






写在前面
作为一名算法工程师, 收集处理数据的能力也是比较重要的. 能够充分利用好互联网的数据资源, 加上优秀的算法能力, 就如虎添翼. 这次就以著名的 pixabay.com 为例子, 讲解一下如何写一个简单的爬虫程序.
第一步: 打开网页
通常打开网页, 我们看到的是网页的皮囊, 也就是网页外表的样子, 而写爬虫我们需要知道网页的骨骼和血脉才能精细地自动化地找到我们想要的内容. 如何看到网页实质的内容呢? 首先就需要打开开发人员工具.
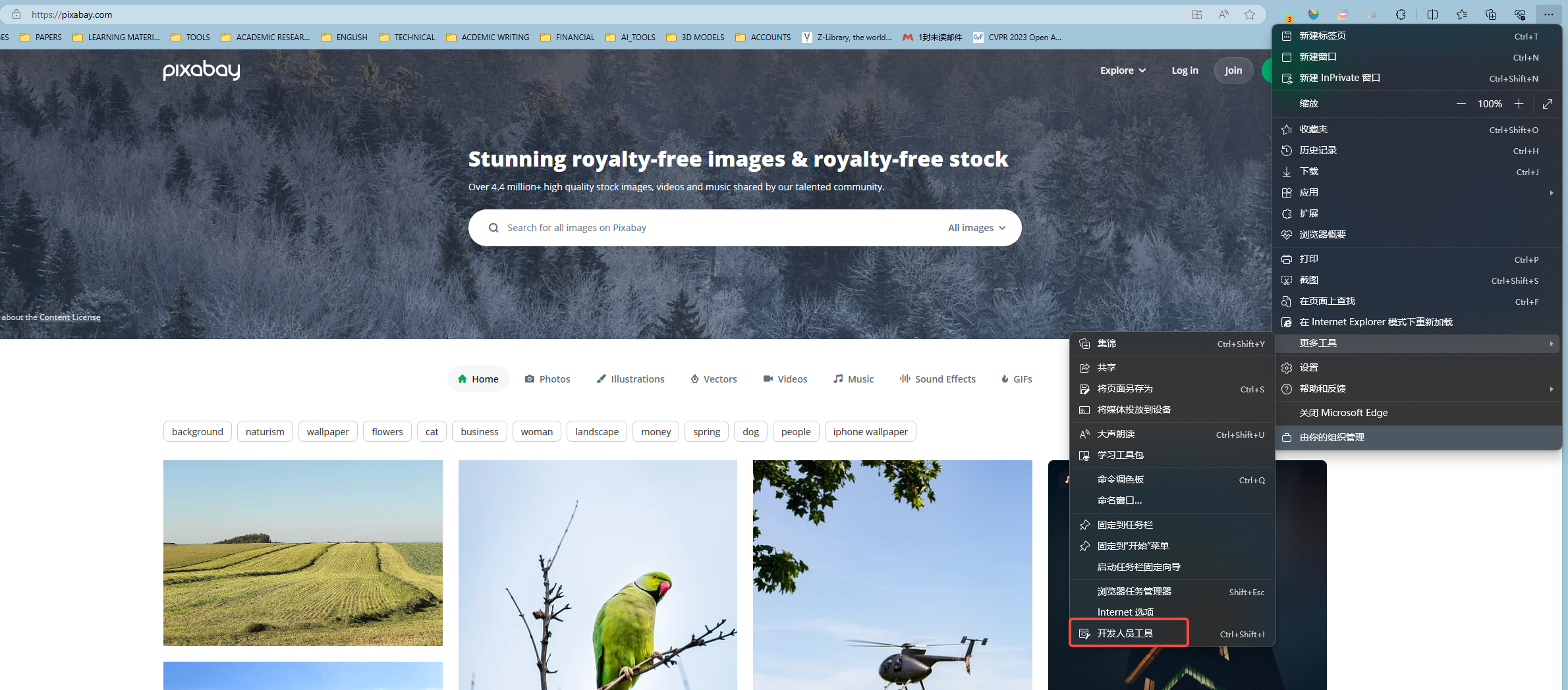
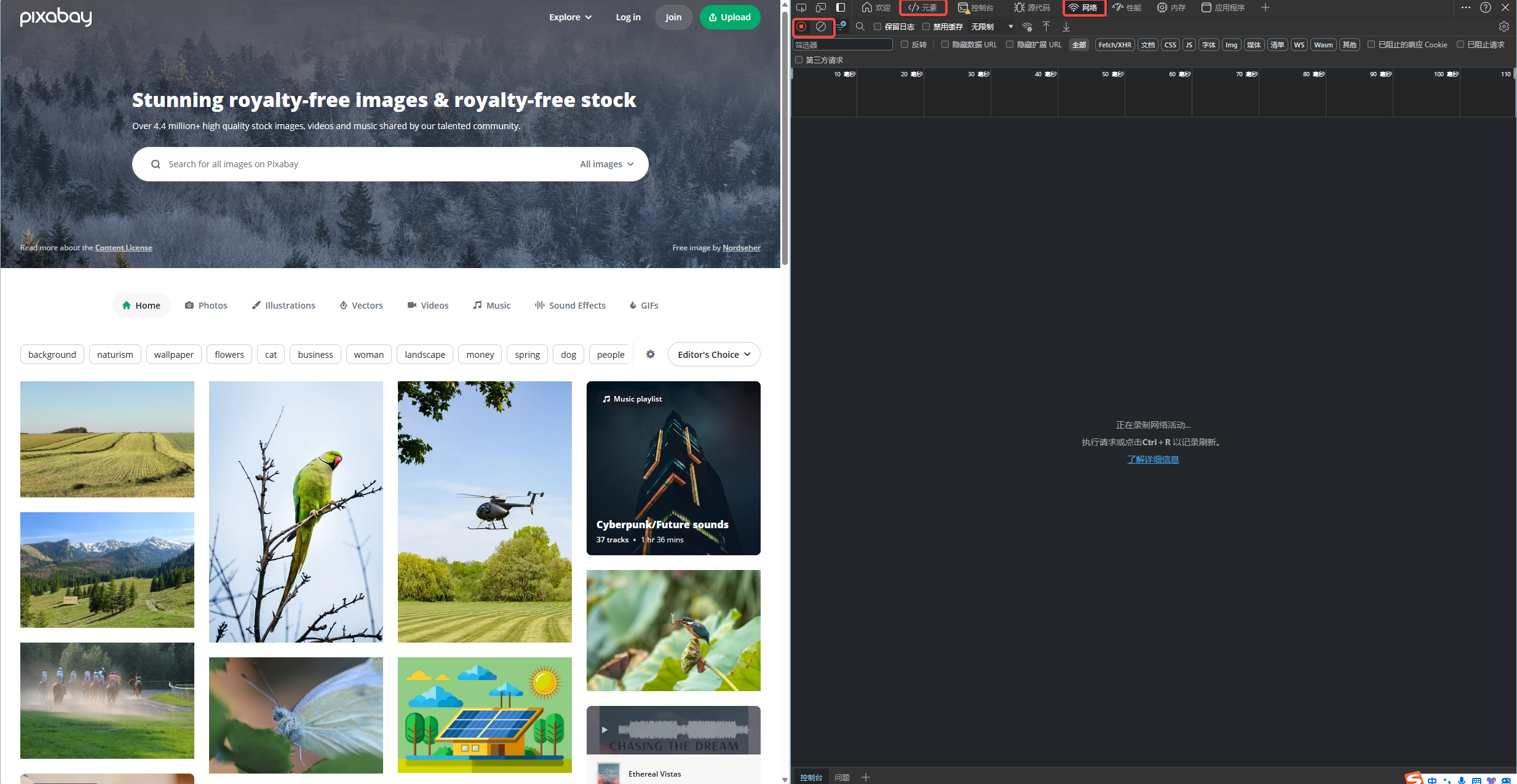
打开开发人员工具后, 有几个比较重要的工具, 在图中我用红框做了标注. 最顶端是工具栏, 其中爬虫分析肯定会用到的就是 元素和 网络.
元素: 能帮我们搞清楚这个网页的结构, 让我们知道如何获取想要的内容,
网络: 用来监控所有请求的数据包, 可以让我们学会模拟浏览器发送请求, 这样才能骗过服务器获得我们想要的内容. 第二行我用红框标注的两个按钮分别是开始录制数据包和清空所有录制的数据包.
第二步: 学会模拟浏览器发送请求
首先, 在网络工具中, 刷线网页并打开数据包的录制, 这样网页打开过程中浏览器发送的所有数据包和收到的所有数据包都可以看的清清楚楚. 如下图所示.
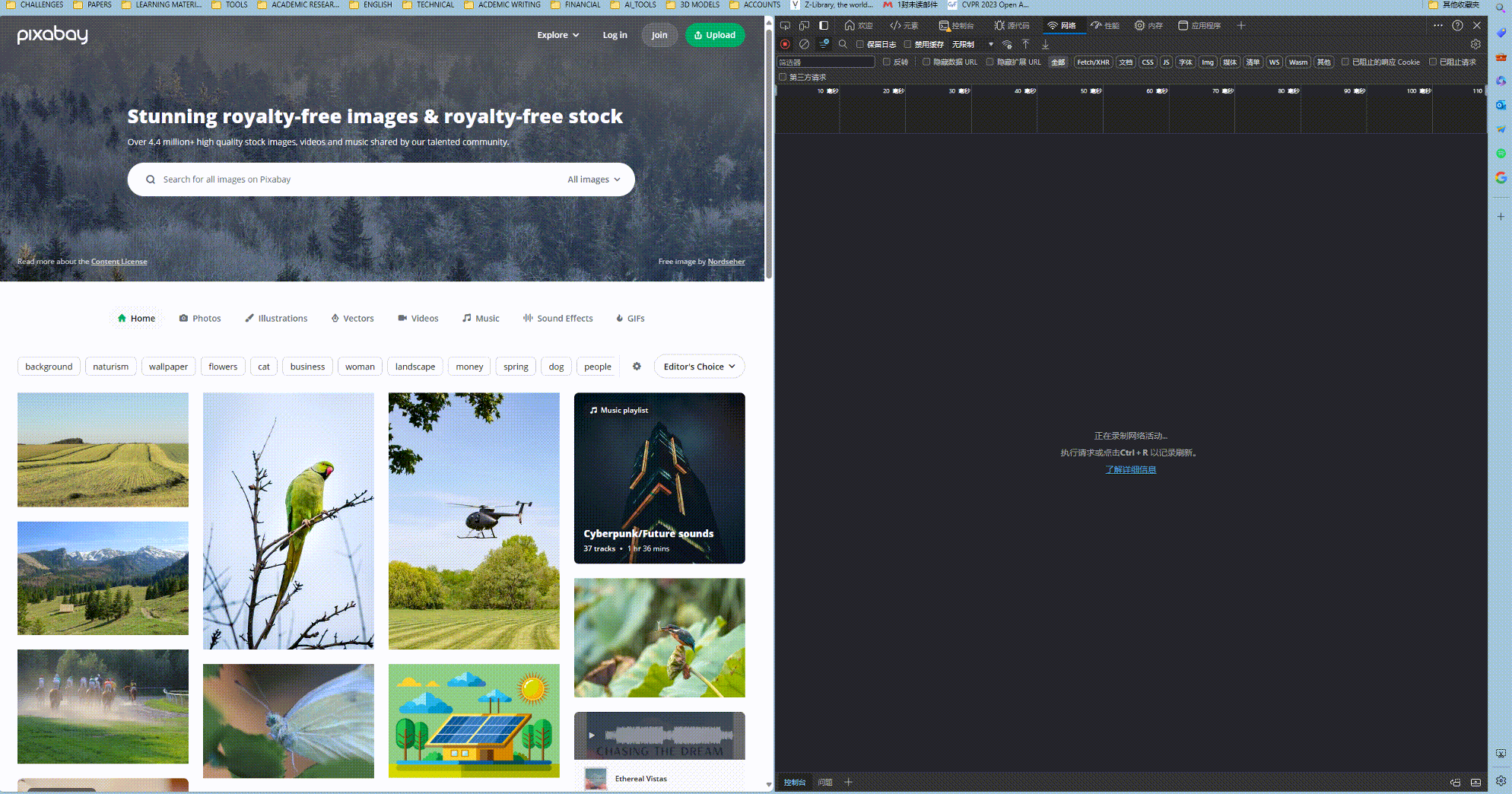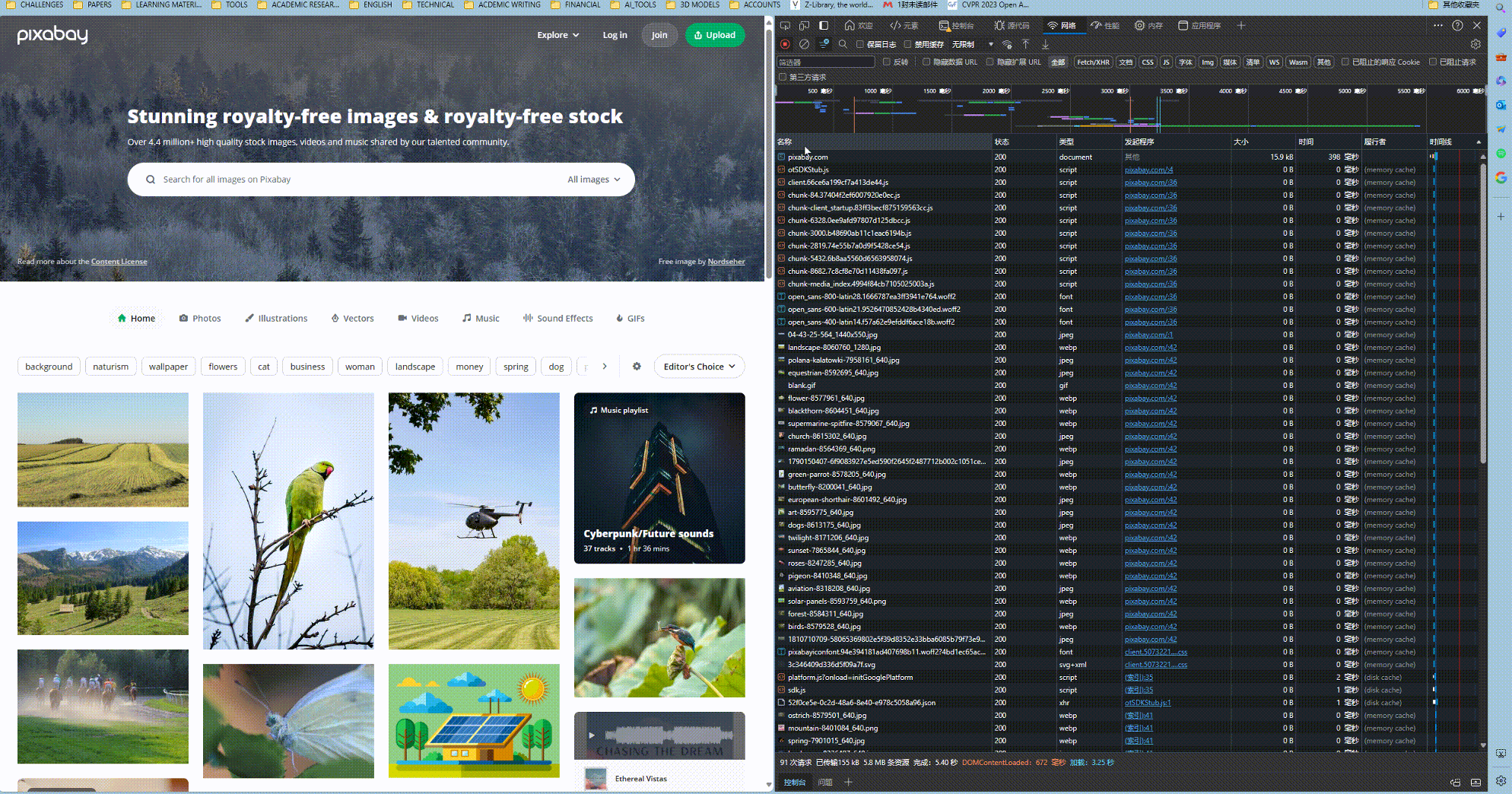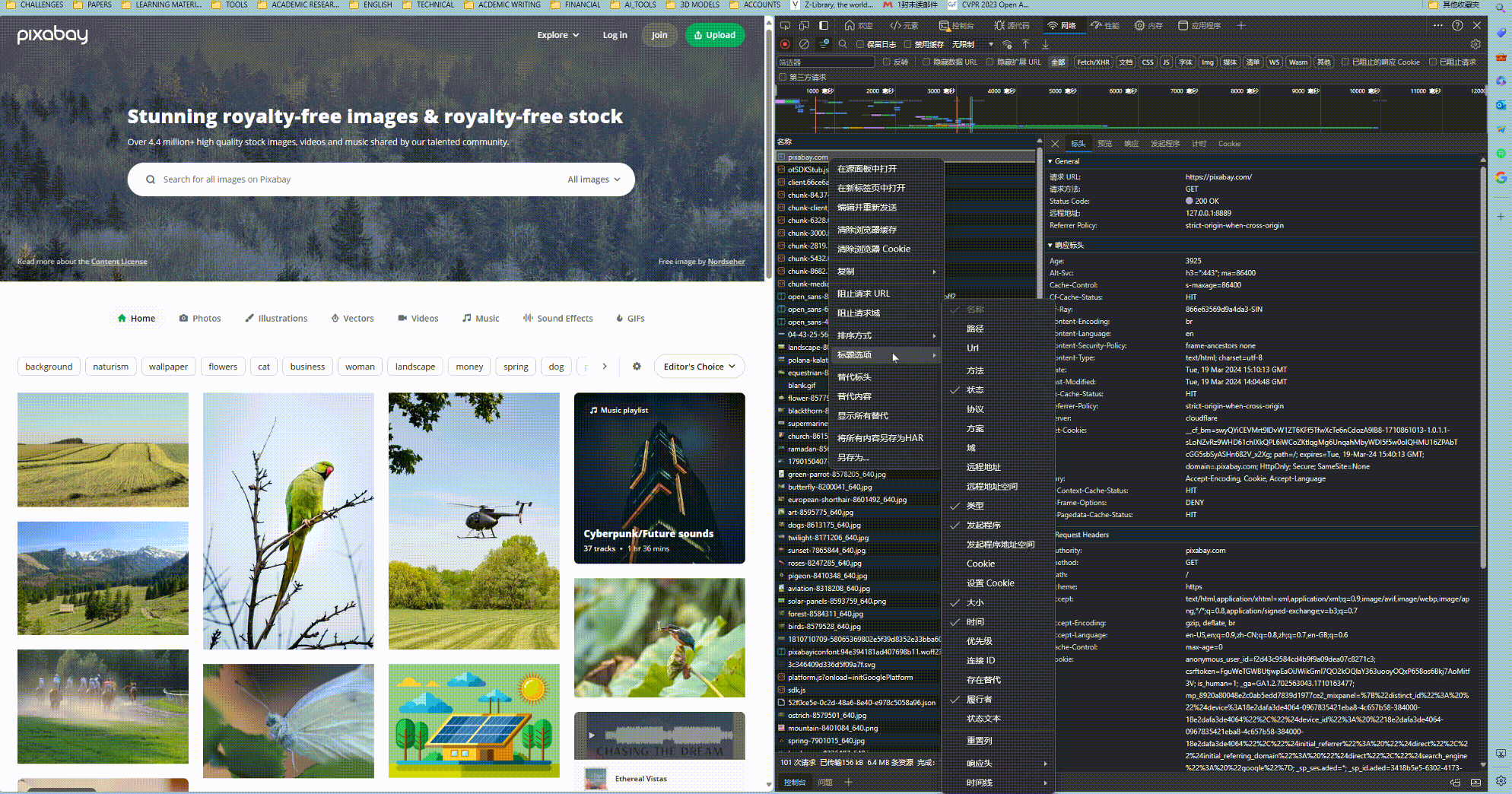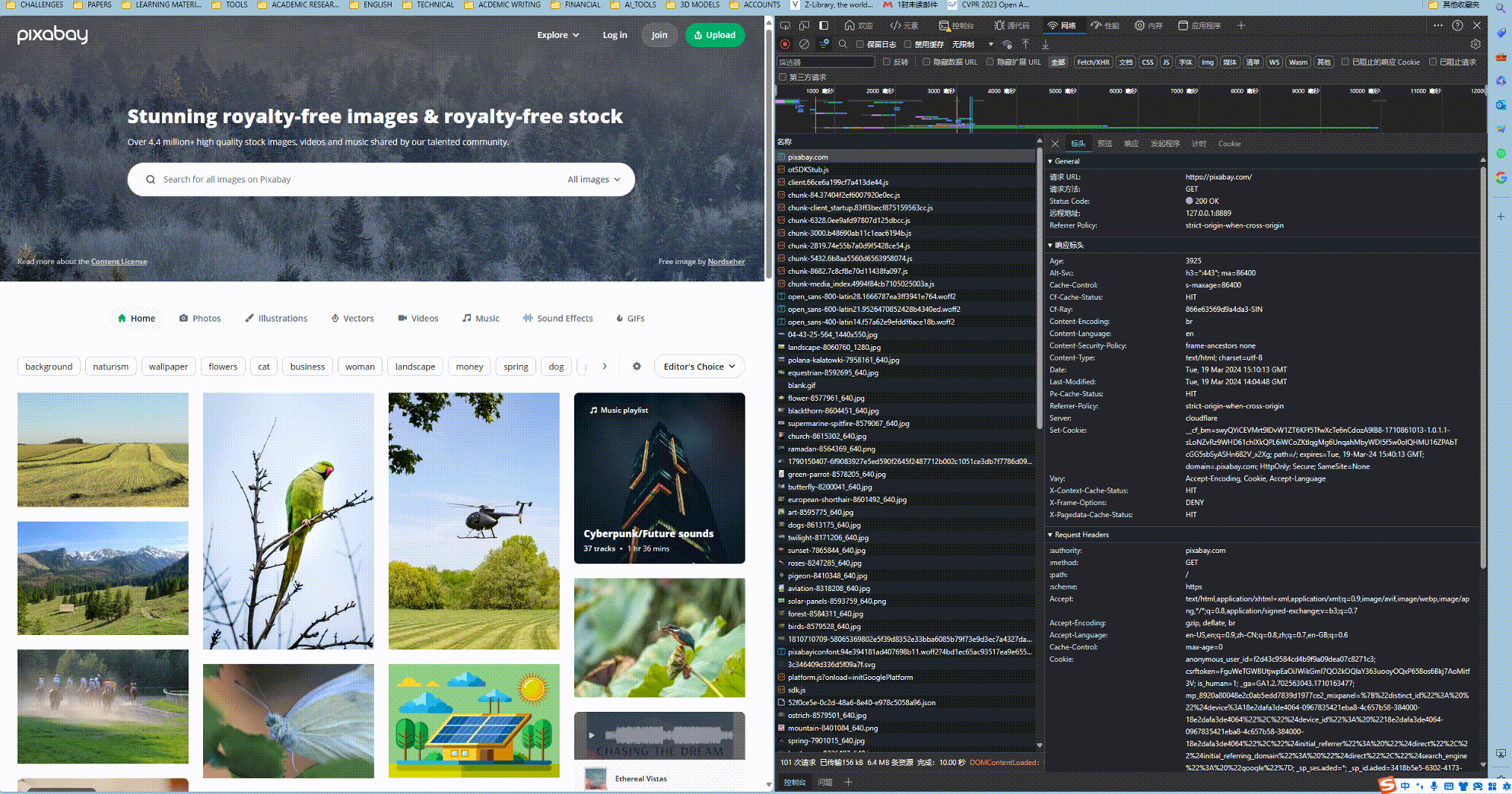
而我们需要做的就是找到网页发送的第一个数据包. 这个数据包往往就是得到初始的html网页所用的请求, 这个请求会包含大量的参数, 特别是cookies, 大部分情况下, 我们可以直接将参数拷贝到程序中. 拷贝的方式见上图.
拷贝的就是以下内容:
curl 'https://pixabay.com/' \
-H 'authority: pixabay.com' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'accept-language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,en-GB;q=0.6' \
-H 'cache-control: max-age=0' \
-H 'cookie: anonymous_user_id=f2d43c9584cd4b9f9a09dea07c8271c3; csrftoken=FguWeTGWBUtjwpEaOiJWikGml7QO2kOQlaY363uooyOQxP658os6Bkj7AoMitf3V; is_human=1; _ga=GA1.2.702563043.1710163477; mp_8920a80048e2c0ab5edd7839d1977ce2_mixpanel=%7B%22distinct_id%22%3A%20%22%24device%3A18e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24device_id%22%3A%20%2218e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24initial_referrer%22%3A%20%22%24direct%22%2C%22%24initial_referring_domain%22%3A%20%22%24direct%22%2C%22%24search_engine%22%3A%20%22google%22%7D; _sp_ses.aded=*; _sp_id.aded=3418b5e5-6302-4173-8f70-c88d85ee81f4.1710163477.2.1710860374.1710163751.3d74cc77-e4e2-4e25-89f9-d1503efdd397.f2a43a7e-3abc-47dd-9fad-63c46fa604e1.8dc4a434-cf2b-47f4-b79f-6e1f0a946d15.1710860373915.1; _gid=GA1.2.2127373981.1710860374; OptanonConsent=isGpcEnabled=0&datestamp=Tue+Mar+19+2024+22%3A59%3A46+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=202402.1.0&browserGpcFlag=0&isIABGlobal=false&hosts=&consentId=ed893af7-ea08-48f0-93de-efda82ccad17&interactionCount=1&isAnonUser=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false; __cf_bm=vziOqFTvklFQPDQa7HH3NqQ976mWyhov_nllOzqjLX0-1710860581-1.0.1.1-KClvGibZ9a1DJrTfwZ6J67bF667cp1No5GiquiUBwDgazLIlSiXuflZJvMM8CoCoww7XG1wesemo2SU1gjf9Ew' \
-H 'sec-ch-ua: "Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: none' \
-H 'sec-fetch-user: ?1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
上面的内容还不能直接被python程序利用, 我们可以用在线的工具curlconvert转成python requests所用的参数, 如下所示
import requests
cookies = {
'anonymous_user_id': 'f2d43c9584cd4b9f9a09dea07c8271c3',
'csrftoken': 'FguWeTGWBUtjwpEaOiJWikGml7QO2kOQlaY363uooyOQxP658os6Bkj7AoMitf3V',
'is_human': '1',
'_ga': 'GA1.2.702563043.1710163477',
'mp_8920a80048e2c0ab5edd7839d1977ce2_mixpanel': '%7B%22distinct_id%22%3A%20%22%24device%3A18e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24device_id%22%3A%20%2218e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24initial_referrer%22%3A%20%22%24direct%22%2C%22%24initial_referring_domain%22%3A%20%22%24direct%22%2C%22%24search_engine%22%3A%20%22google%22%7D',
'_sp_ses.aded': '*',
'_sp_id.aded': '3418b5e5-6302-4173-8f70-c88d85ee81f4.1710163477.2.1710860374.1710163751.3d74cc77-e4e2-4e25-89f9-d1503efdd397.f2a43a7e-3abc-47dd-9fad-63c46fa604e1.8dc4a434-cf2b-47f4-b79f-6e1f0a946d15.1710860373915.1',
'_gid': 'GA1.2.2127373981.1710860374',
'OptanonConsent': 'isGpcEnabled=0&datestamp=Tue+Mar+19+2024+22%3A59%3A46+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=202402.1.0&browserGpcFlag=0&isIABGlobal=false&hosts=&consentId=ed893af7-ea08-48f0-93de-efda82ccad17&interactionCount=1&isAnonUser=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false',
'__cf_bm': 'vziOqFTvklFQPDQa7HH3NqQ976mWyhov_nllOzqjLX0-1710860581-1.0.1.1-KClvGibZ9a1DJrTfwZ6J67bF667cp1No5GiquiUBwDgazLIlSiXuflZJvMM8CoCoww7XG1wesemo2SU1gjf9Ew',
}
headers = {
'authority': 'pixabay.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,en-GB;q=0.6',
'cache-control': 'max-age=0',
# 'cookie': 'anonymous_user_id=f2d43c9584cd4b9f9a09dea07c8271c3; csrftoken=FguWeTGWBUtjwpEaOiJWikGml7QO2kOQlaY363uooyOQxP658os6Bkj7AoMitf3V; is_human=1; _ga=GA1.2.702563043.1710163477; mp_8920a80048e2c0ab5edd7839d1977ce2_mixpanel=%7B%22distinct_id%22%3A%20%22%24device%3A18e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24device_id%22%3A%20%2218e2dafa3de4064-0967835421eba8-4c657b58-384000-18e2dafa3de4064%22%2C%22%24initial_referrer%22%3A%20%22%24direct%22%2C%22%24initial_referring_domain%22%3A%20%22%24direct%22%2C%22%24search_engine%22%3A%20%22google%22%7D; _sp_ses.aded=*; _sp_id.aded=3418b5e5-6302-4173-8f70-c88d85ee81f4.1710163477.2.1710860374.1710163751.3d74cc77-e4e2-4e25-89f9-d1503efdd397.f2a43a7e-3abc-47dd-9fad-63c46fa604e1.8dc4a434-cf2b-47f4-b79f-6e1f0a946d15.1710860373915.1; _gid=GA1.2.2127373981.1710860374; OptanonConsent=isGpcEnabled=0&datestamp=Tue+Mar+19+2024+22%3A59%3A46+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=202402.1.0&browserGpcFlag=0&isIABGlobal=false&hosts=&consentId=ed893af7-ea08-48f0-93de-efda82ccad17&interactionCount=1&isAnonUser=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false; __cf_bm=vziOqFTvklFQPDQa7HH3NqQ976mWyhov_nllOzqjLX0-1710860581-1.0.1.1-KClvGibZ9a1DJrTfwZ6J67bF667cp1No5GiquiUBwDgazLIlSiXuflZJvMM8CoCoww7XG1wesemo2SU1gjf9Ew',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
response = requests.get('https://pixabay.com/', cookies=cookies, headers=headers)
Note: 但是这里有一个坑, 就是requests只支持http1, 而我们网页所用的协议是http2, 因此直接用回请求失败. 这一点特别需要注意 好在我们有解决方案就是使用http3这个python包.
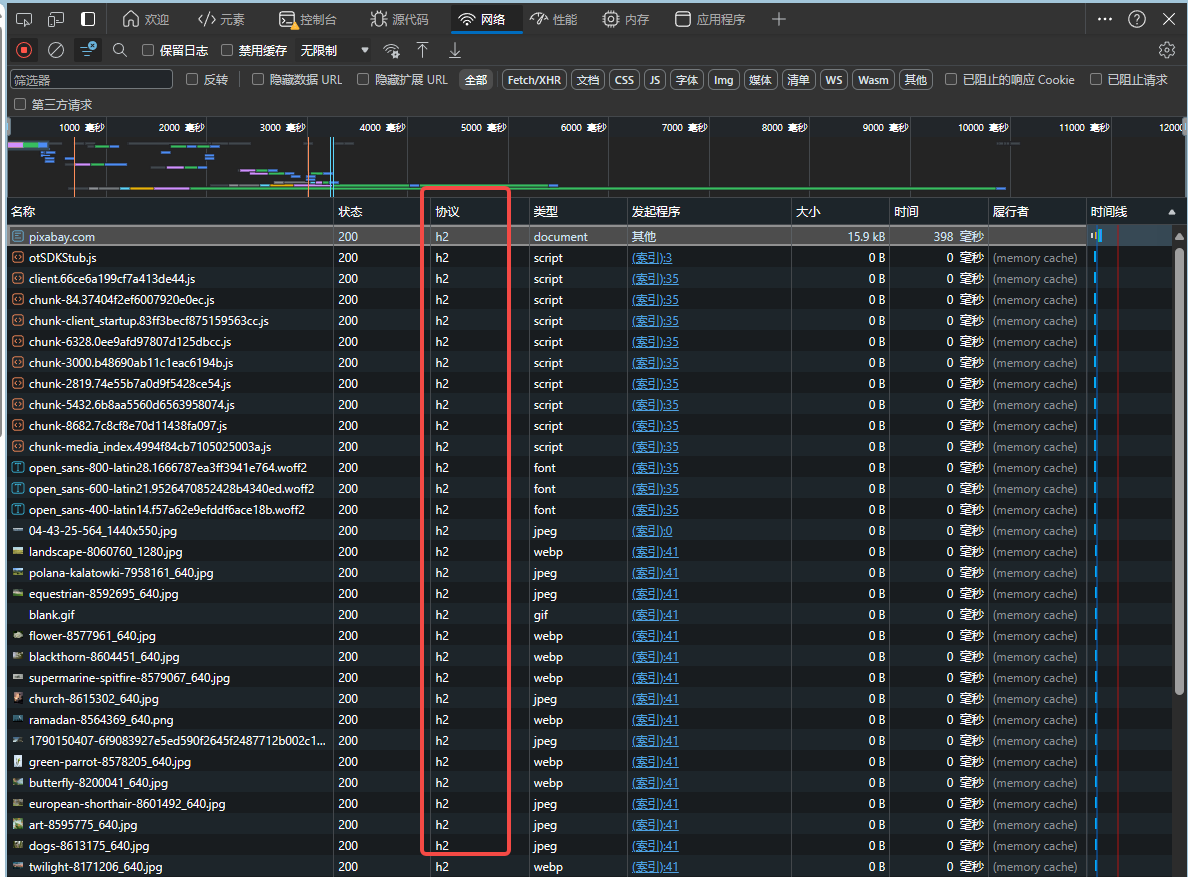
第三步: 分析网页结果, 找到爬取内容
这个步骤, 我们需要用到元素这个工具. 使用方法如下所示, 这样我们就定位到了我们想爬取的图片所在网页的位置.
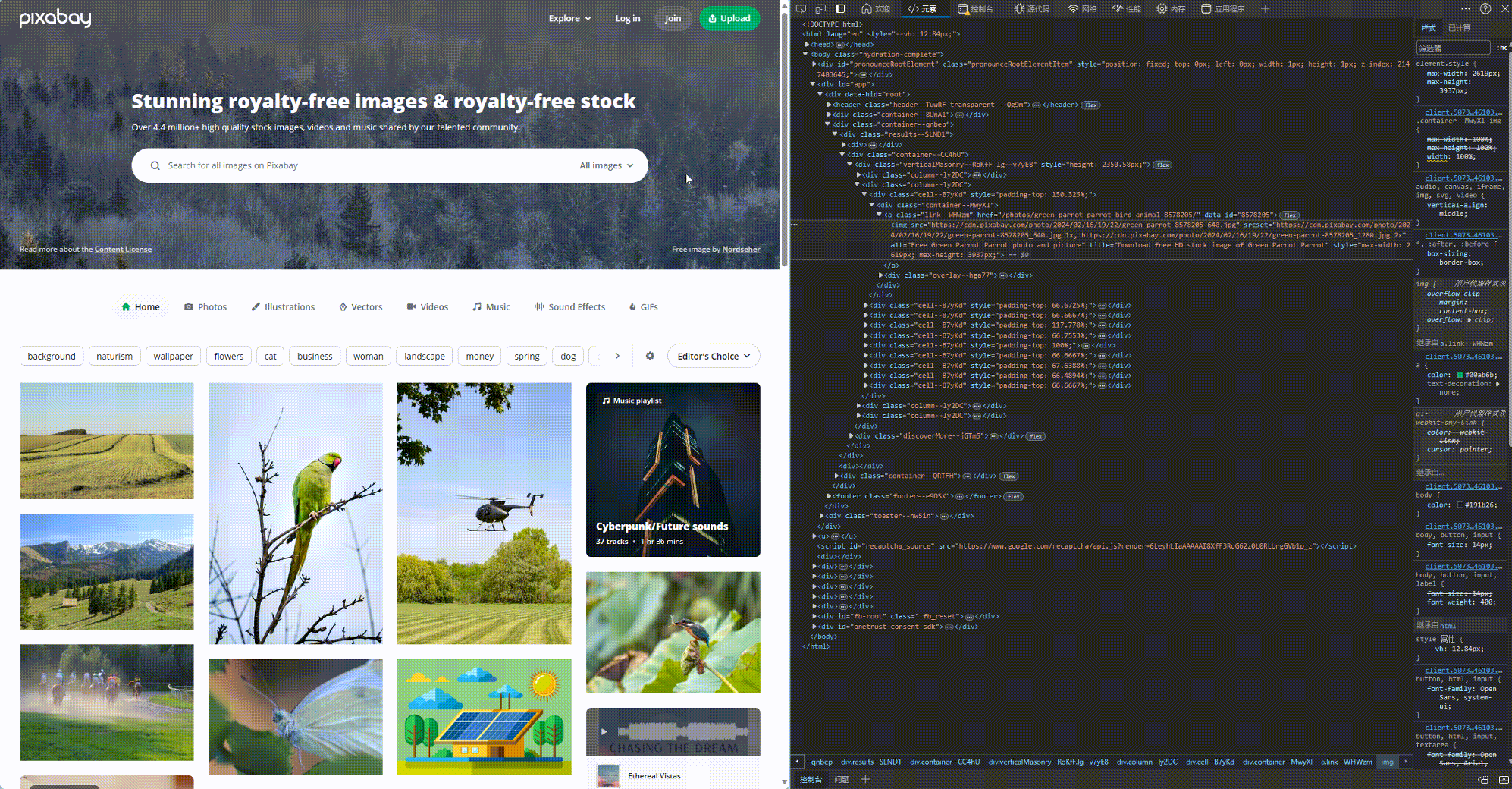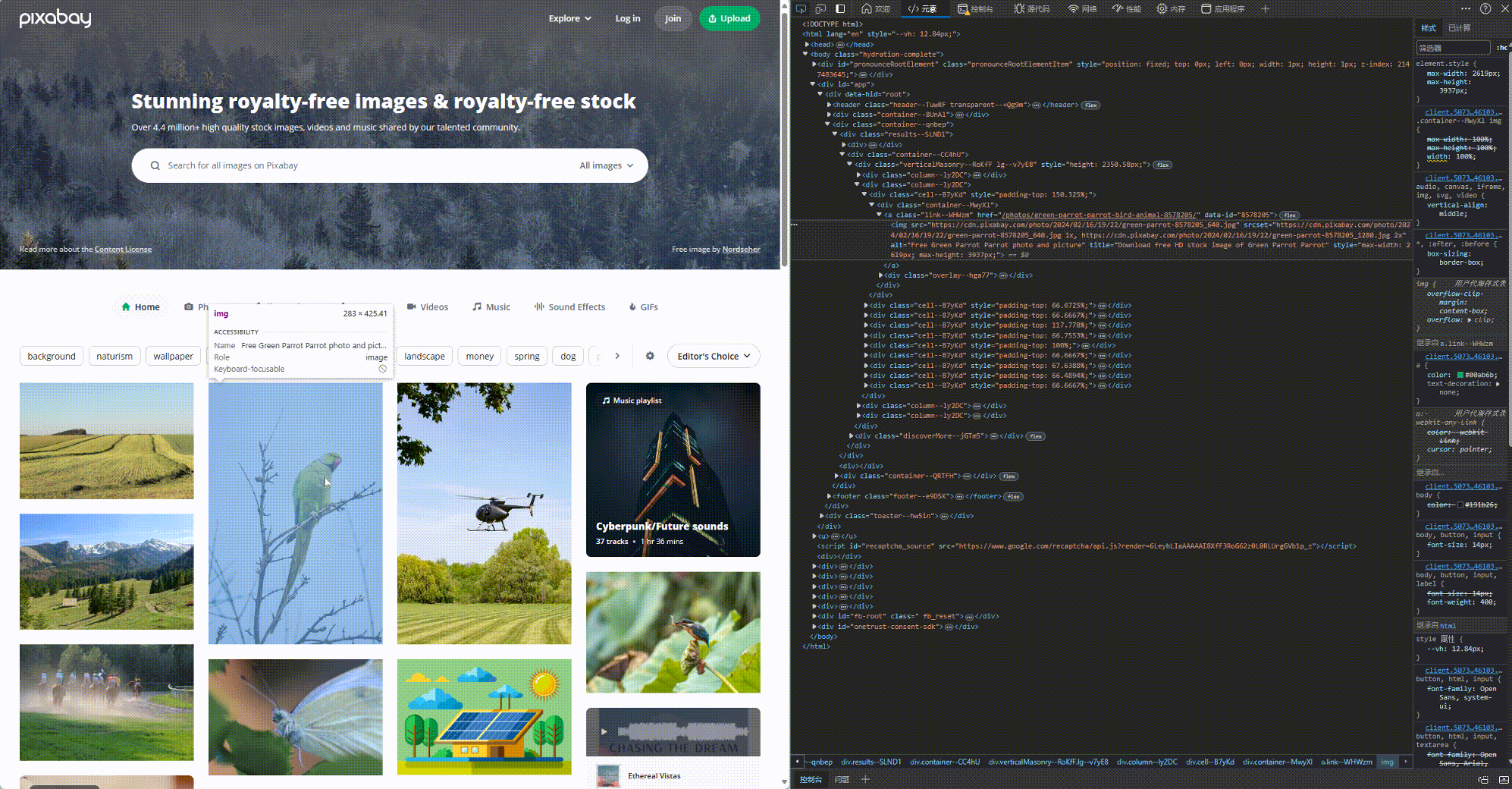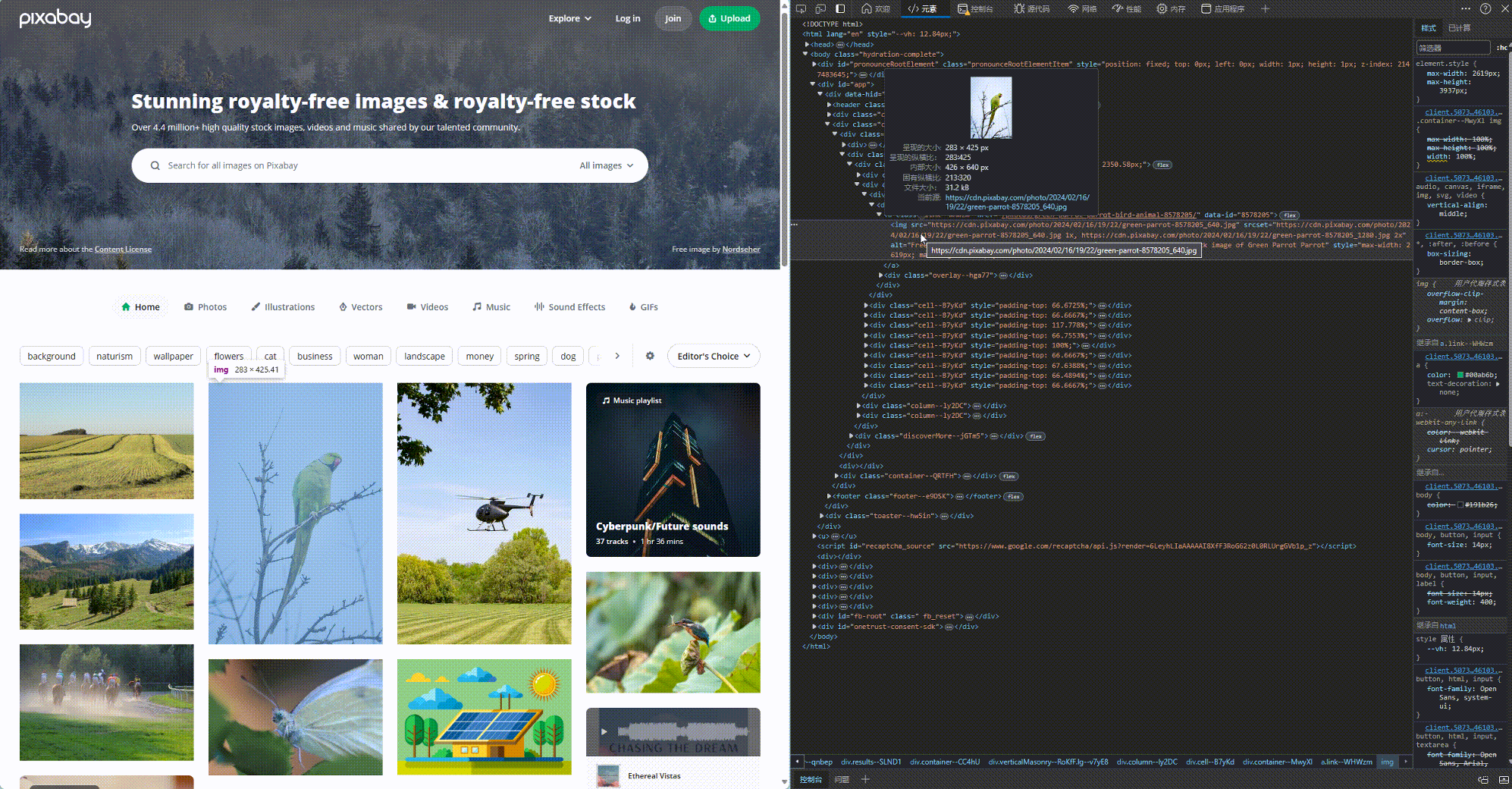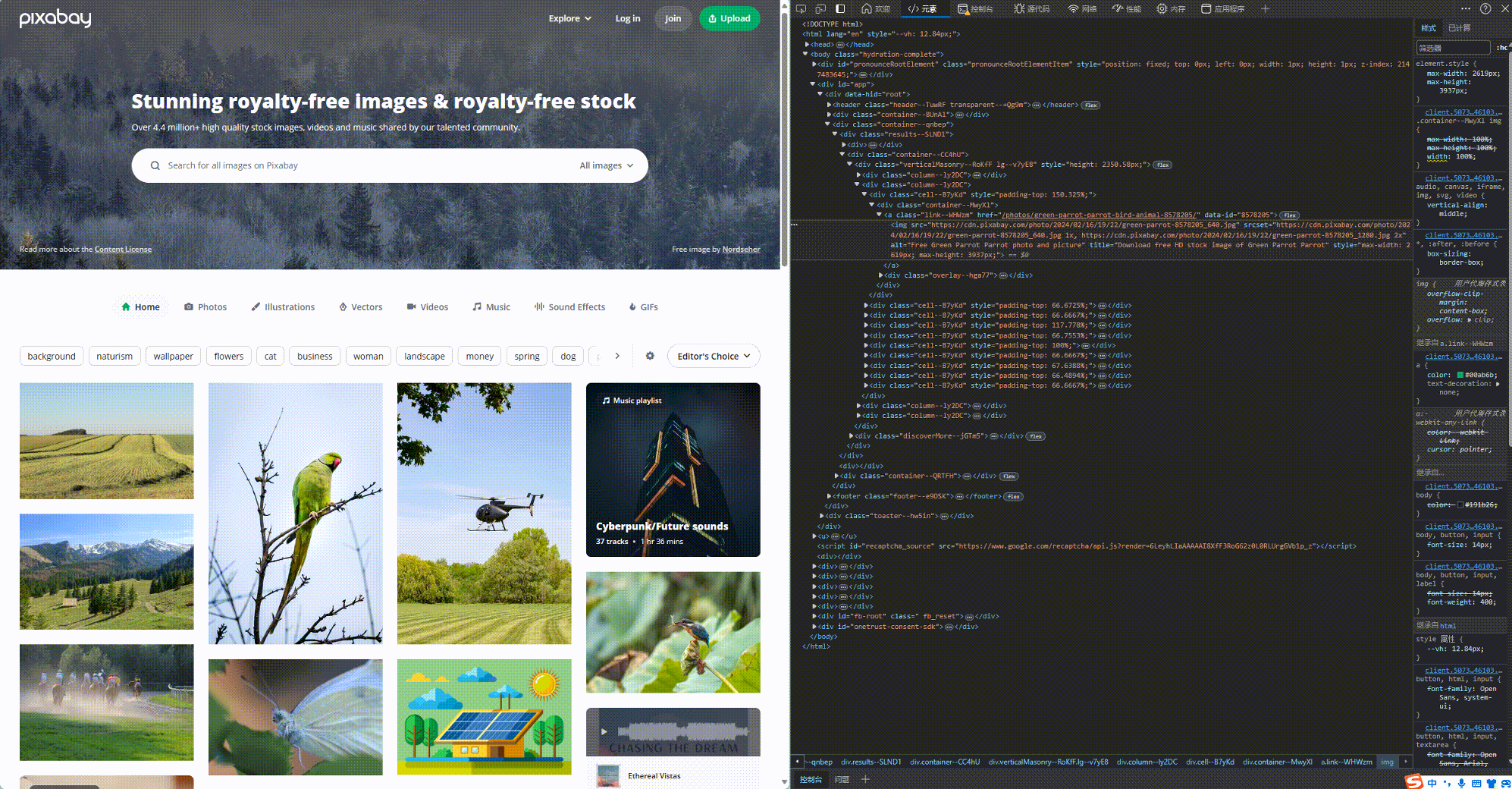
找到图片的位置后, 我们还要分析一下规律, 如何才能找到所有的图片. 浓缩下来就是以下code
response = http3.get(url, params=params, headers=headers, cookies=cookies)
text = response.read()
# parse pipeline
soup = BeautifulSoup(text, 'html.parser')
results_div = soup.find('div', class_=re.compile(r'results'))
cols = results_div.find_all('div', class_=re.compile("column"))
img_urls = list()
for col in cols:
cells = col.find_all('div', class_=re.compile('cell'))
img_urls.extend(
[cell.img["src"] for cell in cells]
)
第四步: 处理动态网页
如果是静态网页, 我们通过以上三步就能直接爬取. 但是对于动态网页, 其内容是更具交互加载的. 以 pixabay.com 为例, 当你下滑网页的时候, 其图片才会慢慢加载. 如下所示, 当网页滑动的过程中, 会不断请求新的图片.而我们的爬虫code目前还没法模拟下滑鼠标的操作.
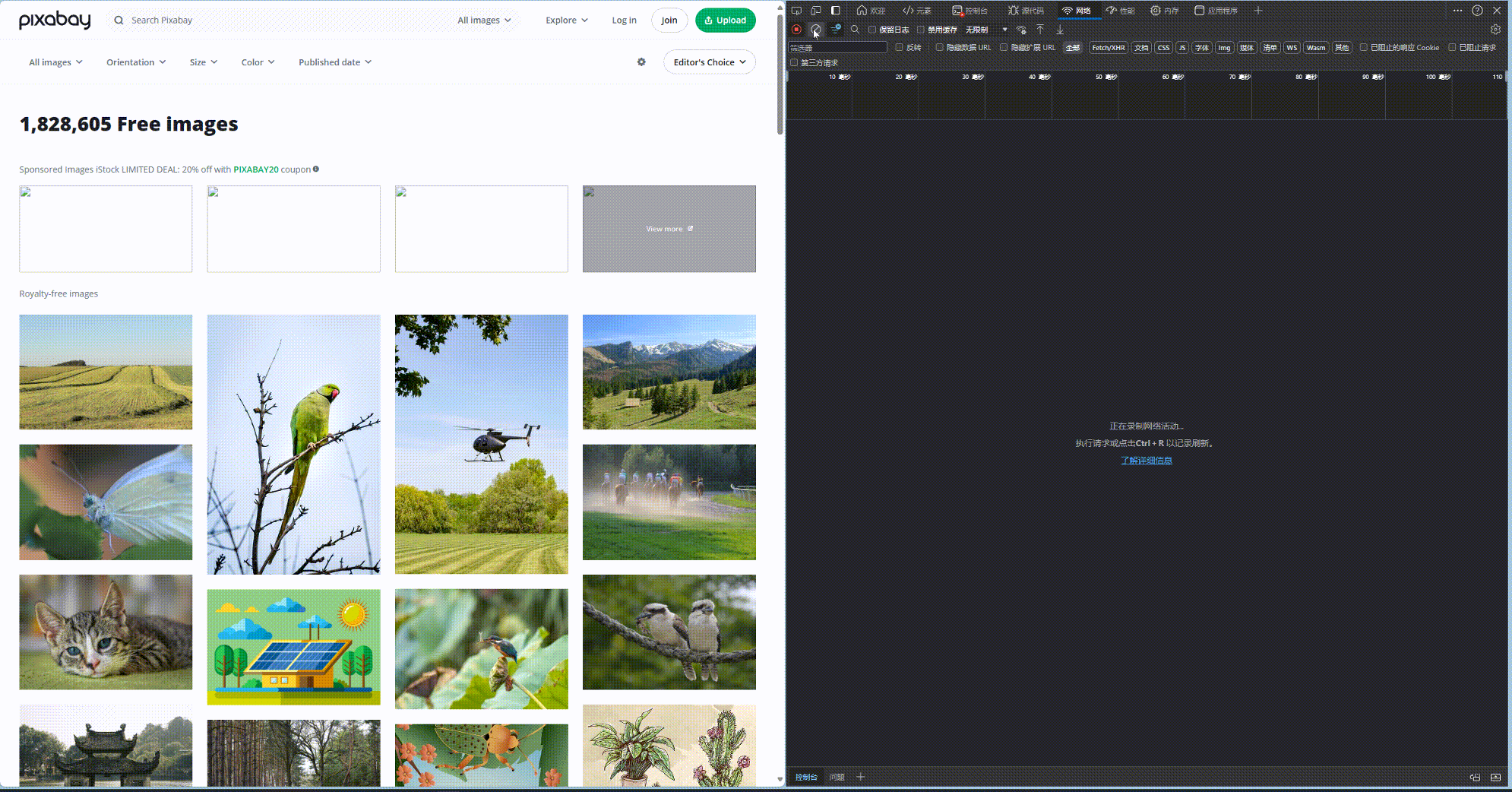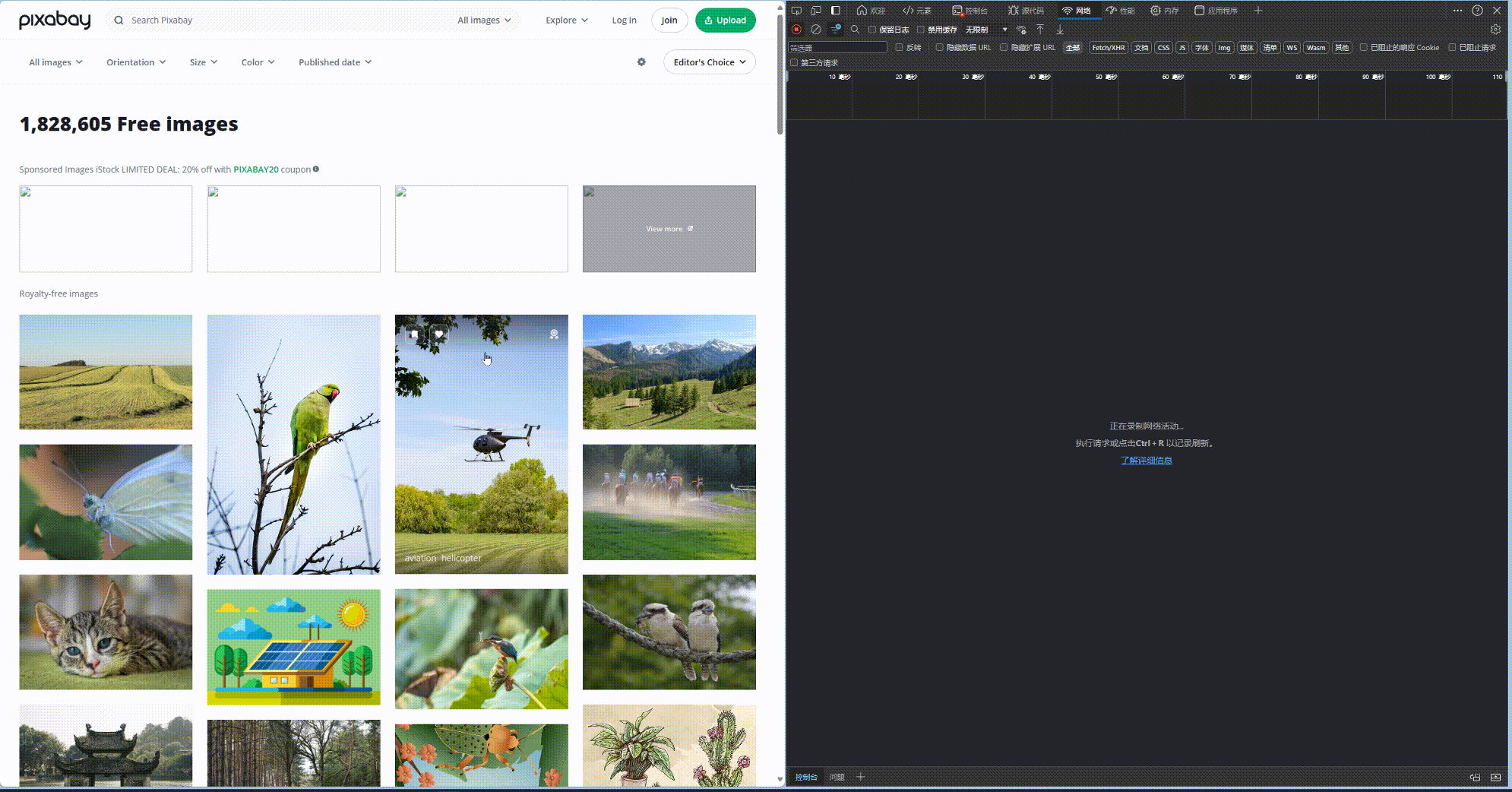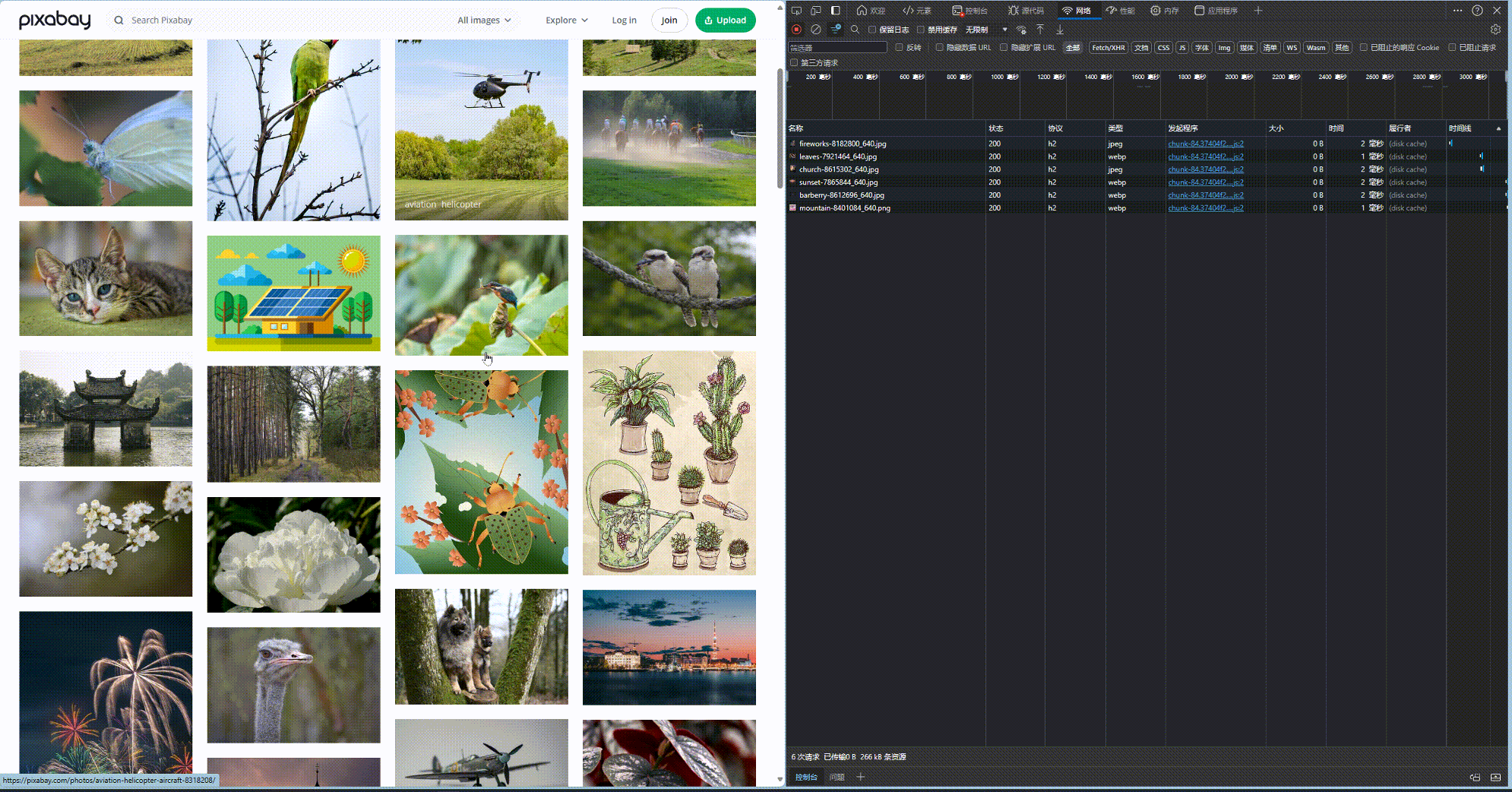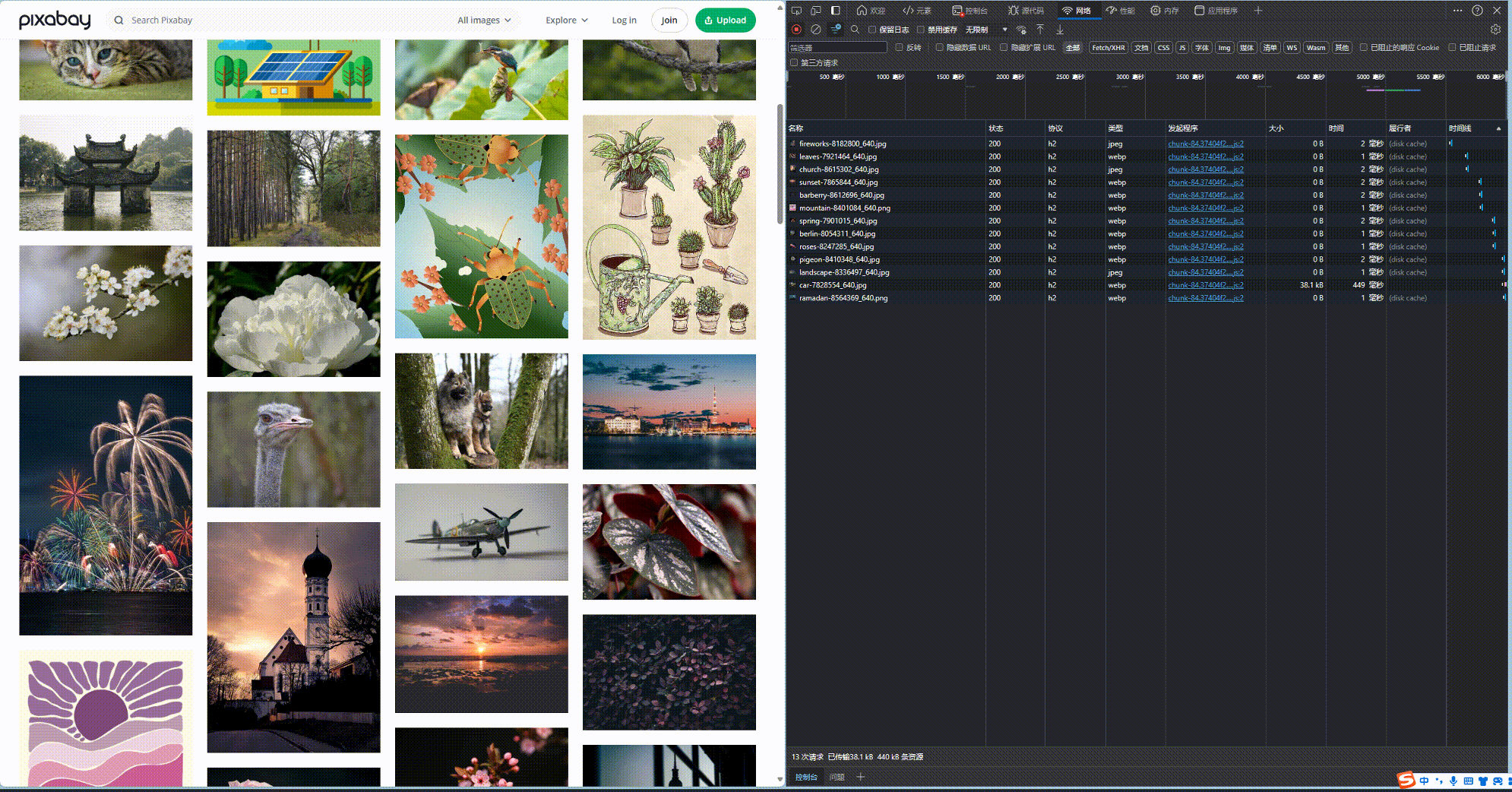
好在, 这些请求都是javascript脚本发送的, 因此这些图像的路径一定藏在javascript的脚本中. 果然, 我们对html网页进行查看, 和图片相邻的script中, 就藏着图片的链接. 至此, 就算网页是动态的, 我们也有办法爬下来.
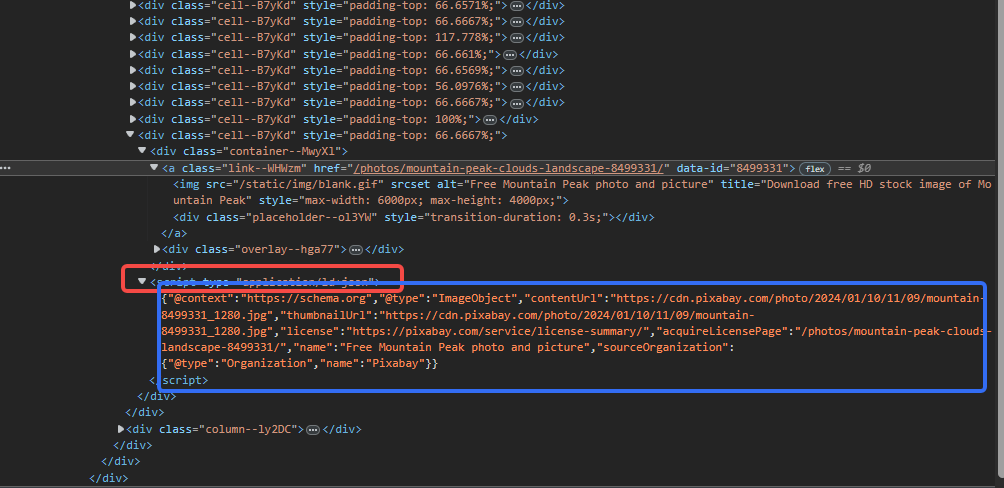
所有程序
import time
import pathlib
import os
import pprint
import random
import hashlib
import re
import http3
import numpy as np
from bs4 import BeautifulSoup
img_headers = {
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'Referer': 'https://pixabay.com/',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'sec-ch-ua-platform': '"Windows"',
}
cookies = {
'is_human': '1',
'anonymous_user_id': 'cc9e765d8afe412f8d96d9825d5a6234',
'csrftoken': 'AesdWC6DffszQUXZ3mFDKF2HFu2hij64YQP6Pqbw9EToyxWbMzvRZvo55Mz6ZWSY',
'_ga': 'GA1.2.1294876439.1710140941',
'_gid': 'GA1.2.1213392201.1710140941',
'dwf_community_ai_generated_report': 'True',
'dwf_es_my_boost_modifier': 'True',
'OptanonAlertBoxClosed': '2024-03-11T07:09:53.539Z',
'dwf_show_mdp_getty_brand_ad': 'False',
'_sp_ses.aded': '*',
'__cf_bm': 'bl6fOBk4XuiW4JrkzOrgbrx5tl7c1Pd_PDUlhcIv2rs-1710211269-1.0.1.1-nBLo3zEltXYb1CpAf8C8sMmKylVjn9q.fVMrcsGOppOGsLkGyvOAIcJYChcl4TxeBuMFP0A5lxQ.91B9moTiYw',
'OptanonConsent': 'isGpcEnabled=0&datestamp=Tue+Mar+12+2024+10%3A47%3A29+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=202402.1.0&browserGpcFlag=0&isIABGlobal=false&hosts=&consentId=a3b7741a-bcfe-493a-9fe9-1a6938a076c5&interactionCount=2&isAnonUser=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false&geolocation=HK%3B',
'mp_8920a80048e2c0ab5edd7839d1977ce2_mixpanel': '%7B%22distinct_id%22%3A%20%22%24device%3A18e2c57cf33324-01f7c74bbcc6e2-4c657b58-240480-18e2c57cf33324%22%2C%22%24device_id%22%3A%20%2218e2c57cf33324-01f7c74bbcc6e2-4c657b58-240480-18e2c57cf33324%22%2C%22%24initial_referrer%22%3A%20%22https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fpixabay.com%2F%22%2C%22%24initial_referring_domain%22%3A%20%22link.zhihu.com%22%2C%22%24search_engine%22%3A%20%22bing%22%7D',
'_sp_id.aded': 'f02a5d38-f58f-450b-b09c-efd53201ce94.1710140939.5.1710211650.1710205647.0c13fc3f-bfa1-4229-a60b-f505542ef9a6.cecbc184-82de-4805-bab5-89f8bfa7c784.b8d91c2f-d699-471d-900b-7d0cc52004ee.1710207742710.15',
}
headers = {
'authority': 'pixabay.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
# 'cookie': 'is_human=1; anonymous_user_id=cc9e765d8afe412f8d96d9825d5a6234; csrftoken=AesdWC6DffszQUXZ3mFDKF2HFu2hij64YQP6Pqbw9EToyxWbMzvRZvo55Mz6ZWSY; _ga=GA1.2.1294876439.1710140941; _gid=GA1.2.1213392201.1710140941; dwf_community_ai_generated_report=True; dwf_es_my_boost_modifier=True; OptanonAlertBoxClosed=2024-03-11T07:09:53.539Z; dwf_show_mdp_getty_brand_ad=False; _sp_ses.aded=*; __cf_bm=bl6fOBk4XuiW4JrkzOrgbrx5tl7c1Pd_PDUlhcIv2rs-1710211269-1.0.1.1-nBLo3zEltXYb1CpAf8C8sMmKylVjn9q.fVMrcsGOppOGsLkGyvOAIcJYChcl4TxeBuMFP0A5lxQ.91B9moTiYw; OptanonConsent=isGpcEnabled=0&datestamp=Tue+Mar+12+2024+10%3A47%3A29+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=202402.1.0&browserGpcFlag=0&isIABGlobal=false&hosts=&consentId=a3b7741a-bcfe-493a-9fe9-1a6938a076c5&interactionCount=2&isAnonUser=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false&geolocation=HK%3B; mp_8920a80048e2c0ab5edd7839d1977ce2_mixpanel=%7B%22distinct_id%22%3A%20%22%24device%3A18e2c57cf33324-01f7c74bbcc6e2-4c657b58-240480-18e2c57cf33324%22%2C%22%24device_id%22%3A%20%2218e2c57cf33324-01f7c74bbcc6e2-4c657b58-240480-18e2c57cf33324%22%2C%22%24initial_referrer%22%3A%20%22https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fpixabay.com%2F%22%2C%22%24initial_referring_domain%22%3A%20%22link.zhihu.com%22%2C%22%24search_engine%22%3A%20%22bing%22%7D; _sp_id.aded=f02a5d38-f58f-450b-b09c-efd53201ce94.1710140939.5.1710211650.1710205647.0c13fc3f-bfa1-4229-a60b-f505542ef9a6.cecbc184-82de-4805-bab5-89f8bfa7c784.b8d91c2f-d699-471d-900b-7d0cc52004ee.1710207742710.15',
'referer': 'https://pixabay.com/',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
params = {
'order': 'ec',
'pagi': '5',
}
class Spider():
def __init__(self, root, save_dir, hash_file="hash.txt"):
self.root = root
self.save_dir = os.path.join(root, save_dir)
pathlib.Path(self.save_dir).mkdir(exist_ok=True, parents=True)
self.hash_file = os.path.join(root, hash_file)
self.hash_data = list()
if os.path.exists(self.hash_file):
self.hash_data = np.loadtxt(self.hash_file, dtype=str).tolist()
self.hash_data = self.hash_data
def get_image(self, url):
while True:
try:
response = http3.get(url, headers=img_headers)
break
except (http3.exceptions.ReadTimeout, http3.exceptions.ConnectTimeout):
print("ReadTimeout")
time.sleep(random.random() * 100)
if response.status_code == 200:
file_name = url.split('/')[-1]
data = response.content
# md5_hash = hashlib.md5(data).hexdigest()[:10]
file_path = os.path.join(self.save_dir, file_name)
with open(file_path, 'wb') as file:
file.write(data)
else:
print(f"Image Download Failed! -- {url}")
# exit(0)
return
def get_response(self, page=1):
url = "https://pixabay.com/images/search/"
params['pagi'] = str(page)
response = http3.get(url, params=params, headers=headers, cookies=cookies)
print(response)
text = response.read()
# parse pipeline
soup = BeautifulSoup(text, 'html.parser')
results_div = soup.find('div', class_=re.compile(r'results'))
cols = results_div.find_all('div', class_=re.compile("column"))
img_urls = list()
img_pattern = re.compile('(?<="contentUrl":")(.*?)(?=")')
for col in cols:
cells = col.find_all('div', class_=re.compile('cell'))
img_urls.extend(
[re.search(img_pattern, cell.script.text).group(0) for cell in cells]
)
return img_urls
def url_transform(self, url):
url = url.replace('_1280.png', '_640.png')
url = url.replace('_1280.jpg', '_640.jpg')
return url
def collect_urls(self):
for i in range(1, 18255):
if os.path.exists(os.path.join(self.root, str(i))):
print(f"downloading ... page{i}")
imgs = self.get_response(i)
with open(self.hash_file, 'a') as file:
append_lst = set(imgs) - self.hash_data
np.savetxt(file, list(append_lst), fmt='%s')
self.hash_data = set(self.hash_data).union(imgs)
time.sleep(random.random())
os.remove(os.path.join(self.root, str(i)))
open(os.path.join(self.root, str(i+1)), 'w').close()
return
def download_images(self):
cnt = 0
for img_url in self.hash_data:
img_url = self.url_transform(img_url)
file_name = img_url.split('/')[-1]
# import IPython
# IPython.embed()
if os.path.exists(os.path.join(self.save_dir, file_name)):
cnt += 1
continue
self.get_image(img_url)
cnt += 1
time.sleep(random.random()) if cnt % 10 == 0 else None
time.sleep(random.random() * 10) if cnt % 500 == 0 else None
print(f"get {cnt:0>8d} images ...") if cnt % 100 == 0 else None
return
if __name__ == "__main__":
spider = Spider('pixabay_project', './pixaby_images', 'pixabay_hash.txt')
spider.collect_urls()
spider.download_images()

















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









