









 本文探讨了降维和降采样的必要性及其方法,包括主成分分析(PCA)和线性判别分析(LDA),并通过实例展示了这些技术如何帮助简化数据集并提升分类效果。
本文探讨了降维和降采样的必要性及其方法,包括主成分分析(PCA)和线性判别分析(LDA),并通过实例展示了这些技术如何帮助简化数据集并提升分类效果。
一、降维的必要性
1.多重共线性–预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
2.高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有0.02%。
3.过多的变量会妨碍查找规律的建立。
4.仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
降维的目的:
1.减少预测变量的个数
2.确保这些变量是相互独立的
3.提供一个框架来解释结果
降维的方法有:主成分分析、因子分析、用户自定义复合等。
二、降采样
用的原理就是池化,有两种方法:最大池化和品平均池化
降采样 又名 下采样或缩小图像。即是采样点数减少。对于一幅N*M的图像来说,如果降采样系数为k,则即是在原图中 每行每列每隔k个点取一个点组成一幅图像。降采样很容易实现.
他的目的有两个。
(1)使得图像符合显示区域的大小。
(2)生成对应图像的缩略图
上采样 又名图像插值或放大图像 主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。升采样,也即插值。对于图像来说即是二维插值。如果升采样系数为k,即在原图n与n+1两点之间插入k-1个点,使其构成k分。二维插值即在每行插完之后对于每列也进行插值。
插 值的方法分为很多种,一般主要从时域和频域两个角度考虑。对于时域插值,最为简单的是线性插值。除此之外,Hermite插值,样条插值等等均可以从有关 数值分析书中找到公式,直接代入运算即可。对于频域,根据傅里叶变换性质可知,在频域补零等价于时域插值。所以,可以通过在频域补零的多少实现插值运 算
对图像的缩放操作并不能带来更多关于该图像的信息,因此图像的质量将不可避免地收到影响。然而确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量。
三、PCA和LDA
LDA
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种supervised learning。有些资料上也称为是Fisher’s Linear Discriminant,因为它被Ronald Fisher发明自1936年,Discriminant这次词我个人的理解是,一个模型,不需要去通过概率的方法来训练、预测数据,比如说各种贝叶斯方法,就需要获取数据的先验、后验概率等等。LDA是在目前机器学习、数据挖掘领域经典且热门的一个算法,据我所知,百度的商务搜索部里面就用了不少这方面的算法。
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。要说明白LDA,首先得弄明白线性分类器(Linear Classifier):因为LDA是一种线性分类器。对于K-分类的一个分类问题,会有K个线性函数:
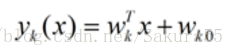
当满足条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。对于每一个分类,都有一个公式去算一个分值,在所有的公式得到的分值中,找一个最大的,就是所属的分类了。
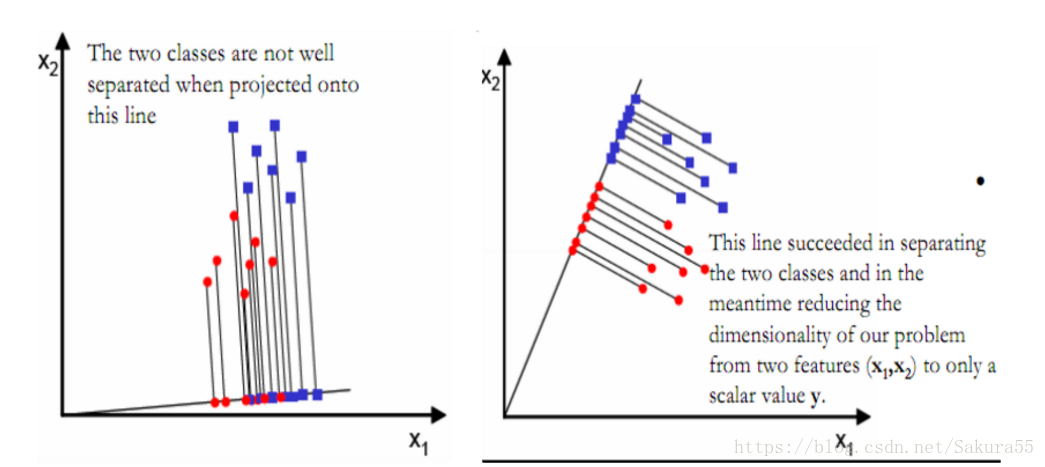
上式实际上就是一种投影,是将一个高维的点投影到一条高维的直线上,LDA最求的目标是,给出一个标注了类别的数据集,投影到了一条直线之后,能够使得点尽量的按类别区分开,当k=2即二分类问题的时候,如下图所示:
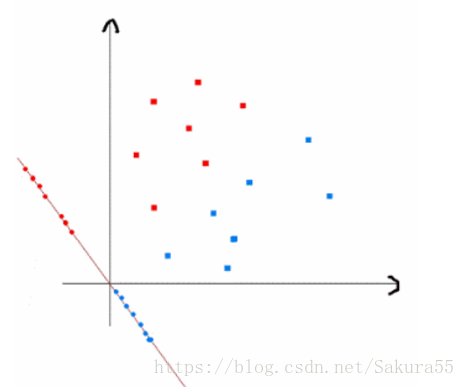
红色的方形的点为0类的原始点、蓝色的方形点为1类的原始点,经过原点的那条线就是投影的直线,从图上可以清楚的看到,红色的点和蓝色的点被原点明显的分开了,这个数据只是随便画的,如果在高维的情况下,看起来会更好一点。下面我来推导一下二分类LDA问题的公式:
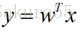
假设用来区分二分类的直线(投影函数)为:
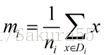
类别i投影后的中心点为:

衡量类别i投影后,类别点之间的分散程度(方差)为:

最终我们可以得到一个下面的公式,表示LDA投影到w后的损失函数:

我们分类的目标是,使得类别内的点距离越近越好(集中),类别间的点越远越好。分母表示每一个类别内的方差之和,方差越大表示一个类别内的点越分散,分子为两个类别各自的中心点的距离的平方,我们最大化J(w)就可以求出最优的w了。想要求出最优的w,可以使用拉格朗日乘子法,但是现在我们得到的J(w)里面,w是不能被单独提出来的,我们就得想办法将w单独提出来。
我们定义一个投影前的各类别分散程度的矩阵,这个矩阵看起来有一点麻烦,其实意思是,如果某一个分类的输入点集Di里面的点距离这个分类的中心店mi越近,则Si里面元素的值就越小,如果分类的点都紧紧地围绕着mi,则Si里面的元素值越更接近0.

这样就可以用最喜欢的拉格朗日乘子法了,但是还有一个问题,如果分子、分母是都可以取任意值的,那就会使得有无穷解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧,在下面将说的PCA里面也会用到,如果忘记了,请复习一下高数),并作为拉格朗日乘子法的限制条件,带入得到:

PCA
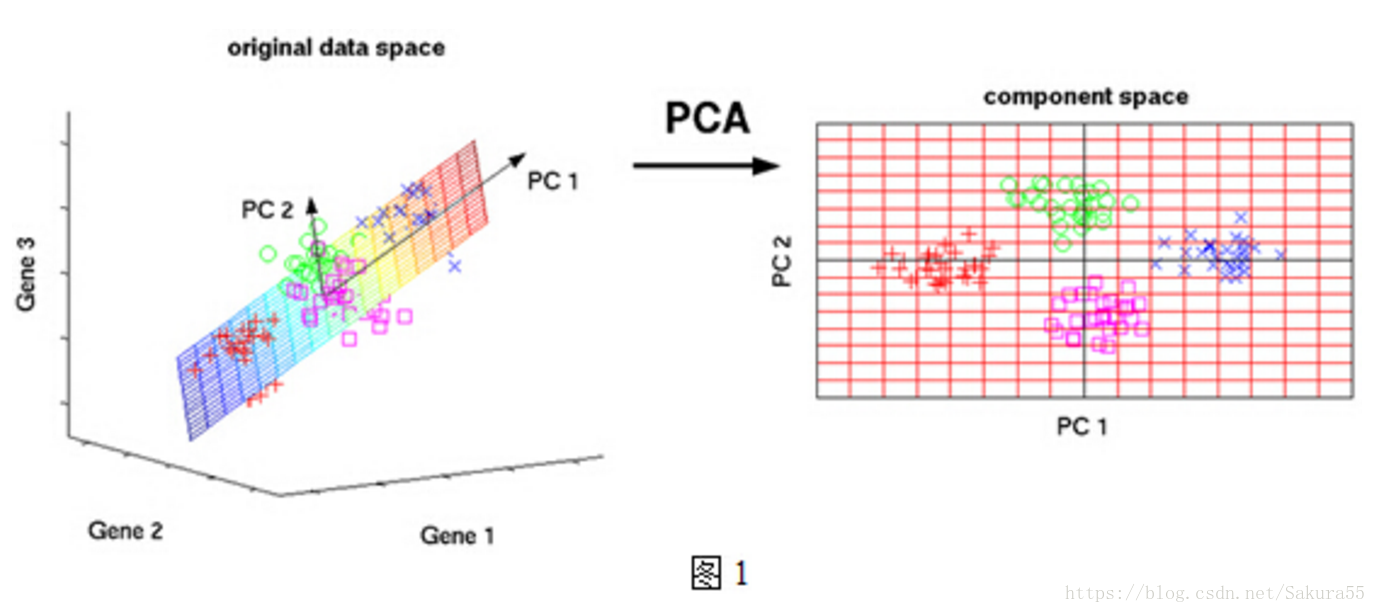
PCA能找到数据中的相似性和不同性。如果能找到数据中的一些相似性,PCA就能对数据进行压缩,即降维,但是不会损失数据的信息
¤ 计算步骤
——》Setp1:得到数据
——》Setp2:原始数据减去均值
——》Step3:计算协方差矩阵
——》Step4:计算协方差矩阵的特征值和特征函数。
——》Step5:选择主成份(主要的特征向量),形成特征向量
——》Step6:生成新的降维数据集
主成分分析(PCA)与LDA有着非常近似的意思,LDA的输入数据是带标签的,而PCA的输入数据是不带标签的,所以PCA是一种unsupervised learning。LDA通常来说是作为一个独立的算法存在,给定了训练数据后,将会得到一系列的判别函数(discriminate function),之后对于新的输入,就可以进行预测了。而PCA更像是一个预处理的方法,它可以将原本的数据降低维度,而使得降低了维度的数据之间的方差最大(也可以说投影误差最小,具体在之后的推导里面会谈到)。
下面将用两种思路来推导出一个同样的表达式。首先是最大化投影后的方差,其次是最小化投影后的损失(投影产生的损失最小)。
最大化方差法

最小化损失法
假设输入数据x是在D维空间中的点,那么,我们可以用D个正交的D维向量去完全的表示这个空间(这个空间中所有的向量都可以用这D个向量的线性组合得到)。在D维空间中,有无穷多种可能找这D个正交的D维向量,哪个组合是最合适的呢?

<script type="math/tex" id="MathJax-Element-18">~</script>
★参考机器中的数学

















 2968
2968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









