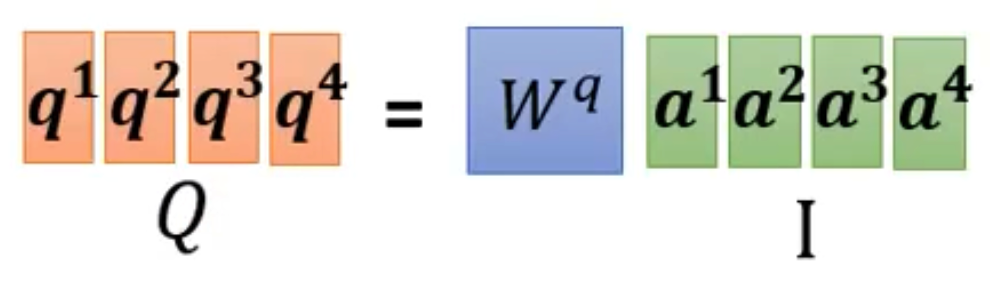

整体流程

对Q、K、V的通俗解释:
- 假如一个男生A,面对许多个潜在交往对象B1,B2,B3…,他想知道自己谁跟自己最匹配,应该把最多的注意力放在哪一个上。那么他需要这么做:
- 他要把自己的实际条件用某种方法表示出来,这就是Value
- 他要定一个自己期望对象的标准,就是Query
- 别人也有期望对象标准的,他要给出一个供别人参考的数据,当然不能直接用自己真实的条件,总要包装一下,这就是Key
- 他用自己的标准去跟每一个人的Key比对一下(Q*K),当然也可以跟自己比对,然后用softmax求出权重,就知道自己的注意力应该放在谁身上了
参考链接
- https://www.bilibili.com/video/BV1v3411r78R/?spm_id_from=333.337.search-card.all.click&vd_source=97163a4e6e2704667559fdbd58743862


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









