







文章说明
- 需要注意的地方会用黄色高光标注
- 文章中用到的一些知识,我会选择性提供文章链接,可考率是否阅读。
(一)初步了解搭建步骤
准备工作
1.虚拟机准备
准备好三台安装好jdk和hadoop的虚拟机
方法:可以克隆1台干净的虚拟机,做完所有jdk、hadoop配置后,将处理好的虚拟机克隆为集群,别忘了修改集群机器的IP和主机名
如何更改用户名和主机名入口
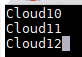
我这里用的是3台机器,分别为Cloud10、Cloud11、Cloud12
如有需要请参考文章
如何快速克隆虚拟机入口
如何安装jdk和hadoop入口
2.全分布的必要准备ssh免密登录
要先关闭防火墙
关闭防火墙命令
sudo service iptables stop
- ssh免密登录,是远程拷贝数据的前提,方便全分布的快速操作
SSH免密登录文章入口
核心工作
3.编辑8个配置文件
4.启动并测试集群
(二)详细步骤(从3.配置文件开始,)
1.集群部署规划
了解部署规划后,可以对照相应配置文件的内容,检查集群启动后节点分配是否正确

2.编辑配置文件(我在Cloud10机器下配置的这8个文件)
注意:全分布需要编辑8个文件,路径是~/software/hadoop/etc/hadoop,然后将一台机器配置好的这些文件,用scp命令远程拷贝到其他机器上。
以下是8个配置文件的名称及配置的内容
hadoop-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
core-site.xml //用于指定namenode节点的位置,Hadoop运行时产生文件所存储的mulu
hdfs-site.xml //指定hdfs的副本数和secondarynamenode的位置
slaves //用于指定组成机器的主机名
yarn-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
yarn-site.xml //用于指定reducer获取数据的方式、指定resourcemanager的位置
mapred-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
mapred-site.xml //指定mr在yarn上运行
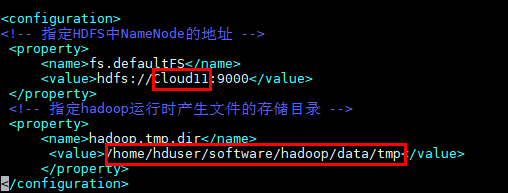
(1)core-site.xml
注:/data/tmp 目录如不存在,则先mkdir手动创建。(为了存放haddop运行生成文件的存储目录)
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Cloud11:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/software/hadoop/data/tmp</value>
</property>
</configuration>
- Hdfs部分

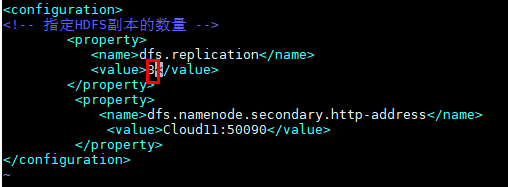
(3)hdfs-site.xml
HDFS副本的数量与机器数一样
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Cloud11:50090</value>
</property>
</configuration>
(4)slaves
- yarn部分
(5) yarn-env.sh

(6)yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Cloud10</value>
</property>
</configuration>

- mapreduce部分
(7)mapred-env.sh

(8)mapred-site.xml
先将模板mapred-site.xml.template 复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
然后编辑内容如下
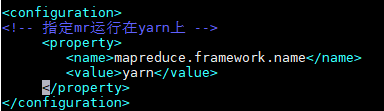
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
然后把上面的配置文件远程拷贝到集群其他机器
在这个路径下输入scp命令

scp -r hadoop hduser@Cloud11:~/software/hadoop/etc
scp -r hadoop hduser@Cloud12:~/software/hadoop/etc
温馨提示
至此,操作步骤已完成,请确保:
1.jdk和Hadoop安装、配置工作做好了
2.三台机器互相免密登录
3.三台机器的配置文件更改完成
3.启动并测试集群
如果集群是第一次启动,需要格式化namenode(不要经常格式化,不然你的集群的ID 就会发生改变,修改很麻烦)
bin/hdfs namenode -format

(1)启动HDFS
start-dfs.sh

(2)启动yarn
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn
start-yarn.sh

(3)分别 jps 命令测试三台机器是否都启动。
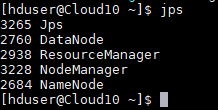
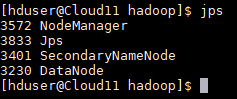
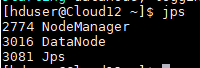
- 查看hadf的webui界面
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









