







一、MapReduce主要流程
概述:MapReduce计算模式将数据的计算过程分为两个阶段即Map和Reduce分别对应两个处理函数:map和reduce。map阶段过滤和转换数据(转换原始key和value值,将一定数量的具有相同key的value合并在一组中,按照key,values的形式传递给reduce进行处理)。reduce阶段处理map阶段的输出数据。迭代values,将每组的计算结果写回到容器中以待后续合并。多个map和reduce并行运算。当所有结果计算完成后,合并结果得到最终结果。
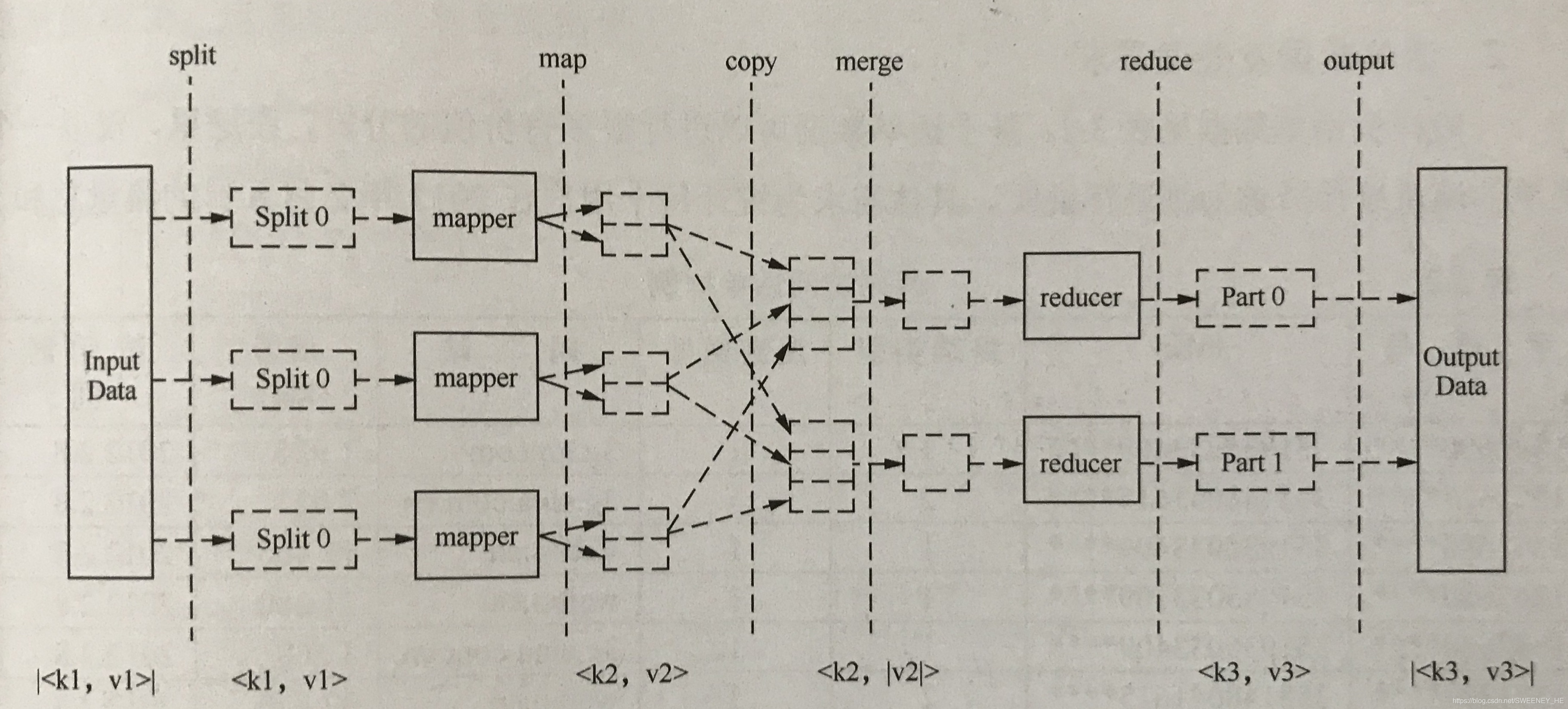
解释下图内容:
#1.split是一个逻辑上的划分可以由非整数块个block组成
#2.一个split对应一个mapper
#3.MapperReducer以键值对作为基础数据单元
#4.相同key的数据只能在一个reduce中处理,一个reduce可以处理多个不同key的数据
#5.mapper阶段接收的是<key,values>一个key对应多个value的键值对
二、代码实现
案例:查找每个月天气温度最高的两天
1.定义主类提交作业
package myclimateTry;
import myclimate.Climate;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Myclimate {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//加载配置
Configuration configuration = new Configuration();
//实例化作业
Job job = Job.getInstance(configuration);
//设置作业类
job.setJarByClass(Myclimate.class);
//设置作业名称
job.setJobName("climate");
//设置输入文件路径(HDFS中的路径)
Path inPath = new Path("/myclimate.txt");
FileInputFormat.addInputPath(job, inPath);
//设置输出文件路径(HDFS中的路径)
Path outPath = new Path("/myclimate");
FileOutputFormat.setOutputPath(job, outPath);
//设置map
job.setMapperClass(MyClimateMapper.class);
//设置map传递的参数类型
job.setOutputKeyClass(Climate.class);
job.setOutputValueClass(IntWritable.class);
//自定义模块:
//自定义排序比较器
job.setSortComparatorClass(MySortComparator.class);
/* //自定义分组界限
job.setGroupingComparatorClass();
//自定义任务数量
job.setNumReduceTasks(1);*/
//设置reduce
job.setReducerClass(MyCliamteReducer.class);
//提交作业
job.waitForCompletion(true);
}
}
2.定义排序类对气温进行排序处理
package myclimate;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/***
* 实现日期正序,温度倒序
*/
public class CSortComparator extends WritableComparator {
private Climate climate1 = null;
private Climate climate2 = null;
public CSortComparator(){
super(Climate.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
climate1 = (Climate)a;
climate2 = (Climate)b;
int c1 = Integer.compare(climate1.getYear(),climate2.getYear());
if(c1==0){
int c2 = Integer.compare(climate1.getMonth(),climate2.getMonth());
if(c2==0){
return -Integer.compare(climate1.getTemperature(),climate2.getTemperature());
}
return c2;
}
return c1;
}
}
3.自定义Mapper类覆写map方法
package myclimate;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
public class ClimateMapper extends Mapper<LongWritable, Text,Climate, IntWritable> {
//实例化自定义key类型和value类型
private Climate climate = new Climate();
private IntWritable cVal = new IntWritable();
//第一个参数:LongWritable:长整型,原始key是文件中每列的列号
//第二个参数:Text:字符串,原始value是文件每列的所有内容
//第三个参数:context:容器,是map和reduce操作的载体
//map主要工作:
//1.根据需求确定key和value
//2.分组和排序便于reduce处理
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
//分割key和value
String[] strings = StringUtils.split(value.toString(), '\t');
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date date;
Calendar cal = Calendar.getInstance();
try {
//解析时间并填充到自定义天气类中
date = simpleDateFormat.parse(strings[0]);
cal.setTime(date);
climate.setYear(cal.get(Calendar.YEAR));
climate.setMonth(cal.get(Calendar.MONTH)+1);
climate.setDay(cal.get(Calendar.DAY_OF_MONTH));
} catch (ParseException e) {
e.printStackTrace();
}
String c = strings[1].substring(0, strings[1].indexOf("c"));
int cI = Integer.parseInt(c);
climate.setTemperature(cI);
cVal.set(cI);
//传递自定义参数给mapper
context.write(climate,cVal);
}
}
4.自定义Reduce类覆写reduce方法
package myclimate;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CReducer extends Reducer<Climate, IntWritable, Text, IntWritable> {
private Text tkey = new Text();
private IntWritable tval = new IntWritable();
//第一个参数:map处理后的key类型
//第二个参数:map分组后的一组value值
//第三个参数:context容器
//reduce工作:在组内进行计算
@Override
protected void reduce(Climate key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int flag = 0;
int day = 0;
for (IntWritable value : values) {
if (flag == 0) {
tkey.set(key.toString());
tval.set(value.get());
context.write(tkey, tval);
flag++;
day = key.getDay();
}
if (flag > 0 && day != key.getDay()) {
tkey.set(key.toString());
tval.set(value.get());
context.write(tkey, tval);
return;
}
}
}
}
5.自定义天气类
package myclimate;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//需要排序,实现WriatebleComparable接口
public class Climate implements WritableComparable<Climate> {
private int year;
private int month;
private int day;
private int temperature;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
public int getTemperature() {
return temperature;
}
public void setTemperature(int temperature) {
this.temperature = temperature;
}
@Override
public int compareTo(Climate o) {
int c1 = Integer.compare(this.getYear(), o.getYear());
if (c1 == 0) {
int c2 = Integer.compare(this.getMonth(), o.getMonth());
if (c2 == 0) {
return Integer.compare(this.getDay(), o.getDay());
}else
return c2;
}
return c1;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(this.getYear());
dataOutput.writeInt(this.getMonth());
dataOutput.writeInt(this.getDay());
dataOutput.writeInt(this.getTemperature());
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.setYear(dataInput.readInt());
this.setMonth(dataInput.readInt());
this.setDay(dataInput.readInt());
this.setTemperature(dataInput.readInt());
}
public String toString(){
return this.getYear()+"-"+this.getMonth()+"-"+this.getDay();
}
}
三.MapReduce高可用配置
#1. core.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node0002:2181,node0003:2181,node0004:2181</value>
</property>
</configuration>
#2. hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node0001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node0002:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node0001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node0002:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node0001:8485;node0002:8485;node0003:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/software/hadoop/jorunaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
#3.mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>
#4.yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node0003</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node0004</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node0002:2181,node0003:2181,node0004:2181</value>
</property>
</configuration>
四、数据及结果
测试数据:
1949-10-01 14:21:02 34c
1949-10-01 19:21:02 38c
1949-10-02 14:01:02 36c
1950-01-01 11:21:02 32c
1950-10-01 12:21:02 37c
1951-12-01 12:21:02 23c
1950-10-02 12:21:02 41c
1950-10-03 12:21:02 27c
1951-07-01 12:21:02 45c
1951-07-02 12:21:02 46c
1951-07-03 12:21:03 47c
输出结果:
1949-10-1 38
1949-10-2 36
1950-1-1 32
1950-10-2 41
1950-10-1 37
1951-7-3 47
1951-7-2 46
1951-12-1 23


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









