










图的数据结构(自定义的点加线实现的图结构)
利用点线的组合来实现图的结构,优势就是结构清晰,容易理解,表达的数据项多。便于很多图的算法。
具体实现可以查看上期连接
自定义图结构
自定义图结构的代码
/**
* 线
*/
public class Edge {
/**
* 线的权重
*/
private int weight;
/**
* 这个是点的结构 先理解为头节点
*/
private Node from;
/**
* 理解为尾节点或者出节点。
*/
private Node to;
public Edge(int weight, Node from, Node to) {
this.weight = weight;
this.from = from;
this.to = to;
}
}
/**
* 点的数据结构
*/
public class Node {
public int value;
//出度
public int out;
//入度
public int in;
//边的集合(这个点的所有线段集合)
public ArrayList<Edge> edges;
//点的集合(从这个点往下能走到的点)
public ArrayList<Node> nests;
public Node(int value) {
this.value = value;
in = 0;
out = 0;
edges = new ArrayList<>();
nests = new ArrayList<>();
}
}
/**
* 图结构
*/
public class Graph {
public HashMap<Integer,Node> nodes;
public List<Edge> edges;
public Graph() {
this.nodes = new HashMap();
this.edges = new ArrayList();
}
}
广度优先遍历
思路:
类似二叉树的按层遍历。在图中遍历时,我们把当前节点放进队列中,然后弹出后,判断有没有直接子节点,有的话继续压入队列中。
和二叉树遍历的区别是:图中有可能有回路,会跑到重复节点,所以需要增加一个新的HashSet表进行去重。
代码实现
/**
* 宽度优先遍历
* @param start
*/
public static void bfs(Node start){
if (start == null){
return;
}
Queue<Node> queue = new LinkedList<>();
//记录已经遍历过的节点
HashSet<Node> set = new HashSet<>();
queue.add(start);
set.add(start);
while (!queue.isEmpty()){
Node poll = queue.poll();
System.out.println(poll.value);
//去重
for (Node cur : poll.nests){
if (!set.contains(cur)){
queue.add(cur);
set.add(cur);
}
}
}
}
深度优先遍历
深度优先遍历有点类似于前序遍历,是从图的某一顶点开始遍历,被访问过的顶点就做上已访问的记号,接着遍历此顶点的所有相邻且未访问过的顶点中的任意一个顶点,并做上已访问的记号,再以该点为新的起点继续进行深度优先遍历
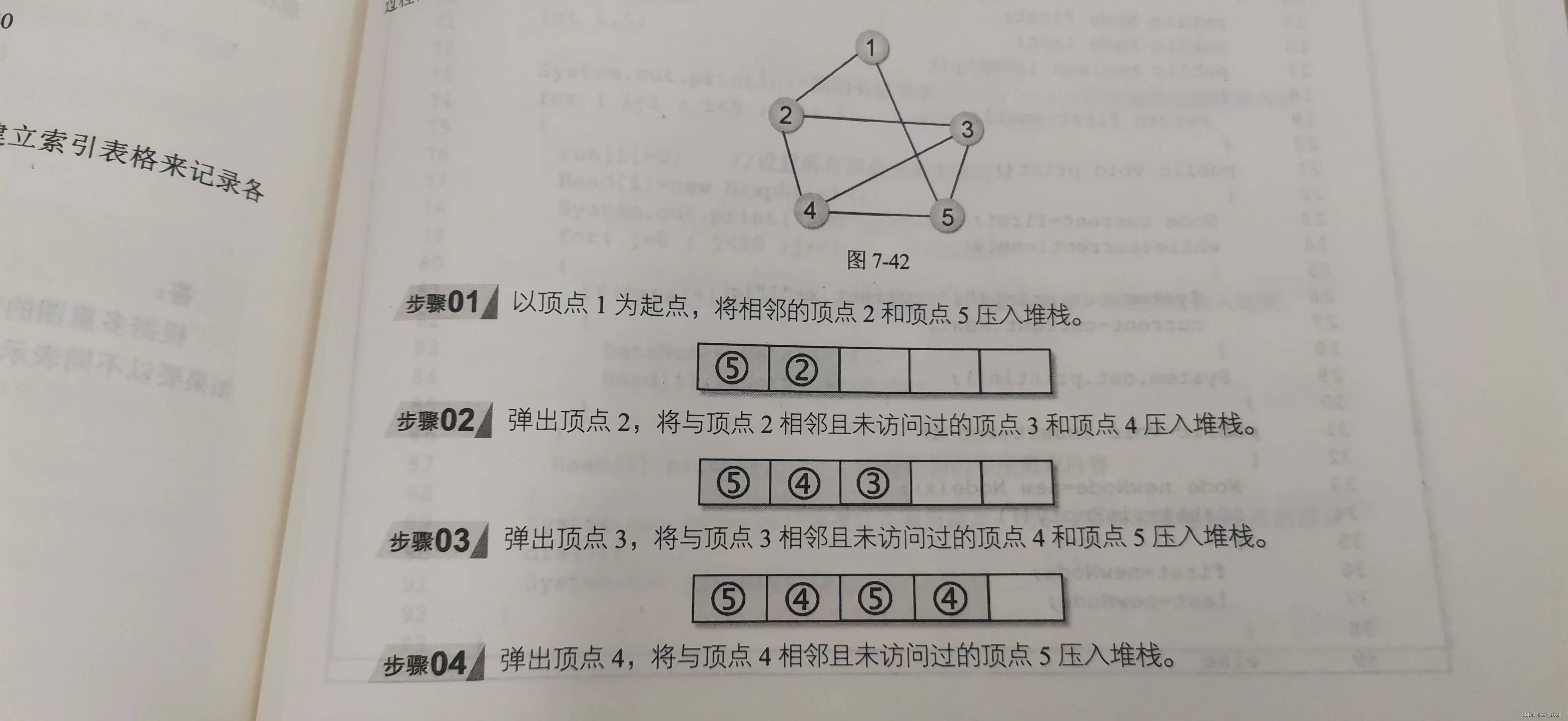
/**
* 深度优先遍历
* @param start
*/
public static void dfs(Node start){
if (start == null){
return;
}
Stack<Node> stack = new Stack<>();
//辅助 为了帮助去重
HashSet<Node> set = new HashSet<>();
stack.push(start);
set.add(start);
System.out.println(start.value);
while (!stack.isEmpty()){
Node cur = stack.pop();
for (Node next : cur.nests){
if (!set.contains(next)){
//发现下面还有节点,就重新压入 是的stack 里保持有一条完整的链。
stack.push(cur);
stack.push(next);
System.out.println(next.value);
set.add(next);
break;
}
}
}
}














 3664
3664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









