







Week9:Anomaly detection/Recommender Systems 异常检测/推荐系统
Anomaly detection 异常检测
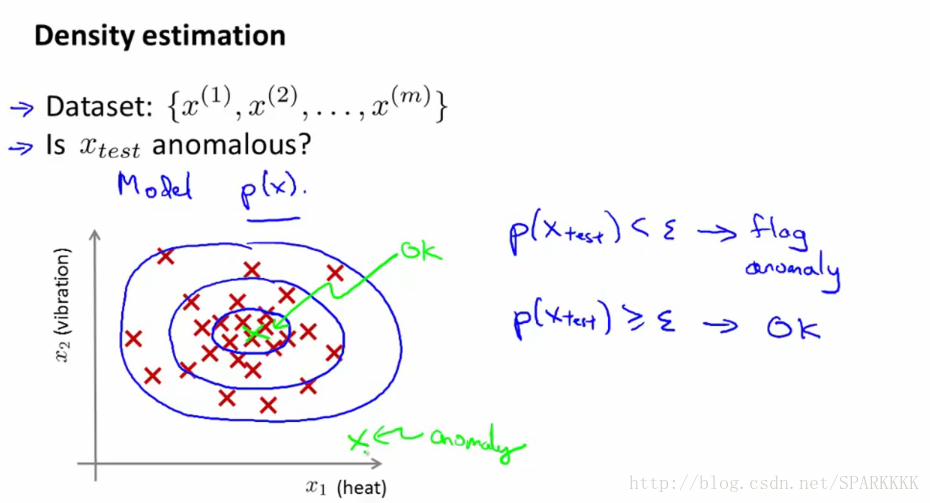
训练样本在中心的概率最大所以test如果在中心表明正常
Gaussian Distribution 高斯分布(正态分布)
设有m个训练集n个特征向量


开发和评价一个异常检测算法

因为数据是倾斜的(y=0正常样本的数目远大于y=1不正常样本),所以要用其他方法去检验算法的好坏
ϵ
是一个阈值,可以选择一个合适的
ϵ
使得F1-score的值最大
由于异常样本本来就是少量的
所以在训练集中只有正常样本,但在CVset和Testset里面有异常样本(少量)和正常样本
Anomaly Detection vs. Supervised Learning
使用异常检测的原因一般有
- 异常样本(y=1)特别少但是正常样本(y=0)特别多
- 异常样本的种类特别多,未来的异常可能与我们已见过的完全不同
使用监督学习的原因:正负样本的数量都特别多,算法可以判断样本的类别
特征向量的选择

让特征向量的数据看起来更像高斯分布
我们希望
p(x)
的值对于正常样本比较大,对于异常样本比较小。
但有时候
p(x)
的值对于正常异常样本都比较大,这个时候就需要添加特征向量
xi
(也可以把特征变量相组合得到新的特征变量,如
x4=x2x3
)去改变
p(x)
Multivariate Gaussian Distribution 多元高斯分布
用一个
p(x)
模型,而不是建立多个
p(xi)
模型
协方差矩阵非对角线元素非0时表明向量之间有线性关系





p(x)<ϵ 时标记为异常
多元高斯分布模型与原来的模型的关系:
Original model的等高线是沿轴线方向的,即其协方差矩阵的非对角线上元素均为0,如下图

即原来的模型是多元高斯分布模型的一个特例
多元高斯分布模型可以自动捉到特征向量之间的线性关系,但在n的值特别大的时候计算效率比较低,而且要求 样本数m > 特征向量数n( Σ 才可逆)(一般得有m远大于n的时候才用多元高斯分布模型 m≥n)
注意 Σ 必须可逆,即满足可逆矩阵性质
原来的模型在样本数m小的时候也可以运行
Recommender Systems 推荐系统
Content-Based Recommender Systems 基于内容的推荐系统
根据内容确定特征向量权值并根据用户对这些特征的喜好程度进行加权然后预测
例子和算法见https://www.coursera.org/learn/machine-learning/lecture/uG59z/content-based-recommendations
(其实没有什么新内容)
Collaborative Filtering 协同过滤
这个算法能够自行学习所要使用的特征,其实就是根据用户的喜好和评分反推特征向量的值

r(i,j)=1
代表第j名用户对第i部电影评过分
协同过滤优化目标

协同过滤算法实现

低秩矩阵分解

nu
为用户数,
nm
为电影数

链接:矩阵低秩分解理论
低秩矩阵是指一个高阶矩阵的秩很小,也就是可以用较少的基底数量逼近原来的矩阵
5部和i电影最相似的电影, find the 5 movies j with the smallest ||x(i)−x(j)||
先对矩阵中的评分进行均值归一化,有时候会取得更好的预测结果















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









