






mAP
mAP 全称是 mean Average Precision. 其中 mean 这个操作是在 class 级别上, 因此只需要将所有类别平均即可. 所有需要关注的就是 AP. AP 是 Precision-Recall 曲线和坐标轴围成的面积. 提到曲线可能会感觉比较懵 – 模型的预测对或者不对都是确定的, 哪里来的曲线呢?
想要搞明白为什么有曲线, 得看模型的预测结果. 一般来说, 模型在给出类别的预测的时候, 都会有一个置信度 p p p 表示属于这一类的概率. 因此我们就可以设定一个阈值 t t t, 如果 p > t p>t p>t, 认为属于预测类 L \boldsymbol{L} L, 如果 p ≤ t p \leq t p≤t 认为不属于 L \boldsymbol{L} L. 因此当我们设定不同的 t t t 的时候, 得到的 Precision 和 Recall 就会不同.
取不同的值, 就可以得到不同的 Precision, 可以写成函数 P = g ( t ) P = g(t) P=g(t), 正式来说 g ( t ) g(t) g(t) 就是 Precision 曲线, 横坐标是阈值 t t t, 纵坐标是对应的 Precision. 同理也可以得到 Recall 曲线, 表示为 R = f ( t ) R = f(t) R=f(t), f ( t ) f(t) f(t) 是单调递减的. 所以 P = g ( f − 1 ( R ) ) P = g(f^{-1}(R)) P=g(f−1(R)), 这就是 Precision-Recall 曲线.
数据集只有有限个样本, 这种情况下如何得到 Precision-Recall 曲线呢?
数据集只有有限个样本(
N
N
N), 每个样本都会得到一个置信度
p
p
p. 按照置信度排序之后, 我们就可以知道当阈值
t
t
t 精确地设定为
p
i
p_i
pi 的时候对应的 Precision 和 Recall, 这样也就得到了
N
N
N 个 Precision - Recall 点对. 如下所示:
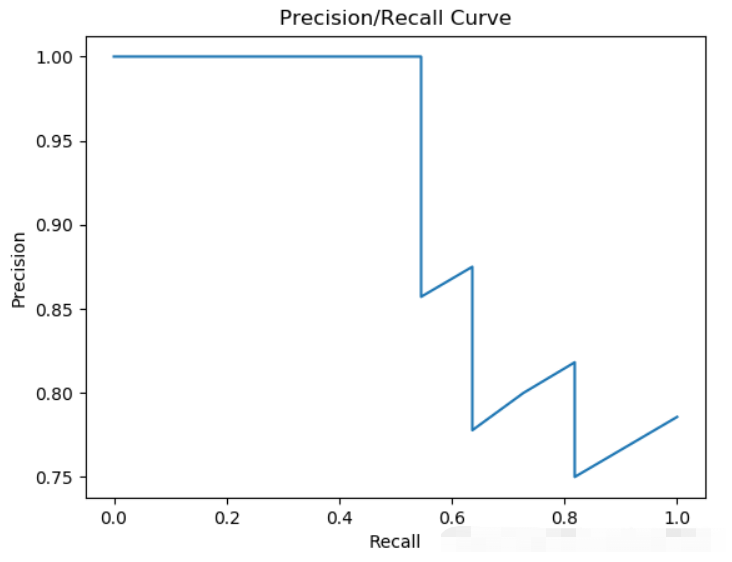
下面是实现的代码, 有些 trick 需要仔细理解.
class BBox(object):
def __init__(self, img_name, bbox, conf):
self.name = img_name
self.bbox = bbox
self.conf = conf
@staticmethod
def IoU(bbox_a, bbox_b):
bbox_a = bbox_a.bbox
bbox_b = bbox_b.bbox
area1 = (bbox_a[0] - bbox_a[2]) * (bbox_a[1] - bbox_b[3])
area2 = (bbox_b[0] - bbox_b[2]) * (bbox_b[1] - bbox_b[3])
tx = min(bbox_a[0], bbox_b[0])
ty = min(bbox_a[1], bbox_b[1])
bx = max(bbox_a[2], bbox_b[2])
by = max(bbox_a[3], bbox_b[3])
inter_area = (bx - tx) * (by - ty)
return inter_area / (area1 + area2 - inter_area)
def compute_AP(prds, gts, IoU_threshold=0.5):
"""给定预测和ground truth 计算AP值
Args:
prds (List[]): 模型预测结果
gts (_type_): 真值
IoU_threshold (float, optional): _description_. Defaults to 0.5.
"""
# sort the prds using conf
prds = sorted(prds, key=lambda x: x.conf, reverse=True)
# collect the gts
name2gt_idx = dict()
for i, gt in enumerate(gts):
name2gt_idx[gt.name] = name2gt_idx.get(gt.name, []) + [i]
# compute the TP and FP
TP = np.zeros(len(prds))
FP = np.zeros(len(prds))
# initial used_gt
used_gt = np.zeros(len(gts))
for pred_idx, prd in enumerate(prds):
gt_idxs = name2gt_idx[prd.name]
# find the gt with max iou
max_iou_idx = -1
max_iou = 0
for gt_idx in gt_idxs:
gt = gts[gt_idx]
# 如果这个GT bbox已经使用过, 跳过
if used_gt[gt_idx]:
continue
iou = BBox.IoU(gt, prd)
if iou > IoU_threshold and iou > max_iou:
max_iou = iou
max_iou_idx = gt_idx
if max_iou_idx != -1:
TP[pred_idx] = 1
# 标记这个GT bbox已经使用, 下次不能匹配这个GT bbox
used_gt[max_iou_idx] = 1
else:
FP[pred_idx] = 1
# compute the AP
acc_TP = np.cumsum(TP)
acc_FP = np.cumsum(FP)
n_total = len(gts)
Pr = acc_TP / (acc_TP + acc_FP)
Rc = acc_TP / n_total
return _compute_AP(Pr, Rc)
def _compute_AP(Pr, Rc):
Rc = np.concatenate(([0], Rc, [1]))
Pr = np.concatenate(([0], Pr, [0]))
# compute the real Pr
# Pr 曲线不是严格递减, 因此实际计算只取右边最大值
for i in range(len(Pr) - 1, 0, -1):
Pr[i-1] = max(Pr[i-1], Pr[i])
# compute the AP
index = np.where(Rc[1:] != Rc[:-1])[0]
AP = np.sum(Pr[index + 1] * (Rc[index+1] - Rc[index]))
return AP
mIoU, mDice, mFscore, aAcc 等计算
其中 m 都是指在类比上的mean, 因此只需要考虑如何计算单个类别即可. 下面是 mmsegmentation 中的实现, 比较简洁高效.
- 求出每张图的 intersection, union, area_pred, area_label, 后面直接在所有样本上累加得到 total_intersection, total_union, total_area_pred, total_label 再进行计算, 这样可以避免 某张图 intersection 或者 area_pred 等为0的情况.
- 也就是像素级别求解IoU, 然后类别上平均
def intersect_and_union(pred_label: torch.tensor, label: torch.tensor,
num_classes: int, ignore_index: int):
"""Calculate Intersection and Union.
Args:
pred_label (torch.tensor): Prediction segmentation map
or predict result filename. The shape is (H, W).
label (torch.tensor): Ground truth segmentation map
or label filename. The shape is (H, W).
num_classes (int): Number of categories.
ignore_index (int): Index that will be ignored in evaluation.
Returns:
torch.Tensor: The intersection of prediction and ground truth
histogram on all classes.
torch.Tensor: The union of prediction and ground truth histogram on
all classes.
torch.Tensor: The prediction histogram on all classes.
torch.Tensor: The ground truth histogram on all classes.
"""
mask = (label != ignore_index)
pred_label = pred_label[mask]
label = label[mask]
# intersect 的值为 [0 - num_classes-1]
# 值==i的个数是i类别上的intersection
intersect = pred_label[pred_label == label]
area_intersect = torch.histc(
intersect.float(), bins=(num_classes), min=0,
max=num_classes - 1).cpu()
area_pred_label = torch.histc(
pred_label.float(), bins=(num_classes), min=0,
max=num_classes - 1).cpu()
area_label = torch.histc(
label.float(), bins=(num_classes), min=0,
max=num_classes - 1).cpu()
area_union = area_pred_label + area_label - area_intersect
return area_intersect, area_union, area_pred_label, area_label















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









