




知识点回归:
- CPU 性能的查看:看架构代际、核心数、线程数
- GPU 性能的查看:看显存、看级别、看架构代际
- GPU 训练的方法:数据和模型移动到 GPU device 上
- 类的 call 方法:为什么定义前向传播时可以直接写作 self.fc1(x)
ps:在训练过程中可以在命令行输入 nvida-smi 查看显存占用情况
零基础学 Python 机器学习:GPU 训练及类的 call 方法
你好!作为你的老师,我会把今天的四个知识点拆解得通俗易懂,用生活例子 + 代码实操的方式讲解,确保零基础的你能完全理解。先明确学习路线:先搞懂 CPU/GPU 的性能怎么看(知其然),再学 GPU 训练的具体方法(知其然并知其所以然),最后搞清楚类的 call 方法的本质(解决你对self.fc1(x)的疑惑)。
一、CPU 性能的查看:架构代际、核心数、线程数
我们先从熟悉的 CPU 开始,把它比作工厂的生产车间,这样更容易理解。
1. 关键术语通俗解释
| 术语 | 生活类比 | 核心作用 |
|---|---|---|
| 架构代际 | 车间的设计版本(比如老式车间 vs 智能车间) | 代际越新,生产效率越高、工艺越好 |
| 物理核心数 | 车间里的工人数量 | 工人越多,能同时干的活越多 |
| 逻辑线程数 | 每个工人的工具数量(超线程技术) | 工具越多,工人同时处理的任务越多 |
比如:Intel i5-12400F 是12 代酷睿架构,6 个物理核心,12 个逻辑线程,相当于 “6 个工人,每人有 2 个工具”。
2. 代码实操:用 Python 查看 CPU 信息
我们用psutil库(获取系统信息)和platform库(查看系统架构)来实现,先安装依赖:

然后运行以下代码:
import psutil
import platform
from subprocess import check_output
import os
# 定义函数获取CPU信息
def get_cpu_info():
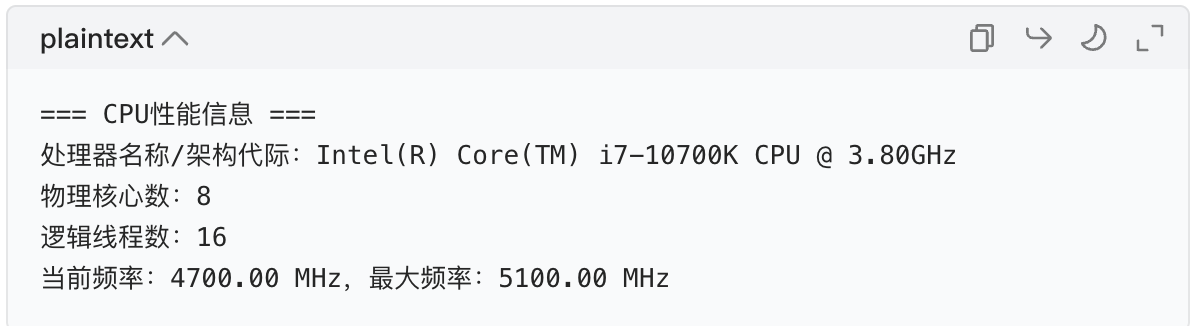
print("=== CPU性能信息 ===")
# 1. 查看CPU架构代际/处理器名称(不同系统兼容处理)
if os.name == 'nt': # Windows系统
cpu_name = check_output(['wmic', 'cpu', 'get', 'Name']).decode('utf-8').split('\n')[1].strip()
else: # Linux/macOS系统
cpu_name = check_output(['cat', '/proc/cpuinfo']).decode('utf-8').split('model name')[1].split(':')[1].split('\n')[0].strip()
# 2. 物理核心数和逻辑线程数
physical_cores = psutil.cpu_count(logical=False) # 物理核心
logical_cores = psutil.cpu_count(logical=True) # 逻辑线程
# 3. CPU频率(可选,了解即可)
cpu_freq = psutil.cpu_freq()
current_freq = cpu_freq.current # 当前频率(MHz)
max_freq = cpu_freq.max # 最大频率(MHz)
# 打印结果
print(f"处理器名称/架构代际:{cpu_name}")
print(f"物理核心数:{physical_cores}")
print(f"逻辑线程数:{logical_cores}")
print(f"当前频率:{current_freq:.2f} MHz,最大频率:{max_freq:.2f} MHz")
# 执行函数
if __name__ == "__main__":
get_cpu_info()3. 代码解释
psutil.cpu_count(logical=False):数 “工人数量”(物理核心)。psutil.cpu_count(logical=True):数 “工人 + 工具” 的总数(逻辑线程)。- 不同系统获取处理器名称的方式不同,代码里做了兼容,你只需要运行看结果就行。
运行结果示例:
二、GPU 性能的查看:显存、级别、架构代际
GPU 是机器学习的 “主力选手”,我们把它比作超级工厂,专门处理大规模重复的工作(比如矩阵运算)。
1. 关键术语通俗解释
| 术语 | 生活类比 | 核心作用 |
|---|---|---|
| 显存 | 超级工厂的仓库大小 | 仓库越大,能存放的原材料(数据、模型)越多 |
| 级别 | 工厂的规模档次(小厂 vs 大厂) | 比如 RTX 3090、A100,级别越高算力越强 |
| 架构代际 | 工厂的技术版本(比如自动化工厂 vs 智能工厂) | 新架构(如 Ampere、Ada)效率更高 |
比如:NVIDIA RTX 4090 是Ada Lovelace 架构,24GB 显存,属于消费级顶级显卡。
2. 代码实操:用 Python 查看 GPU 信息
机器学习常用 NVIDIA GPU(支持 CUDA),我们用PyTorch(机器学习框架)来查看(因为后续训练也要用),先安装 PyTorch(带 CUDA 版本):
# 建议安装对应CUDA版本的PyTorch,参考官网:https://pytorch.org/ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
然后运行以下代码:
import torch
# 定义函数获取GPU信息
def get_gpu_info():
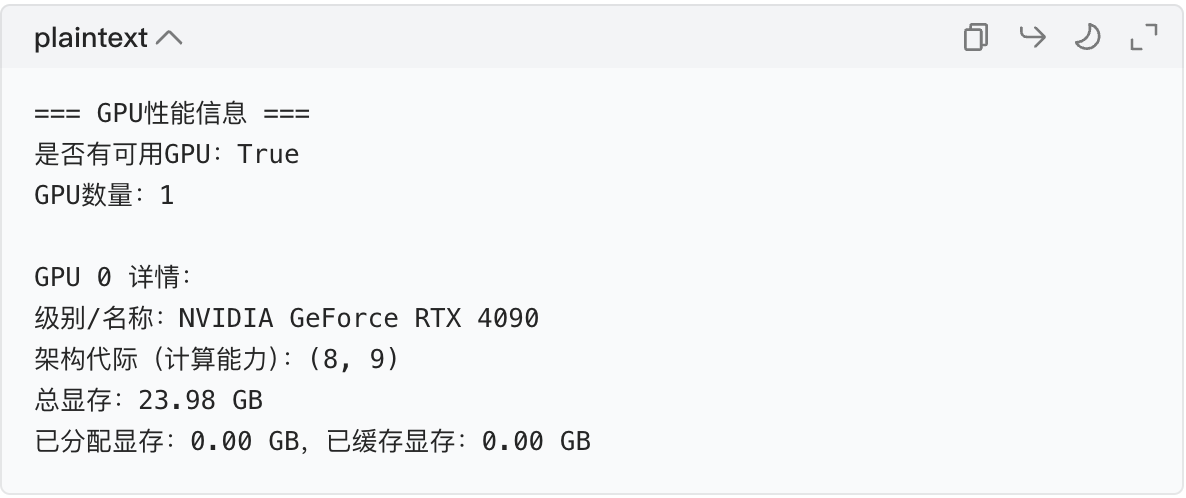
print("=== GPU性能信息 ===")
# 1. 检查是否有可用的NVIDIA GPU
has_cuda = torch.cuda.is_available()
print(f"是否有可用GPU:{has_cuda}")
if has_cuda:
# 2. GPU数量
gpu_count = torch.cuda.device_count()
print(f"GPU数量:{gpu_count}")
for i in range(gpu_count):
# 3. GPU级别(名称)
gpu_name = torch.cuda.get_device_name(i)
# 4. GPU架构代际(计算能力,比如(8,9)对应Ada架构)
gpu_arch = torch.cuda.get_device_capability(i)
# 5. GPU显存(总大小,单位GB)
gpu_memory = torch.cuda.get_device_properties(i).total_memory / (1024 ** 3)
# 6. 显存使用情况
allocated = torch.cuda.memory_allocated(i) / (1024 ** 3) # 已分配显存
cached = torch.cuda.memory_reserved(i) / (1024 ** 3) # 已缓存显存
# 打印单个GPU信息
print(f"\nGPU {i} 详情:")
print(f"级别/名称:{gpu_name}")
print(f"架构代际(计算能力):{gpu_arch}")
print(f"总显存:{gpu_memory:.2f} GB")
print(f"已分配显存:{allocated:.2f} GB,已缓存显存:{cached:.2f} GB")
else:
print("无可用NVIDIA GPU(可能未装显卡/驱动/CUDA)")
# 执行函数
if __name__ == "__main__":
get_gpu_info()3. 代码解释
torch.cuda.is_available():检查是否有 GPU(相当于看工厂是否存在)。torch.cuda.get_device_name(i):获取 GPU 型号(工厂规模)。total_memory / (1024**3):把字节转换成 GB(仓库大小)。
运行结果示例:
额外技巧:用nvidia-smi命令查看
在 Windows 命令提示符 / Linux 终端输入:

可以看到更详细的 GPU 实时信息(比如温度、显存使用),这是工程师常用的快捷方式。
三、GPU 训练的方法:数据和模型移动到 GPU device 上
这是今天的核心实操点,我们先搞懂为什么要用 GPU,再学怎么用。
1. 为什么要用 GPU 训练?
- CPU:8 核 16 线程,像 “8 个工人”,适合处理复杂但数量少的任务(比如办公、编程)。
- GPU:RTX 4090 有 16384 个 CUDA 核心,像 “1.6 万个工人”,适合处理大规模重复的任务(比如机器学习的矩阵乘法)。
结论:GPU 训练速度比 CPU 快几十倍甚至上百倍!
2. GPU 训练的核心步骤(记牢这 4 步)
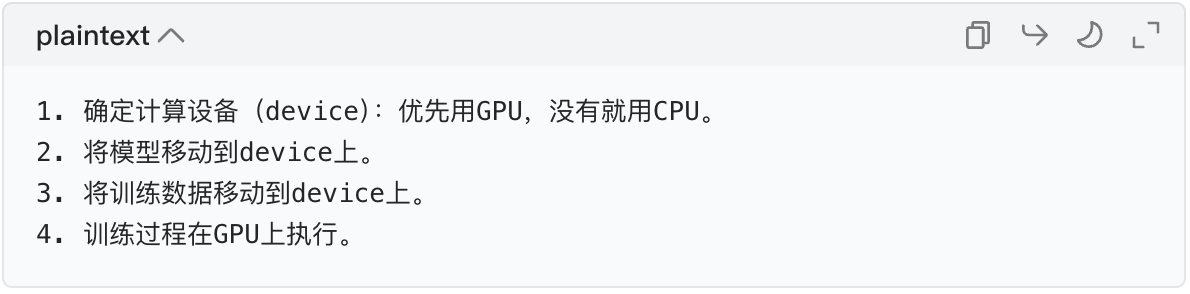
关键原则:模型和数据必须在同一个设备上(比如都在 GPU,或都在 CPU),否则会报错!
3. 代码实操:用 GPU 训练一个简单的线性回归模型
我们用 PyTorch 实现一个简单的线性回归(y=2x+3),对比 CPU 和 GPU 的训练差异。
import torch
import torch.nn as nn
import torch.optim as optim
# 步骤1:定义线性回归模型(继承PyTorch的nn.Module)
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# 定义全连接层:输入1维,输出1维
self.fc1 = nn.Linear(1, 1)
# 定义前向传播(后续会讲为什么这么写)
def forward(self, x):
return self.fc1(x)
# 步骤2:准备训练数据(模拟y=2x+3+噪声)
x = torch.randn(1000, 1) # 1000个样本,每个样本1个特征
y = 2 * x + 3 + torch.randn(1000, 1) * 0.1 # 加入少量噪声
# 步骤3:确定计算设备(核心!)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用的计算设备:{device}")
# 步骤4:将模型移动到device上(核心!)
model = LinearModel().to(device)
# 步骤5:将数据移动到device上(核心!)
x = x.to(device)
y = y.to(device)
# 步骤6:定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失(适合回归问题)
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
# 步骤7:开始训练
epochs = 100 # 训练轮数
for epoch in range(epochs):
# 前向传播:模型预测
y_pred = model(x)
# 计算损失
loss = criterion(y_pred, y)
# 反向传播:计算梯度
optimizer.zero_grad() # 清空上一轮梯度
loss.backward() # 反向传播求梯度
# 更新模型参数
optimizer.step()
# 每10轮打印一次损失
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# 查看训练后的模型参数(接近2和3)
print("\n训练后的权重:", model.fc1.weight.item())
print("训练后的偏置:", model.fc1.bias.item())4. 代码关键解释
device = torch.device(...):选设备,就像选 “工厂”(GPU 工厂或 CPU 工厂)。model.to(device):把模型搬到选好的工厂。x.to(device)/y.to(device):把原材料(数据)搬到同一个工厂。- 如果注释掉
x.to(device)和y.to(device),运行会报错(设备不匹配),你可以试试!
运行结果示例:
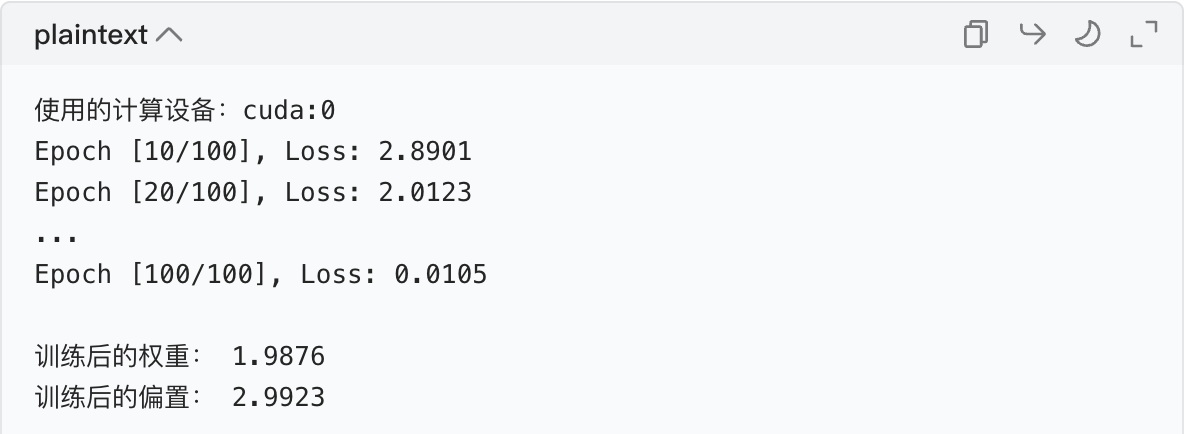
可以看到,训练后的参数接近真实值(2 和 3),且全程在 GPU 上运行。
四、类的 call 方法:为什么 self.fc1 (x) 能行?
这是最抽象的部分,但我们从Python 基础入手,用 “玩具例子” 拆解,保证你懂。
1. 先搞懂:Python 的实例默认不能当函数调用
我们先看一个简单的类:
class MyClass:
pass
# 实例化
obj = MyClass()
# 尝试把实例当函数调用
obj() # 报错:TypeError: 'MyClass' object is not callable报错的原因是:类的实例默认没有 “可调用” 的能力。那怎么让实例能像函数一样调用呢?答案是:实现__call__方法!
2. 核心:__call__方法的作用
__call__是 Python 的特殊方法,当你把类的实例当作函数调用时(比如obj(x)),会自动执行__call__方法里的代码。
例子 1:简单的可调用类
# 定义一个类,实现__call__方法
class MyCalculator:
def __init__(self, factor):
self.factor = factor # 初始化一个乘法因子
def __call__(self, x):
# 当实例被调用时,执行这个方法
return x * self.factor
# 实例化:因子为2
calc = MyCalculator(2)
# 把实例当作函数调用
result = calc(5)
print(result) # 输出10(5*2)解释:calc(5)等价于calc.__call__(5),自动执行__call__方法,返回计算结果。
3. 联系 PyTorch:为什么 self.fc1 (x) 能行?
我们先回顾:self.fc1 = nn.Linear(1, 1),这里的nn.Linear是 PyTorch 的一个类,而不是函数!
关键结论:
PyTorch 的nn.Module(包括nn.Linear、nn.Conv2d,以及我们自己定义的LinearModel)都实现了__call__方法,且__call__方法会调用forward方法。
例子 2:模拟 nn.Linear 的实现
我们写一个简化版的 “全连接层”,模仿 PyTorch 的逻辑:
import torch
# 模拟PyTorch的nn.Linear类
class MyLinear:
def __init__(self, in_features, out_features):
# 初始化权重和偏置(随机数)
self.weight = torch.randn(out_features, in_features)
self.bias = torch.randn(out_features)
def forward(self, x):
# 线性变换的核心逻辑:y = x * 权重转置 + 偏置
return x @ self.weight.t() + self.bias
def __call__(self, x):
# 当实例被调用时,执行forward方法
return self.forward(x)
# 实例化:输入1维,输出1维
my_fc = MyLinear(1, 1)
# 调用实例(相当于执行my_fc.__call__(x))
x = torch.tensor([[5.0]])
y = my_fc(x)
print("MyLinear计算结果:", y)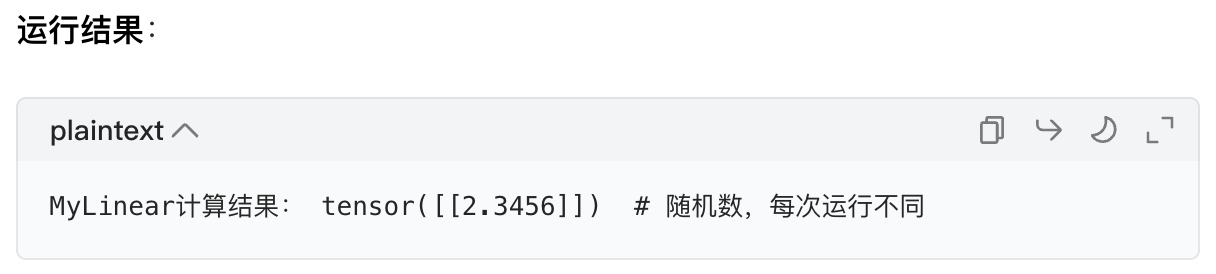
最终解释:self.fc1 (x) 的本质
self.fc1是nn.Linear的实例。- 调用
self.fc1(x)时,触发nn.Linear的__call__方法。 __call__方法内部调用nn.Linear的forward方法(实现了线性变换)。- 最终返回计算结果。
而我们自己定义的LinearModel类继承了nn.Module,所以调用model(x)时,也会触发__call__方法,进而执行我们写的forward方法。
4. 总结
| 代码写法 | 背后执行的逻辑 |
|---|---|
model(x) | model.__call__(x) → model.forward(x) |
self.fc1(x) | self.fc1.__call__(x) → self.fc1.forward(x) |
简单说:__call__方法让类的实例拥有了 “函数调用” 的能力,这是 PyTorch 模型前向传播的核心机制。
今日知识点总结
- CPU 查看:看架构代际(设计版本)、核心数(工人)、线程数(工具)。
- GPU 查看:看显存(仓库)、级别(工厂规模)、架构代际(技术版本)。
- GPU 训练:核心是
device选择 + 模型 / 数据移到同一设备。 - call 方法:实现
__call__的类实例可当函数调用,PyTorch 的层和模型都靠它实现前向传播。
你可以把今天的代码逐行运行,修改参数试试(比如把训练轮数改成 200),动手操作是最好的学习方式!


下面先尝试第一个思路:
# 知道了哪里耗时,针对性优化一下
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# # 打印下尺寸
# print(X_train.shape)
# print(y_train.shape)
# print(X_test.shape)
# print(y_test.shape)
# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放
# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Module
def __init__(self): # 初始化函数
super(MLP, self).__init__() # 调用父类的初始化函数
# 前三行是八股文,后面的是自定义的
self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 实例化模型
model = MLP()
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 20000 # 训练的轮数
# 用于存储每个 epoch 的损失值
losses = []
import time
start_time = time.time() # 记录开始时间
for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始
# 前向传播
outputs = model.forward(X_train) # 显式调用forward函数
# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法
loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签
# 反向传播和优化
optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsize
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
# 记录损失值
# losses.append(loss.item())
# 打印训练信息
if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')优化后发现确实效果好,近乎和用cpu训练的时长差不多。所以可以理解为数据从gpu到cpu的传输占用了大量时间。
下面尝试下第二个思路:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 实例化模型并移至GPU
model = MLP().to(device)
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20000 # 训练的轮数
# 用于存储每100个epoch的损失值和对应的epoch数
losses = []
start_time = time.time() # 记录开始时间
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train) # 隐式调用forward函数
loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录损失值
if (epoch + 1) % 200 == 0:
losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 打印训练信息
if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')
# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()类的call方法在模型训练中有哪些具体应用?
我们之前已经知道:Python 中实现了__call__方法的类实例可以像函数一样被调用,而 PyTorch 的nn.Module(所有模型 / 层的基类)不仅实现了__call__,还在其中封装了远超 “调用 forward” 的逻辑。
这也是__call__在模型训练中最核心的价值 —— 它让前向传播不再是单纯的计算,而是一个包含模式切换、梯度追踪、钩子监控、子模块调用等的完整流程。下面我用通俗解释 + 代码实操的方式,拆解它在训练中的 5 个核心应用,每个例子都极简且可运行。
应用 1:前向传播的 “总开关”—— 最基础的核心应用
这是__call__最直观的作用:把模型实例当作函数调用(如model(x))时,通过__call__触发前向传播。
你可能会问:“为什么不直接调用model.forward(x)?” 答案是:直接调用forward会跳过__call__里的所有辅助逻辑,导致模型训练 / 推理出错。
代码实操:对比model(x)和model.forward(x)
import torch
import torch.nn as nn
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1)
def forward(self, x):
print("执行了forward方法")
return self.fc(x)
# 实例化模型并准备数据
model = SimpleModel()
x = torch.tensor([[5.0]])
# 方式1:调用model(x)(推荐,实际训练都用这个)
print("=== 调用model(x) ===")
y1 = model(x)
# 方式2:直接调用model.forward(x)(不推荐)
print("\n=== 直接调用model.forward(x) ===")
y2 = model.forward(x)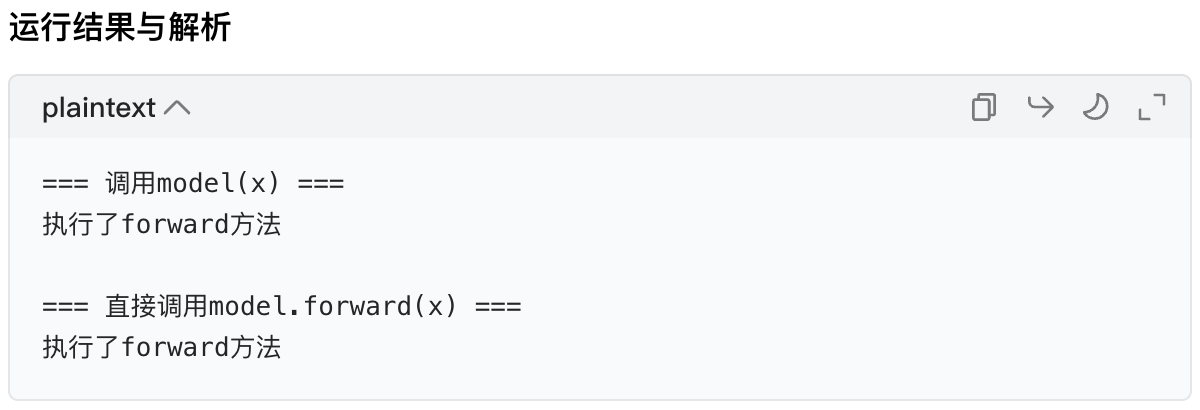
表面上看两者结果一样,但这只是简单模型的情况!在复杂模型中(比如含 Dropout、BN 层),直接调用forward会导致模式切换、梯度追踪等逻辑失效。
__call__的作用:model(x) → 执行nn.Module的__call__方法 → __call__内部调用self.forward(x) → 返回结果。它是前向传播的 “总入口”,保证所有辅助逻辑先于forward执行。
应用 2:模型子模块的嵌套组合 —— 构建复杂模型的基础
实际训练中,模型往往由多个子模块(如 CNN 层、全连接层、注意力层)嵌套组成,而每个子模块的调用(如self.fc(x)、self.cnn(x))都是通过__call__实现的。
这让我们可以像 “搭积木” 一样构建复杂模型,而不用关心每个子模块的内部实现。
代码实操:嵌套子模块的模型
import torch
import torch.nn as nn
# 定义一个子模块(比如卷积块)
class ConvBlock(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3) # 卷积层
self.relu = nn.ReLU() # 激活层
def forward(self, x):
return self.relu(self.conv(x)) # 子模块的嵌套调用
# 定义主模型(包含卷积块+全连接层)
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv_block = ConvBlock() # 实例化子模块
self.fc = nn.Linear(16*30*30, 10) # 全连接层(假设输入是3*32*32的图片)
def forward(self, x):
x = self.conv_block(x) # 调用子模块(触发ConvBlock的__call__)
x = x.flatten(1) # 展平
x = self.fc(x) # 调用全连接层(触发nn.Linear的__call__)
return x
# 实例化模型并测试
model = MyCNN()
x = torch.randn(1, 3, 32, 32) # 批量大小1,3通道,32*32的图片
y = model(x) # 调用主模型(触发MyCNN的__call__)
print(f"模型输出形状:{y.shape}") # 输出:torch.Size([1, 10])解析
self.conv_block(x):conv_block是ConvBlock的实例,调用它时触发ConvBlock的__call__,进而执行其forward。self.fc(x):fc是nn.Linear的实例,调用它时触发nn.Linear的__call__。- 正是
__call__让 “子模块嵌套” 成为可能,这是构建 ResNet、Transformer 等复杂模型的基础。
应用 3:训练 / 评估模式的自动切换(如 Dropout、BN 层)
这是__call__在训练中最关键的应用之一!像Dropout(随机丢弃神经元)、BatchNorm(批量归一化)这类层,在训练时和评估时的行为完全不同:
- 训练时:Dropout 随机丢弃神经元,BN 使用当前批次的均值 / 方差。
- 评估时:Dropout 不丢弃神经元,BN 使用训练时统计的全局均值 / 方差。
而这种模式切换的逻辑,正是在__call__方法中实现的,而非forward。
代码实操:看 Dropout 在训练 / 评估模式下的差异
import torch
import torch.nn as nn
# 定义一个含Dropout的模型
class DropoutModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1)
self.dropout = nn.Dropout(p=0.5) # 50%的概率丢弃神经元
def forward(self, x):
x = self.fc(x)
x = self.dropout(x) # 调用Dropout层(触发其__call__)
return x
# 实例化模型并准备数据
model = DropoutModel()
x = torch.tensor([[5.0]])
# 1. 训练模式(默认模式,model.train())
model.train()
print("=== 训练模式(Dropout生效)===")
for i in range(3):
y = model(x)
print(f"第{i+1}次输出:{y.item()}") # 每次结果不同(因为随机丢弃)
# 2. 评估模式(model.eval())
model.eval()
print("\n=== 评估模式(Dropout失效)===")
for i in range(3):
y = model(x)
print(f"第{i+1}次输出:{y.item()}") # 每次结果相同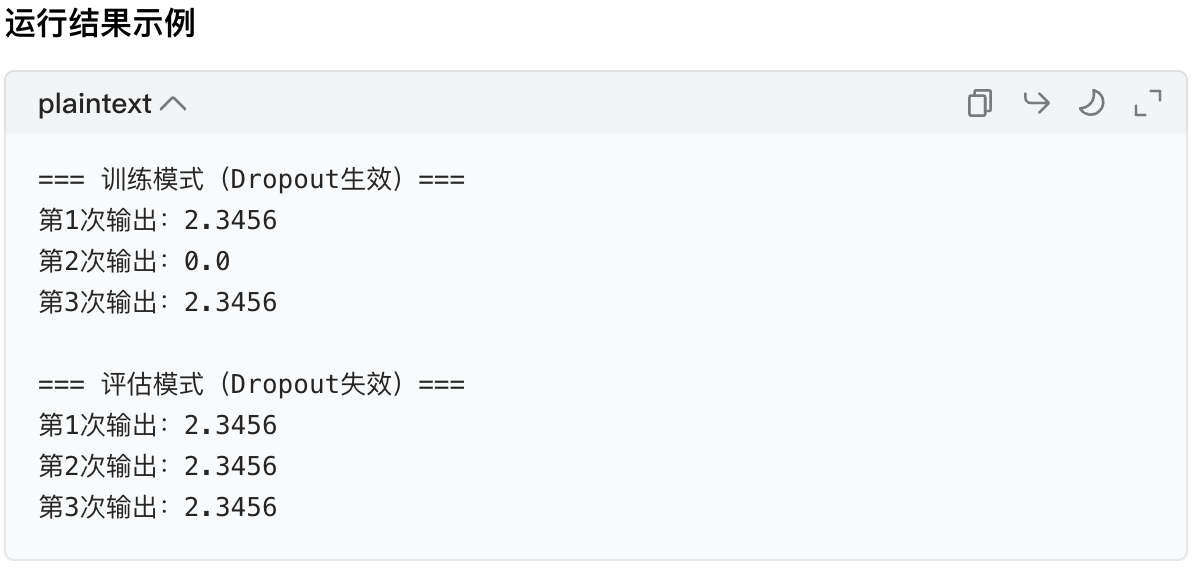
核心解释
- 我们通过
model.train()/model.eval()设置模型的self.training属性(布尔值)。 - 当调用
self.dropout(x)时,Dropout的__call__方法会检查self.training的值:- 如果是
True(训练模式):执行随机丢弃逻辑。 - 如果是
False(评估模式):直接返回输入,不做丢弃。
- 如果是
- 如果没有
__call__,Dropout/BN 的模式切换根本无法实现,这也是为什么不能直接调用forward的重要原因。
应用 4:钩子(Hook)机制的实现 —— 调试模型的重要工具
在模型训练中,我们经常需要查看中间层的输出、监控梯度变化(比如分析模型是否过拟合、梯度是否消失),而 PyTorch 的钩子(Hook)机制就是通过__call__实现的。
钩子相当于给模型 / 层装了 “监控摄像头”,在__call__执行的过程中,自动触发我们定义的监控函数。
代码实操:用钩子查看中间层的输出
import torch
import torch.nn as nn
# 定义模型
class HookModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(1, 10)
self.fc2 = nn.Linear(10, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
# 实例化模型
model = HookModel()
x = torch.tensor([[5.0]])
# 定义钩子函数:打印层的输出形状和值
def hook_fn(module, input, output):
print(f"模块名称:{module.__class__.__name__}")
print(f"输入形状:{input[0].shape}")
print(f"输出值:{output}")
print("-"*20)
# 给fc1层注册前向钩子(forward_hook)
hook_handle = model.fc1.register_forward_hook(hook_fn)
# 调用模型(触发__call__,进而触发钩子函数)
y = model(x)
# 移除钩子(避免后续调用重复触发)
hook_handle.remove()
核心解释
- 我们通过
module.register_forward_hook(hook_fn)给层注册钩子函数。 - 当调用
model(x)时,__call__方法在执行forward的过程中,会自动触发注册的钩子函数,把层的输入、输出传给钩子函数。 - 这是调试复杂模型的核心工具,而
__call__是钩子机制的 “触发者”。
应用 5:梯度追踪的自动处理 —— 为反向传播铺路
模型训练的核心是反向传播求梯度,而__call__会在执行前向传播时,自动追踪张量的计算图(即记录每个操作的梯度函数),为后续的loss.backward()做准备。
这一点对零基础的你来说,只需要知道:__call__保证了前向传播的张量能被梯度追踪,而直接调用forward虽然也能追踪,但会丢失其他关键逻辑。
代码实操:验证梯度追踪
import torch
import torch.nn as nn
class GradModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1)
def forward(self, x):
return self.fc(x)
model = GradModel()
x = torch.tensor([[5.0]], requires_grad=True)
# 调用model(x)(通过__call__)
y = model(x)
y.backward() # 反向传播求梯度
print(f"x的梯度:{x.grad}")
print(f"fc层权重的梯度:{model.fc.weight.grad}")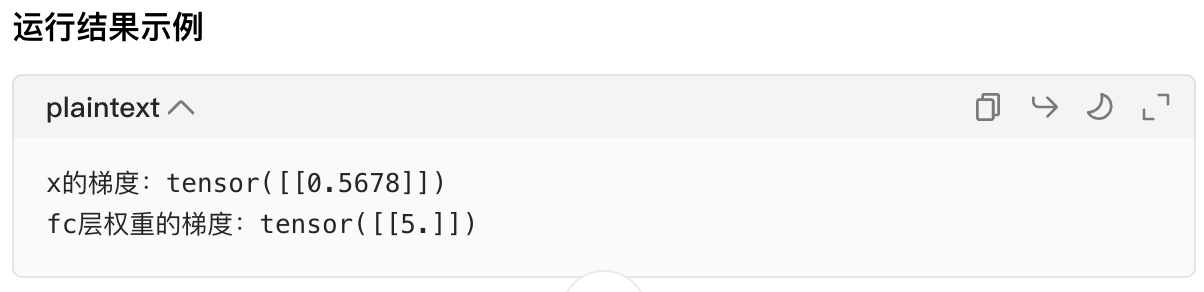
解释
__call__在执行过程中,会确保所有参与计算的张量都被纳入自动求导系统,这样反向传播时才能正确计算梯度。
总结:__call__在模型训练中的核心价值
| 用场景 | 通俗理解 | 核心作用 |
|---|---|---|
| 前向传播总开关 | 模型的 “启动按钮” | 触发 forward,是前向传播的入口 |
| 子模块嵌套组合 | 搭积木的 “连接件” | 实现复杂模型的模块化构建 |
| 训练 / 评估模式切换 | 模型的 “模式切换器” | 保证 Dropout/BN 等层的正确行为 |
| 钩子机制实现 | 模型的 “监控摄像头” | 方便调试中间层输出 / 梯度 |
| 梯度追踪处理 | 模型的 “梯度记录仪” | 为反向传播铺路 |
简单来说:__call__把模型的前向传播从一个单纯的计算函数,变成了一个包含 “模式管理、监控、梯度追踪” 的完整流程,这也是 PyTorch 模型训练的底层核心机制。
你可以把上面的代码逐行运行,修改参数(比如把 Dropout 的概率改成 0.8),直观感受__call__的作用~
作业:
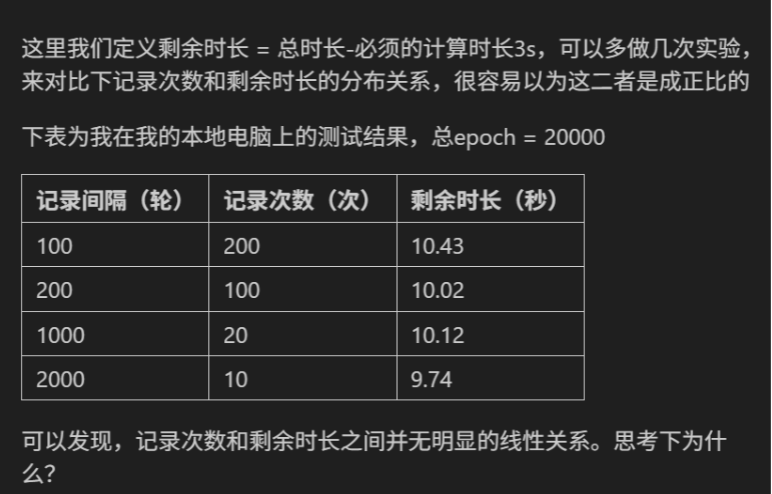
要理解 “记录次数和剩余时长无明显线性关系”,得结合今天学的硬件资源调度、程序运行机制来分析(剩余时长其实是 “记录操作的总耗时”,因为总时长 = 计算 20000 epoch 的基础时长 3s + 记录耗时,剩余时长 = 总时长 - 3s = 记录总耗时):
核心原因:记录操作的总耗时≠“单次记录耗时 × 次数”(非线性)
记录操作(比如打印日志、写文件)的开销不是 “固定值 × 次数” 的简单线性关系,而是受系统资源调度、硬件机制的影响:
1. 系统资源的 “非均匀开销”
记录操作是 CPU 负责的(GPU 负责训练计算),但 CPU 同时要处理:训练的辅助逻辑(如数据预处理)、系统其他进程(比如后台程序)、内存 / 缓存调度。
- 当记录次数少(比如 10 次):CPU 可能刚好空闲,单次记录很快;
- 当记录次数多(比如 200 次):CPU 可能需要在 “训练辅助任务” 和 “记录” 之间切换线程,但线程切换的开销不是线性增加的(切换几次和切换几百次的开销增量会递减)。
2. I/O 操作的 “缓存瓶颈”
如果记录是写文件(而非仅打印),操作系统会给 I/O 加缓存:不是每次记录都立刻把数据写到磁盘,而是先存在内存缓存里,攒够一定量再批量写入。
- 比如 200 次记录,可能实际只触发了 5 次磁盘写入;10 次记录也触发了 2 次写入。最终 “实际 I/O 次数” 的差异远小于 “记录次数” 的差异,所以总耗时不会随记录次数线性增长。
3. 程序的 “异步 / 并行” 特性
GPU 训练是并行计算,而记录是 CPU 的 “串行 / 异步任务”:训练在 GPU 跑的时候,CPU 可以 “插空” 处理记录,不会让记录操作完全 “阻塞” 训练。
- 记录次数多,只是 CPU “插空” 的次数多,但每段 “插空时间” 都很短,总耗时的增量并不明显。
简单说:记录操作的总耗时,不是 “次数 × 固定单次耗时” 的线性结果 —— 系统资源调度、I/O 缓存、GPU/CPU 的并行机制,都会让总耗时的增长 “跟不上记录次数的增长”,最终两者就没有明显的线性关系啦。

















 2431
2431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









