







EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。EDA的主要目标不是制作花哨的图形或创建彩色的图形,而是获得对数据集的理解,并获得对变量之间的分布和相关性的初步见解。我们在以前也介绍过EDA自动化的库,但是现在已经过了1年的时间了,我们看看现在有什么新的变化。
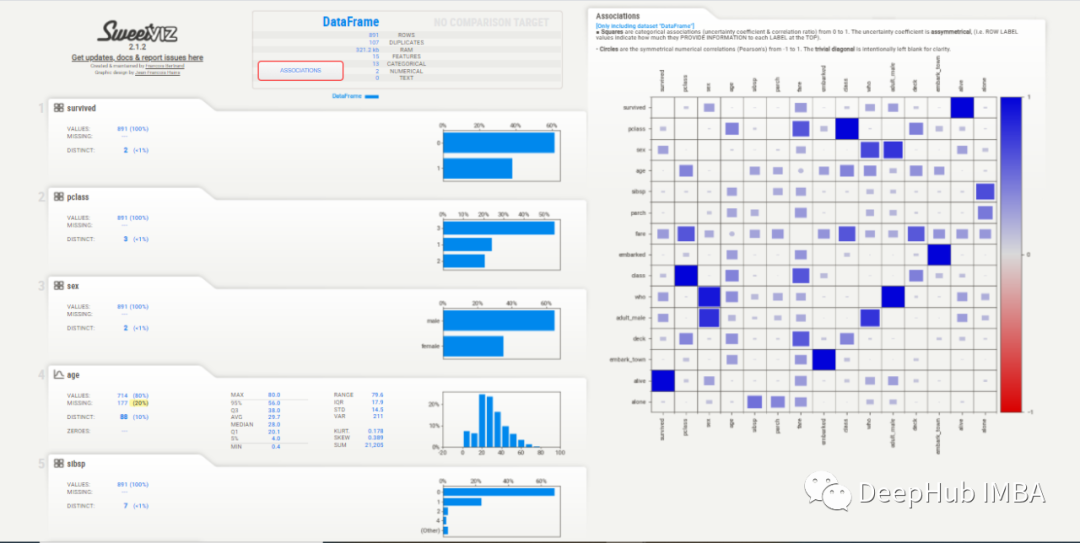
为了测试这些库的功能,本文使用了两个不同的数据集,只是为了更好地理解这些库如何处理不同类型的数据。
YData-Profiling
以前被称为Pandas Profiling,在今年改了名字。如果你搜索任何与EDA自动化相关的内容时,它都会作为第一个结果出现,这也是有充分理由的。
这个库最有用和最常用的是ProfileReport()命令。它生成整个数据集的详细摘要,报告对于获得数据的概览非常有用,特别是如果你不知道从哪里或如何开始分析(通常是这种情况)。这对于那些想要节省时间的新手或有经验的分析师来说非常有用。该报告提供单变量分布,突出数据质量问题,并创建相关性。让我们看一下患者风险概况数据的报告:
patient\_data = pd.read\_csv('/kaggle/input/patient-risk-profiles/patient\_risk\_profiles.csv')
zomato\_data=pd.read\_csv('/kaggle/input/zomato-data-40k-restaurants-of-indias-100-cities/zomato\_dataset.csv')
from ydata\_profiling import ProfileReport
patient\_report=ProfileReport(patient\_data)
patient\_report
zomato\_report=ProfileReport(zomato\_data)
zomato\_report
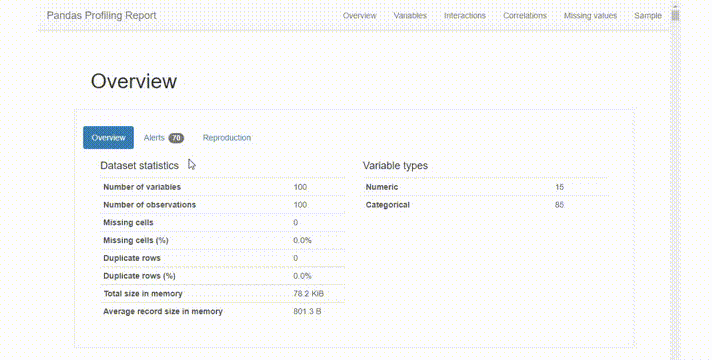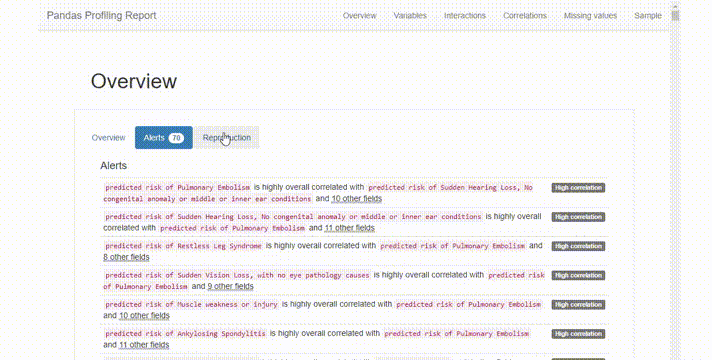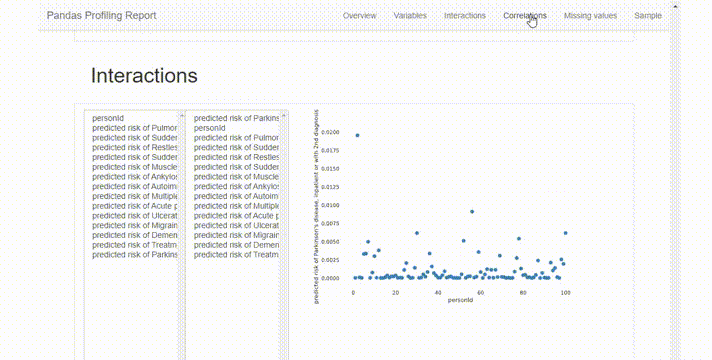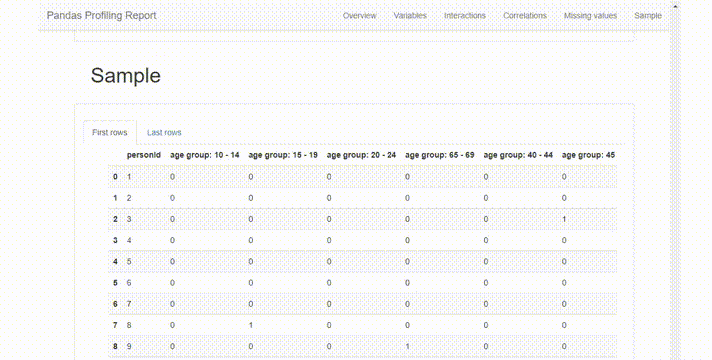
这份报告在很直观,也非常全面,它提供了一个很好的概述:
变量统计的简明概述,缺失值的百分比,重复值等。
在Alerts选项卡的简单文本中高亮显示数据质量问题,如高相关性,类不平衡等。
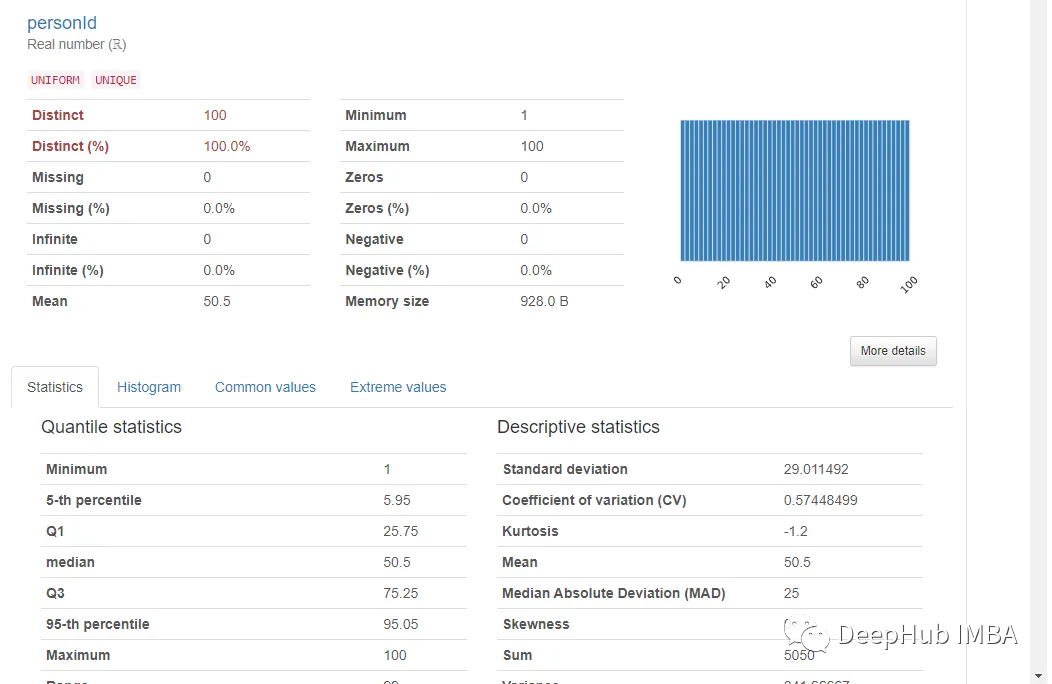
在variables 选项卡中给出了所有变量的单变量分析。有助于了解该变量的分布和统计特性。
点击变量下的“More Details”可以提供对各种其他统计数据,直方图,常见值和极值的更深入分析。基本上包含了一般我们想要知道的所有信息。
对于文本变量,报告生成了一个类似于NLP的概述,如下所示:

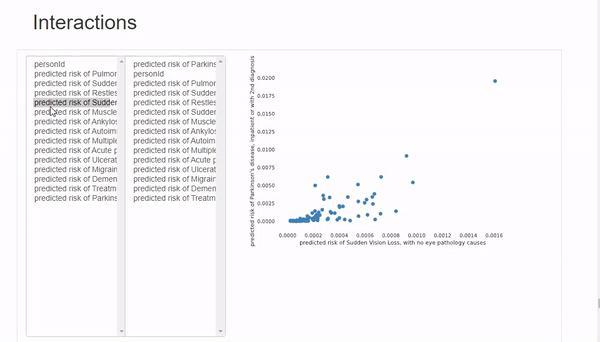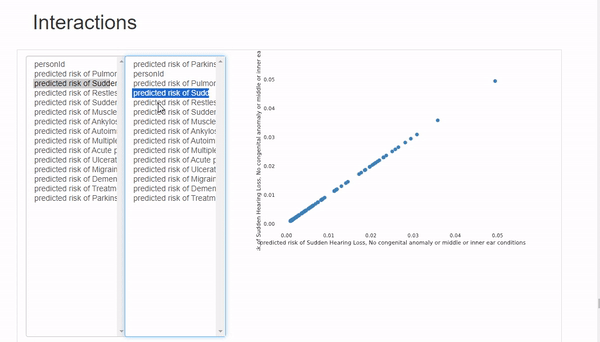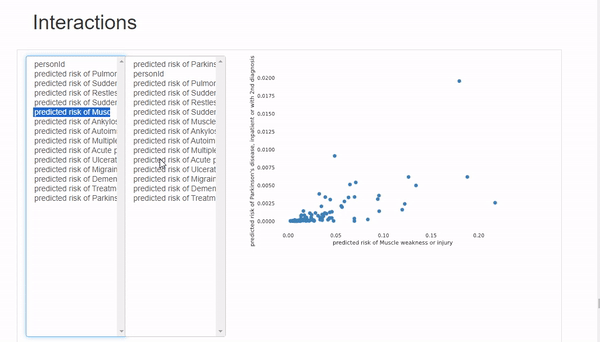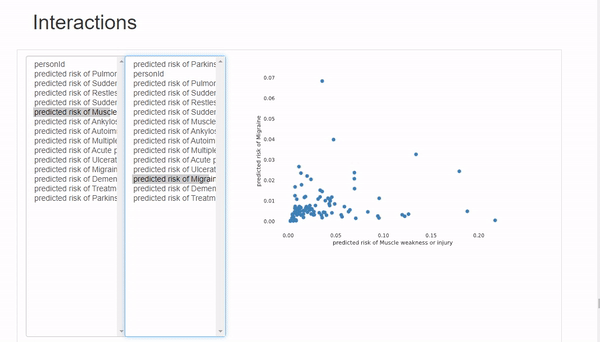
Interactions选项卡可以进行双变量分析,其中x轴变量在左列,y轴变量在右列。可以混搭来观察变量之间的相关性。这里唯一的限制是可用的图表类型只有散点图,所以如果想使用不同类型的图表,必须手动绘制。
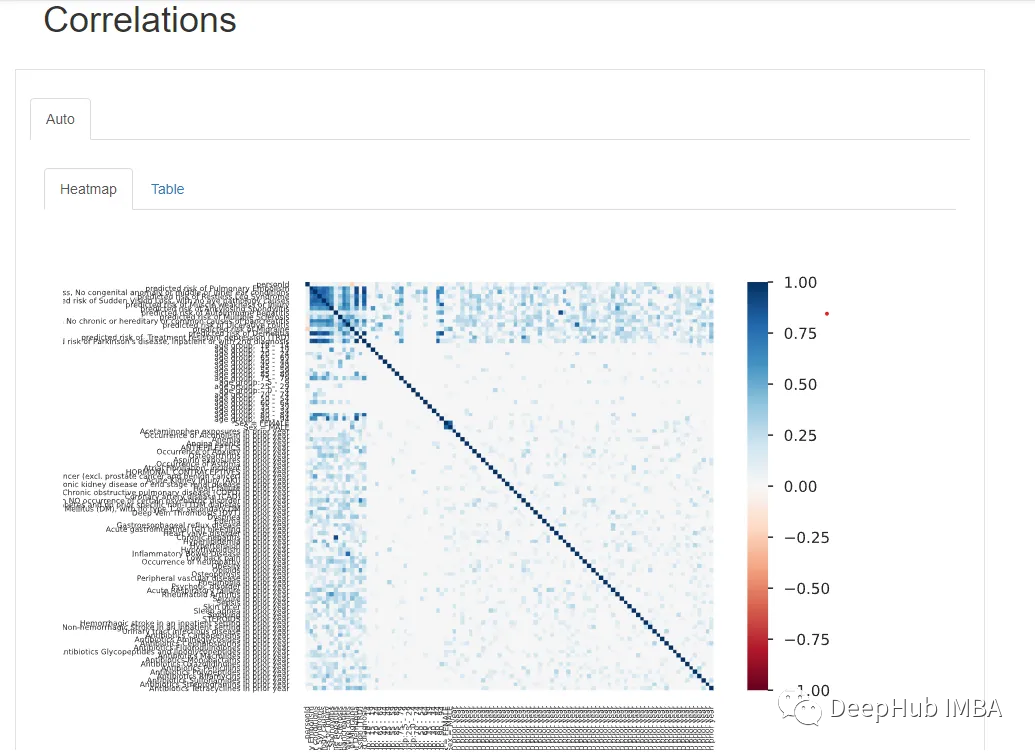
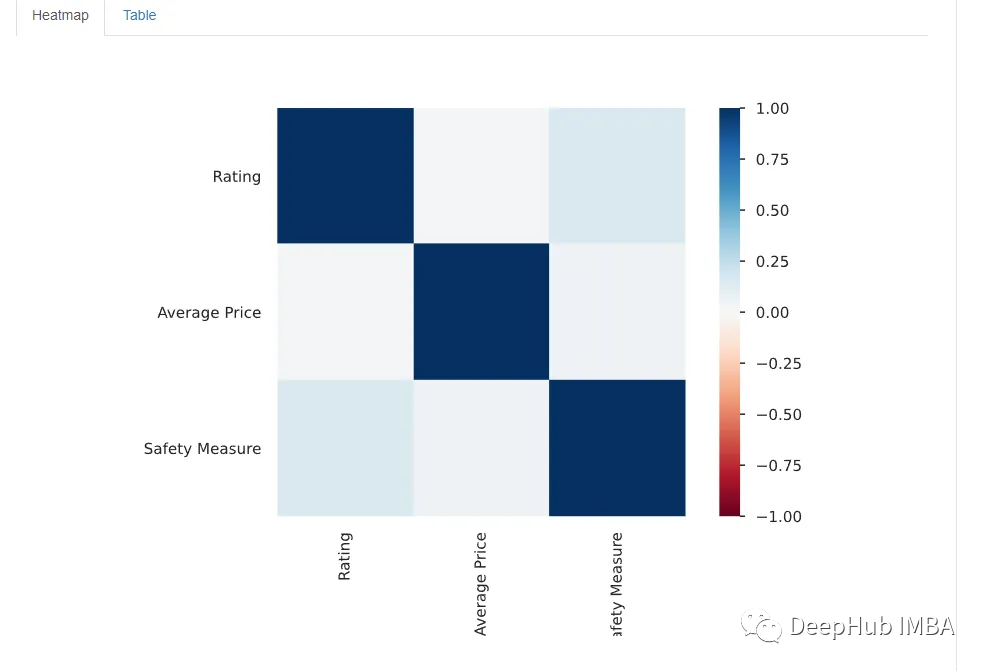
在Correlations 下,可以观察到所有变量的热图。但是由于变量数量太多,热图几乎难以辨认,所以最好是用自定义参数绘制手动热图。
最后还显示了缺失值和相应的列,以及重复的行(如果有的话)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1449
1449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









