






WordCount
数据准备:
a.txt
lxy lxy
lxy zhang
wsoossj liagn
guui
liang
liagn
代码(在idea中创建一个Maven工程):
mapper:
该类是在map阶段被MapTask调用 用来实现MapTask要实现的业务逻辑代码
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
第一组
KEYIN:读取的数据的偏移量的类型
VALUEIN :一行一行的数据的类型
第二组
KEYOUT : 写出的数据的key的类型在这是单词的类型
VALUEOUT :写出的数据的value的类型在这是单词的数量的类型
package com.lxy.mr.wordcount.thi;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/13
* Time: 18:53
*/
public class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
/**
* 在map方法中用来实现需要在MapTask中实现的功能
* map方法是在被循环调用(框架调用的) 每调用一次传入一行数据
*
* @param key 读取数据的偏移量
* @param value 一行一行的数据
* @param context 上下文在这用来将key,value写出去
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//1.对字符串进行切割
String line = value.toString();
//遍历数组
for (String word : line.split(" ")) {//切割数据
//封装key,value
//封装key
Text outKey = new Text();
outKey.set(word);
//封装value
LongWritable outValue = new LongWritable();
outValue.set(1);
//3.将Key,value写出去
context.write(outKey,outValue);
}
}
}
reducer
该类是在reduce阶段被ReduceTask调用 用来实现ReduceTask要实现的业务逻辑代码
Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
第一组:
KEYIN :读取的key的类型(map写出的key的类型)-在这是单词的类型
VALUEIN :读取的value的类型(map写出的value的类型)-在这是单词的数量的类型
第二组:
KEYOUT : 写出的key的类型-在这是单词的类型
VALUEOUT :写出的value的类型 - 在这是单词数量的类型
package com.lxy.mr.wordcount.thi;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer;
import javax.xml.soap.Text;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/13
* Time: 18:59
*/
public class WCReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
/**
* 在reduce方法中用来实现需要在ReduceTask中实现的功能
* reduce方法在被循环调用每调用一次传入一组数据
*
* @param key 读取的key - 单词
* @param values 存放了所有的value - 单词的数量
* @param context 上下文在这用来将key,value写出去
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
/**
* Text LongWritable
* aaa 1
* aaa 1 =====> aaa 3
* aaa 1
*/
long sum = 0;
//1.遍历所有的value
for (LongWritable word : values) {
//将LongWritable转成long类型
long l = word.get();
//2.将value累加
//将value累加到sum中
sum += l;
}
//3.封装key,value 这里key没有变化不需要封装所以就不进行封装了
LongWritable outValue = new LongWritable();
//封装的value
outValue.set(sum);
//4.将key,value写出去
context.write(key,outValue);
}
}
driver
在本地运行的代码
就是右键运行
package com.lxy.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/13
* Time: 6:25
* 在本地运行
*/
public class WCDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
//2.给Job设置参数 -- 包含mapper和reducer类
//2.1关联本Driver程序的jar---本地运行的不需要设置 在集群上运行必须设置
job.setJarByClass(WCDriver.class);
//2.2设置Mapper和Reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//2.3设置Mapper输出的key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//2.4设置最终输出的key,value的类型-在这是Reducer输出的key value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.5设置输入和输出路径
//设置输入路径--数据所在的路径
FileInputFormat.setInputPaths(job,new Path("D:\\io\\input"));
//设置输出路径-运算的结果所放的路径-该路径一定不能存在否则报错
FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output"));
//3.提交Job
/*
boolean waitForCompletion(boolean verbose)
verbose : 是否打印执行的进度
返回值 : 如果Job执行成功返回true否则返回false
*/
boolean b = job.waitForCompletion(true);
System.out.println("b========" + b);
}
}
在集群运行的代码
在集群上运行Job
1.修改代码 - 输入路径和输出路径从main方法读取
2.打jar包
3.将jar包放到一个有权限的目录中(我放到了家目录)
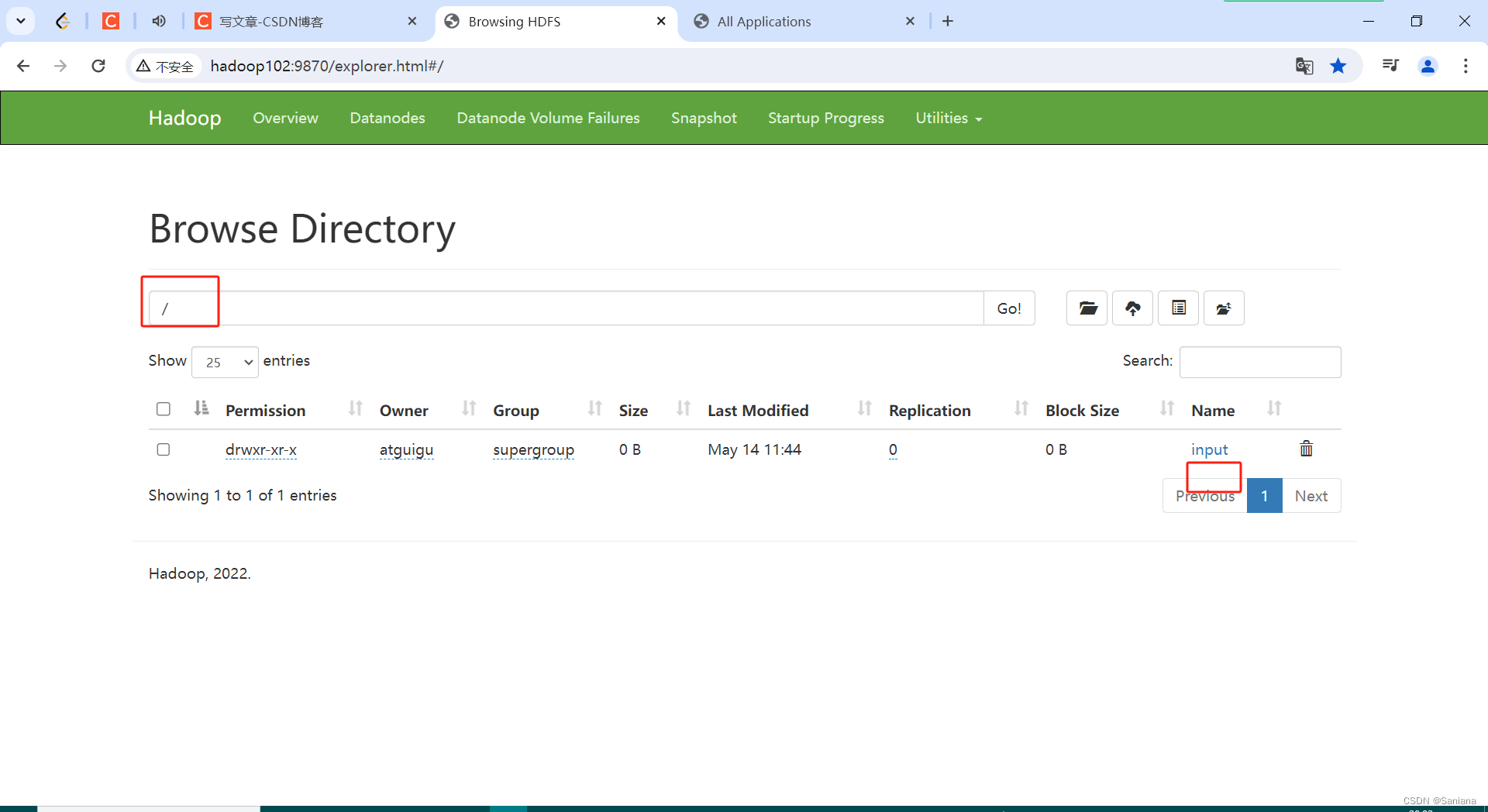
4.在HDFS上准备数据
5.运行jar包 : hadoop jar xxx.jar 全类名 参数1 参数2
6.查看hadoop103:8088 是否有Job提交
7.查看hadoop102:9870 查看结果
package com.lxy.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 7:45
* 在HDFS上提交运行
*/
public class WCDemo3 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//创建Job实例
Job job = Job.getInstance(new Configuration());
//2.给Job设置参数 -- 包含mapper和reducer类
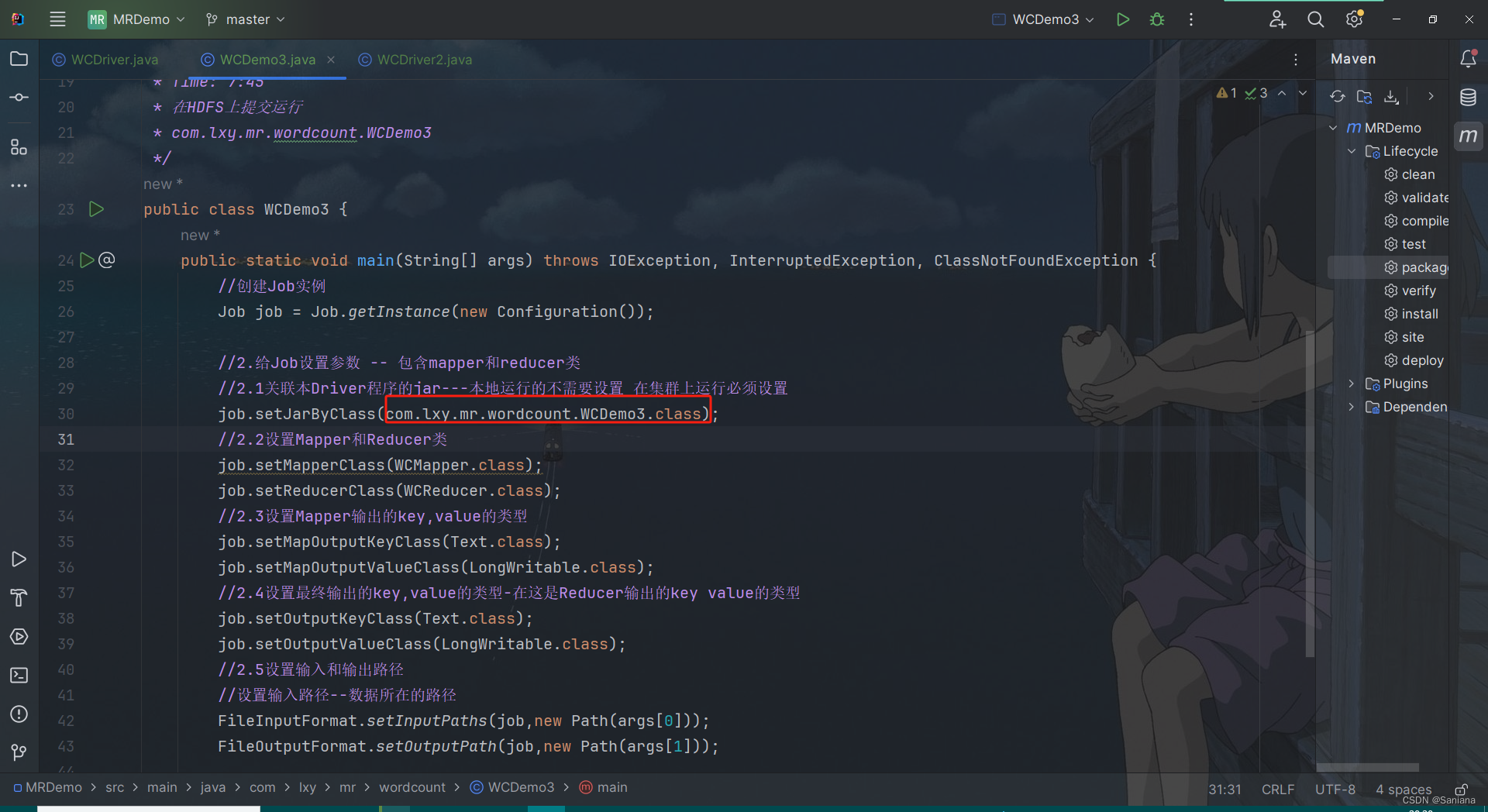
//2.1关联本Driver程序的jar---本地运行的不需要设置 在集群上运行必须设置
job.setJarByClass(WCDemo3.class);
//2.2设置Mapper和Reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//2.3设置Mapper输出的key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//2.4设置最终输出的key,value的类型-在这是Reducer输出的key value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.5设置输入和输出路径
//设置输入路径--数据所在的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.out.println("b = " + job.waitForCompletion(true));
}
}
在集群运行要在VMVare WorkStation或XShell敲命令!!!
- 先打jar包
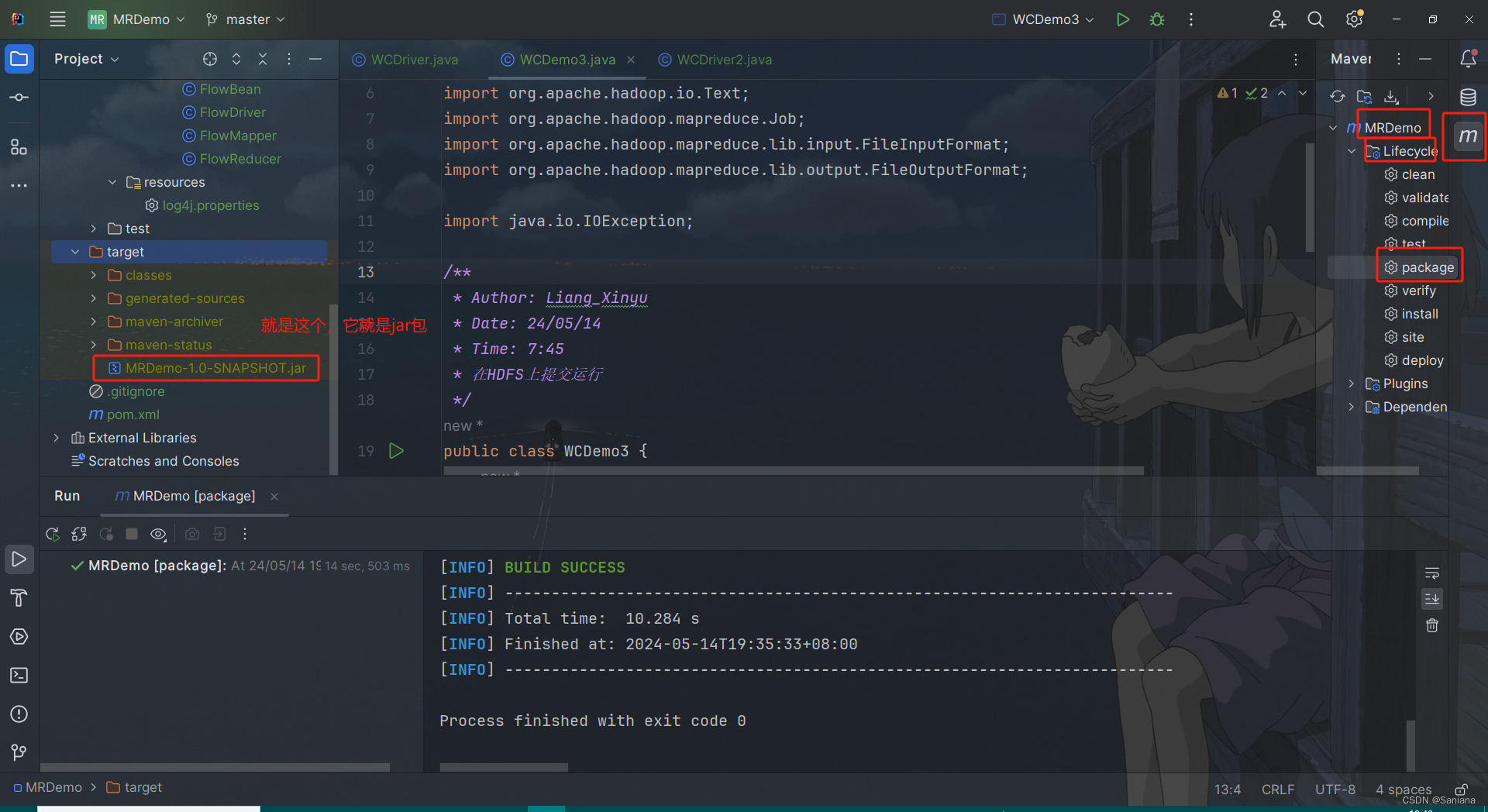
- 再把jar包拖集群里
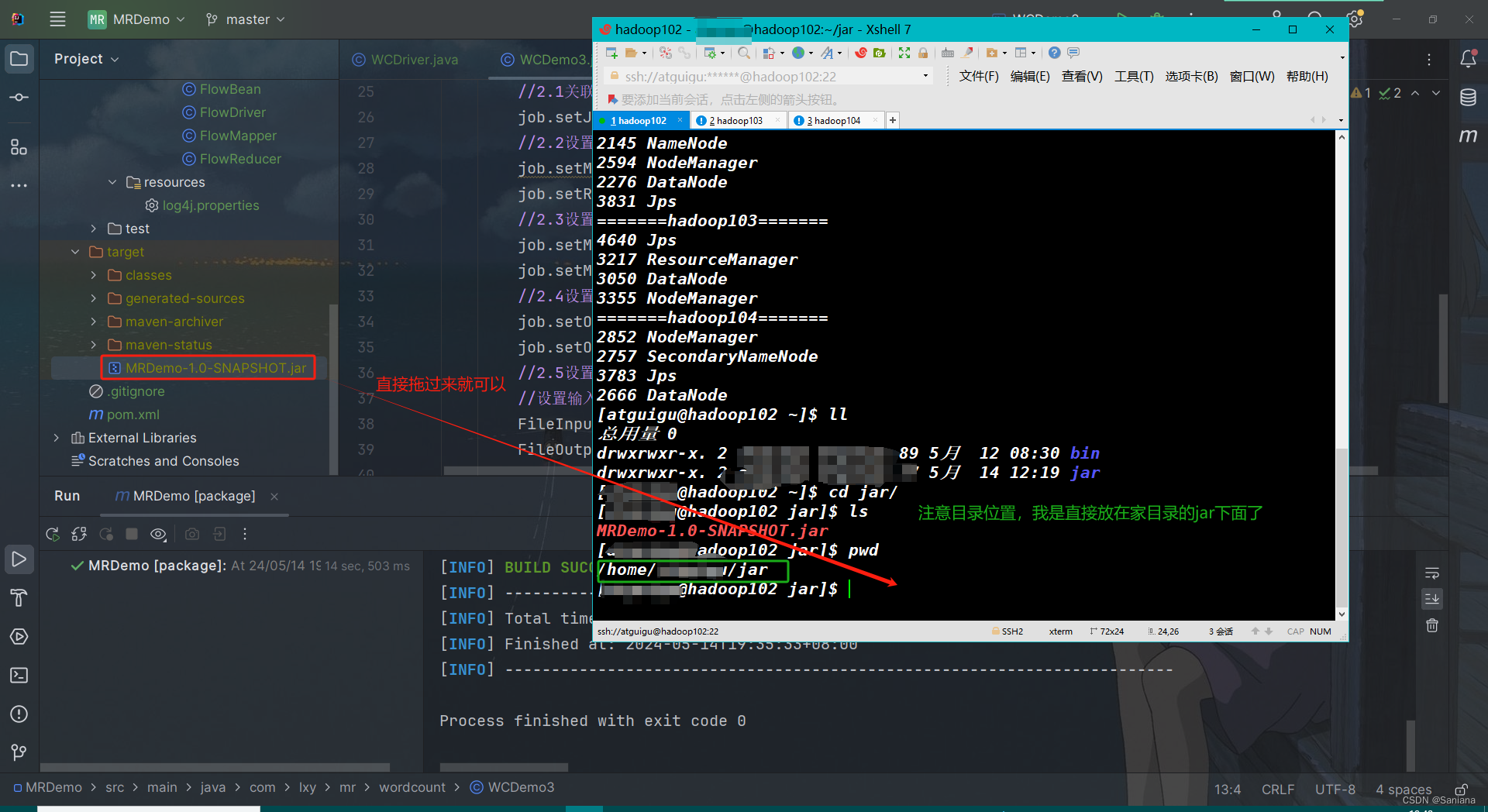
- 然后敲命令
hadoop jar xxx.jar 全类名 参数1 参数2
这是我的:hadoop jar MRDemo-1.0-SNAPSHOT.jar com.lxy.mr.wordcount.WCDemo3 /input /output
全类名这样获取:
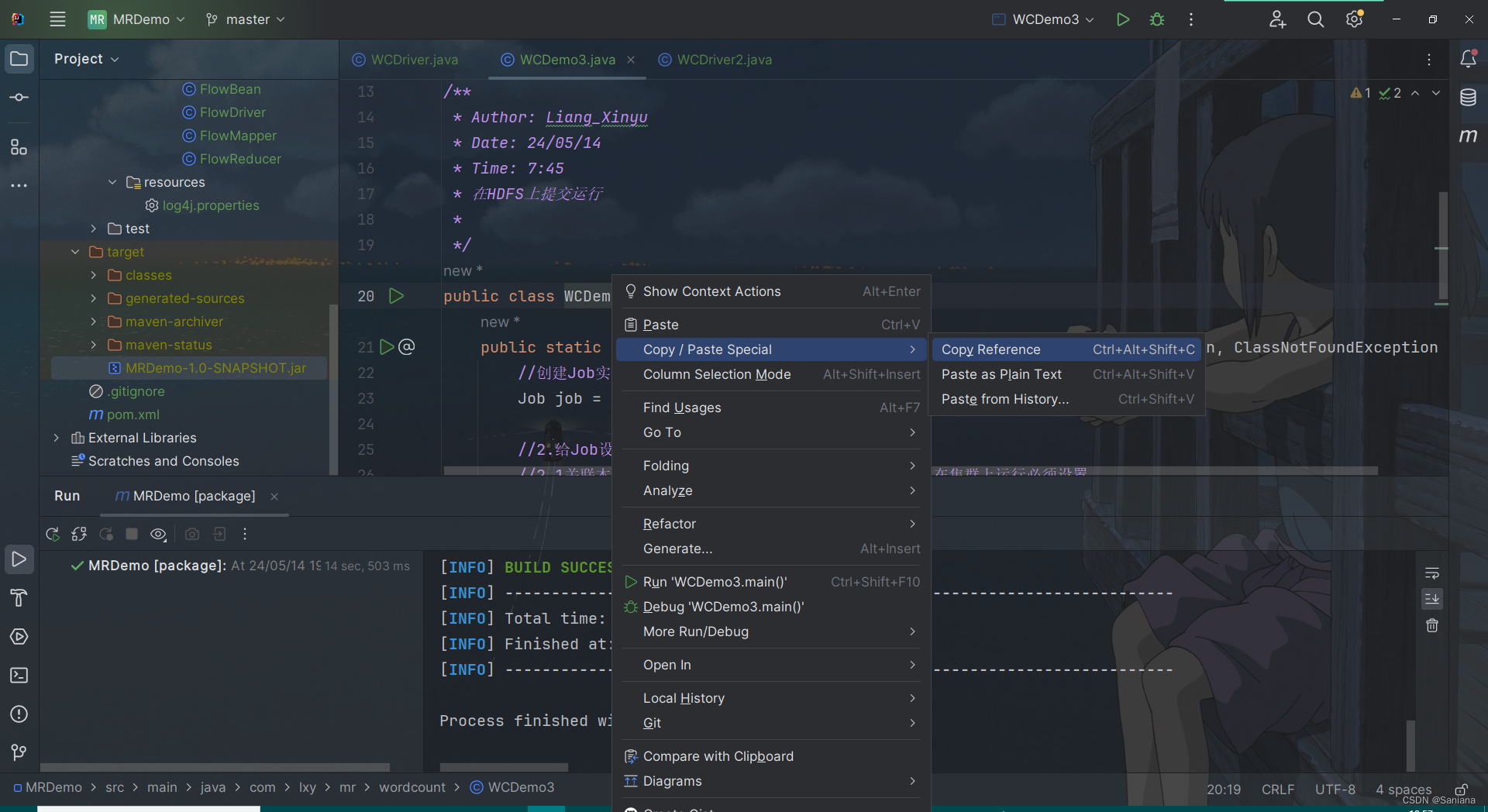
我们在代码里设置的参数1和参数2分别是
集群上的输入路径和输出路径
这是输入路径
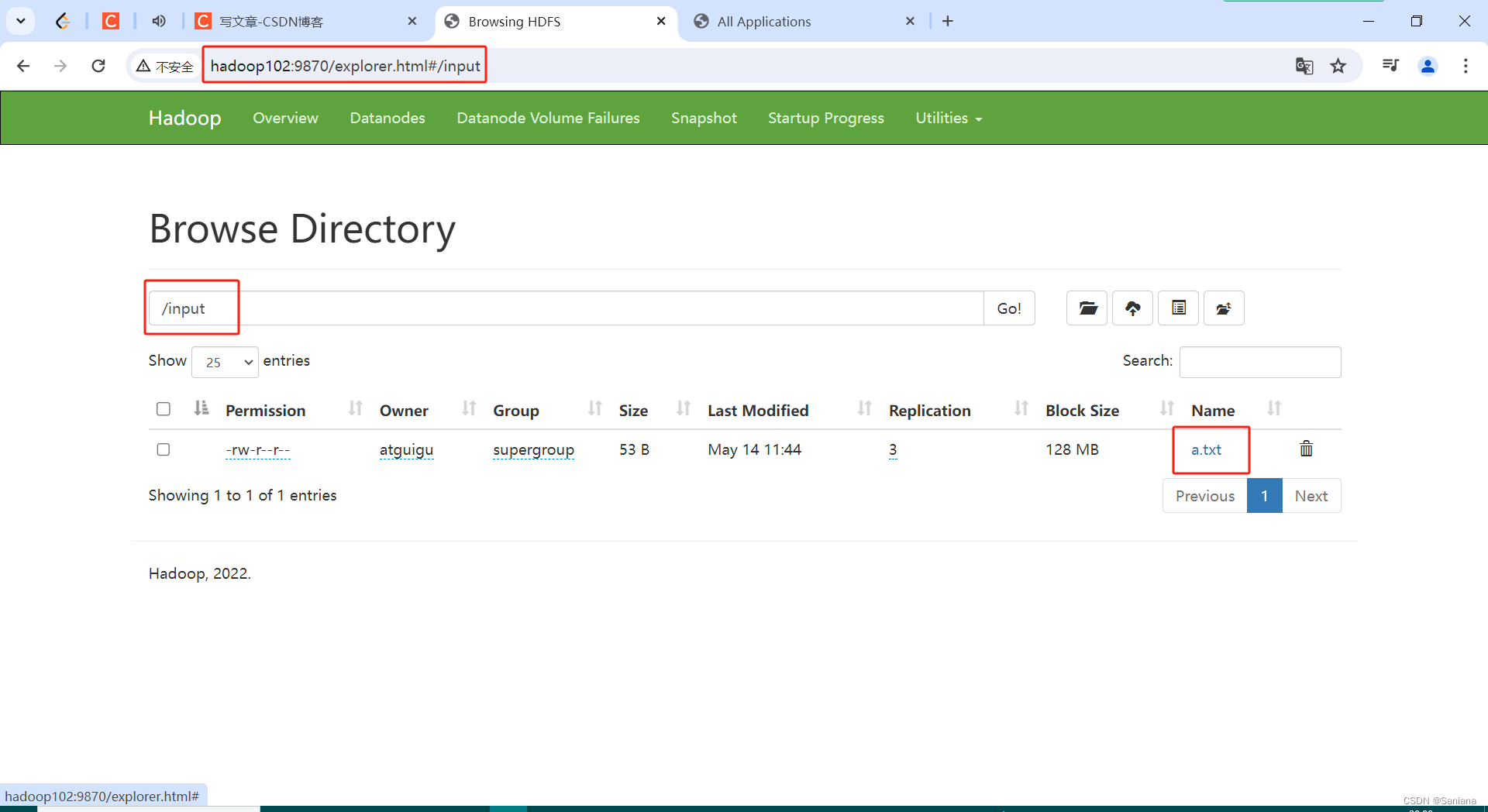
输出路径一定不要存在,否则会报错,空着就好
我在执行中遇到了ClassNotFoundException
就把代码中的类名换成全类名解决了,一般是不需要的
用Windows向集群提交
从本地向集群提交 – 知道即可
1.配置参数
//设置在集群运行的相关参数-设置HDFS,NAMENODE的地址
conf.set(“fs.defaultFS”, “hdfs://hadoop102:8020”);
//指定MR运行在Yarn上
conf.set(“mapreduce.framework.name”,“yarn”);
//指定MR可以在远程集群运行
conf.set(“mapreduce.app-submission.cross-platform”,“true”);
//指定yarn resourcemanager的位置
conf.set(“yarn.resourcemanager.hostname”,“hadoop103”);
2.输入路径和输出路径从main方法读取
3.打jar包
4. //注释掉下面代码
//job.setJarByClass(WCDriver3.class);
//添加如下代码 - 设置jar包路径
job.setJar(“jar包路径”);
5.
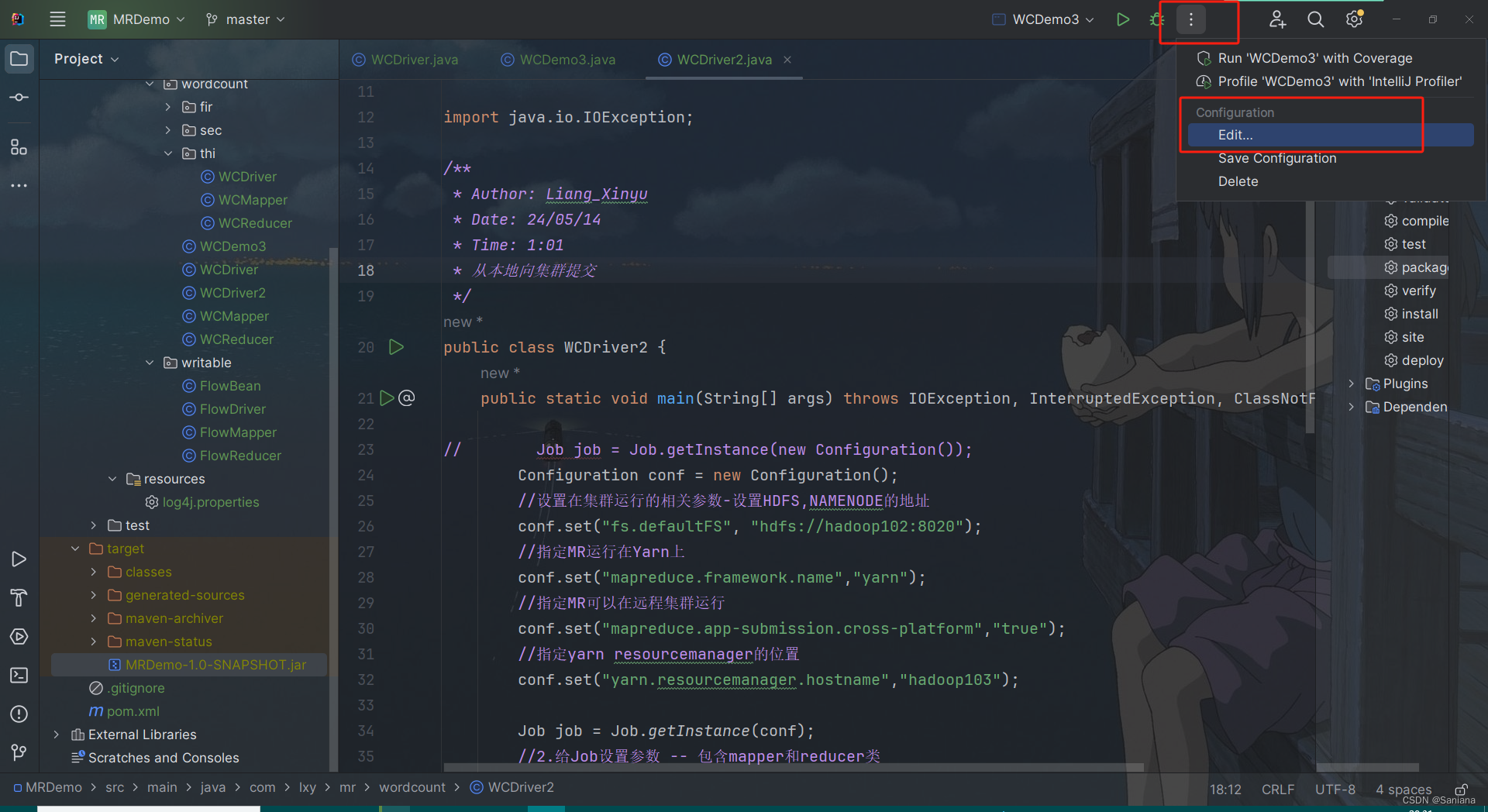
在右上角点击EditConfigurations -> 左边选类名(没有先运行一次该类)
右面选modify Options -> add vm options
-> 在 vm options的输入框中添加: -DHADOOP_USER_NAME=lxy
在 program Arguments添加 :hdfs://hadoop102:8020/input hdfs://hadoop102:8020/output33
package com.lxy.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 1:01
* 从本地向集群提交
*/
public class WCDriver2 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// Job job = Job.getInstance(new Configuration());
Configuration conf = new Configuration();
//设置在集群运行的相关参数-设置HDFS,NAMENODE的地址
conf.set("fs.defaultFS", "hdfs://hadoop102:8020");
//指定MR运行在Yarn上
conf.set("mapreduce.framework.name","yarn");
//指定MR可以在远程集群运行
conf.set("mapreduce.app-submission.cross-platform","true");
//指定yarn resourcemanager的位置
conf.set("yarn.resourcemanager.hostname","hadoop103");
Job job = Job.getInstance(conf);
//2.给Job设置参数 -- 包含mapper和reducer类
//2.1关联本Driver程序的jar---本地运行的不需要设置 在集群上运行必须设置
// job.setJarByClass(WCDriver2.class);
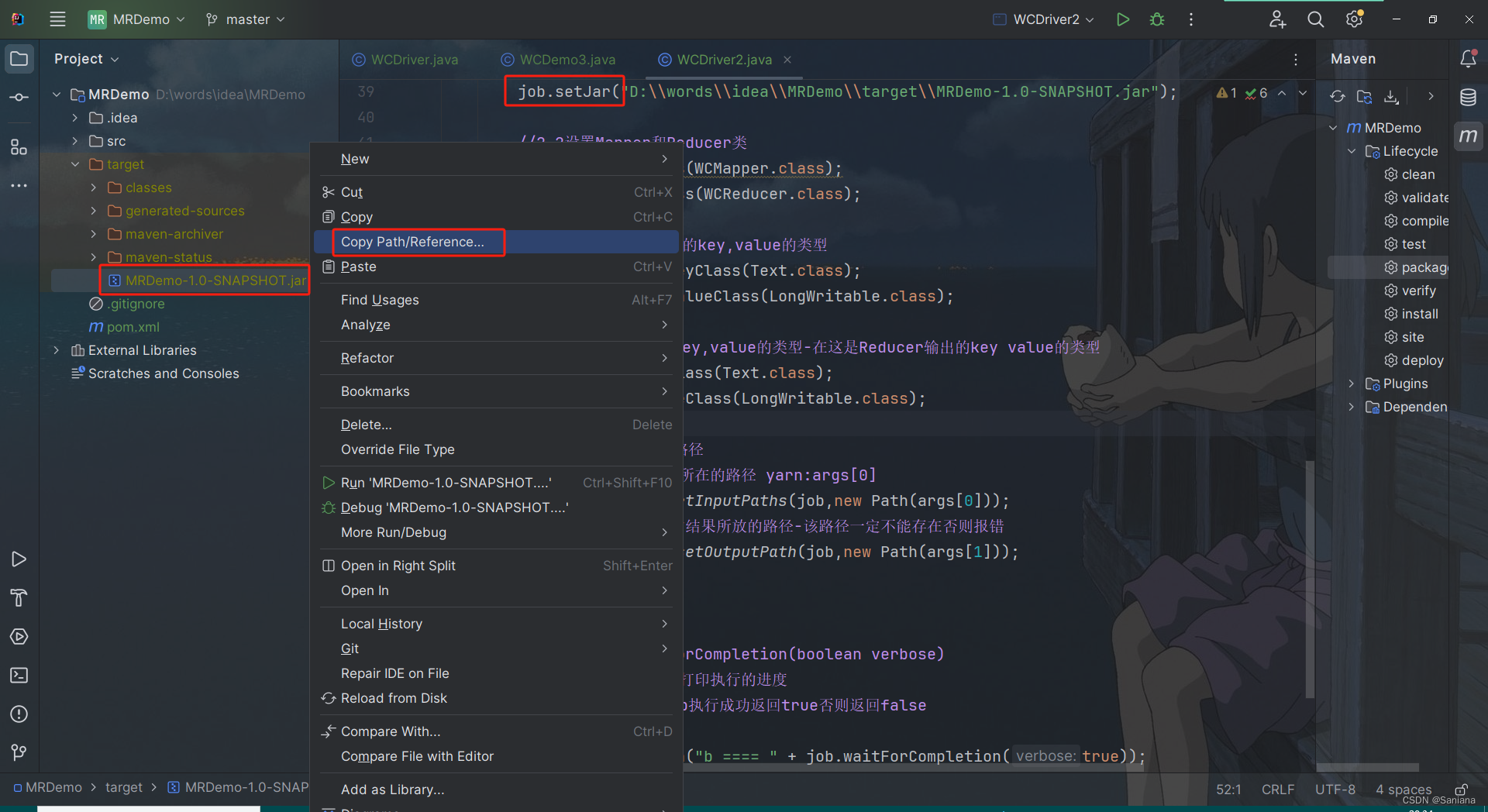
job.setJar("D:\\words\\idea\\MRDemo\\target\\MRDemo-1.0-SNAPSHOT.jar");
//2.2设置Mapper和Reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//2.3设置Mapper输出的key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//2.4设置最终输出的key,value的类型-在这是Reducer输出的key value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.5设置输入和输出路径
//设置输入路径--数据所在的路径 yarn:args[0]
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置输出路径-运算的结果所放的路径-该路径一定不能存在否则报错
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//3.提交Job
/*
boolean waitForCompletion(boolean verbose)
verbose : 是否打印执行的进度
返回值 : 如果Job执行成功返回true否则返回false
*/
System.out.println("b ==== " + job.waitForCompletion(true));
}
}
向集群提交的配置在这里修改:
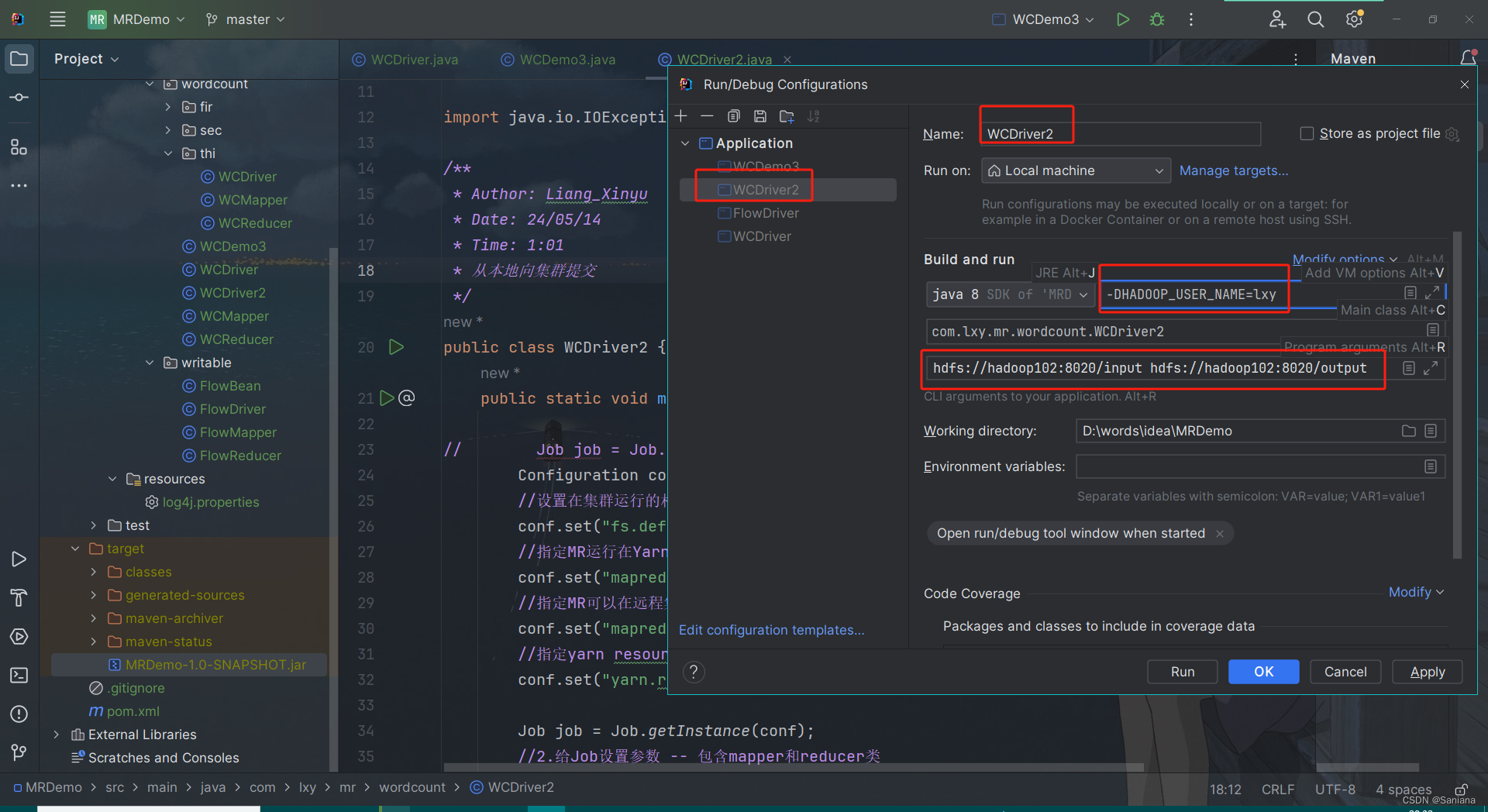
我们之前的代码都是setJarByClass,现在是setJar,要写绝对路径,绝对路径从这里获取:
流量统计
数据准备
phone_data.txt
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200
6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
FlowBean
让当前类的对象可以在Hadoop中序列化和反序列化
FlowBean这个类是一个JavaBean
Writable序列化步骤
1.自定义一个类(作为MR中的key或value)并实现Writable
2.实现write和readFields方法
3.在write方法中写序列化时要做的事情
在readFields方法中写反序列化时要做的事情
4.注意:反序列化时的顺序要和序列化时的顺序保持一致
package com.lxy.mr.exer.writable.mr01;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 7:26
*/
public class FLowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public FLowBean() {
}
public FLowBean(long upFlow, long downFlow, long sumFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
}
public FLowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = this.getUpFlow() + this.getDownFlow();
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(downFlow);
dataOutput.writeLong(upFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
downFlow = dataInput.readLong();
upFlow = dataInput.readLong();
sumFlow = dataInput.readLong();
}
@Override
public String toString() {
return "FLowBean{" +
"upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
}
Mapper
package com.lxy.mr.exer.writable.mr01;
import com.lxy.mr.writable.mr01.FlowBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 20:50
*/
public class FlowMapper extends Mapper<LongWritable, Text,Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
//1.切割数据
String[] info = value.toString().split("\t");
//2.封装key和value ( key(13736230513) value(2481,24681,2481+24681) )
Text outKey = new Text();
outKey.set(info[1]);
FlowBean outValue = new FlowBean();
outValue.setUpFlow(Long.parseLong(info[info.length - 3]));
outValue.setDownFlow(Long.parseLong(info[info.length - 2]));
outValue.setSumFlow(outValue.getUpFlow() + outValue.getDownFlow());
//3.将key,value写出去
context.write(outKey,outValue);
}
}
Reducer
该类是在reduce阶段被ReduceTask调用 用来实现ReduceTask要实现的业务逻辑代码
Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
第一组:
KEYIN :读取的key的类型(map写出的key的类型)-在这是手机号的类型
VALUEIN :读取的value的类型(map写出的value的类型)-在这是FlowBean的类型
第二组:
KEYOUT : 写出的key的类型-在这是手机号的类型
VALUEOUT :写出的value的类型 - 在这是FlowBean的类型
package com.lxy.mr.exer.writable.mr01;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 20:50
*/
public class FlowReducer extends Reducer<Text, FLowBean,Text,FLowBean> {
/**
* 在reduce方法中用来实现需要在ReduceTask中实现的功能
* reduce方法在被循环调用每调用一次传入一组数据
* @param key 读取的key - 单词
* @param values 放了所有的value - 单词的数量
* @param context 上下文在这用来将key,value写出去
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<FLowBean> values, Reducer<Text, FLowBean, Text, FLowBean>.Context context) throws IOException, InterruptedException {
long sumDownFlow = 0;
long sumUpFlow = 0;
for (FLowBean value : values) {
sumUpFlow += value.getUpFlow();
sumDownFlow += value.getDownFlow();
}
FLowBean outValue = new FLowBean(sumUpFlow, sumDownFlow);
context.write(key,outValue);
}
}
Driver
右键运行即可
package com.lxy.mr.exer.writable.mr01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author: Liang_Xinyu
* Date: 24/05/14
* Time: 7:27
*/
public class FlowDriver{
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.创建Job实例
Job job = Job.getInstance(new Configuration());
//2.给Job设置参数 -- 包含mapper和reducer类
//2.1关联本Driver程序的jar---本地运行的不需要设置 在集群上运行必须设置
job.setJarByClass(FlowDriver.class);
//2.2设置Mapper和Reducer类
job.setMapperClass(FlowMapper.class);
job.setReducerClass(Reducer.class);
//2.3设置Mapper输出的key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(FLowBean.class);
//2.4设置最终输出的key,value的类型-在这是Reducer输出的key value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FLowBean.class);
//2.5设置输入和输出路径
//设置输入路径--数据所在的路径
FileInputFormat.setInputPaths(job,new Path("D:\\io\\input2"));
//设置输出路径-运算的结果所放的路径-该路径一定不能存在否则报错
FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output2"));
//3.提交Job
job.waitForCompletion(true);
}
}
结果
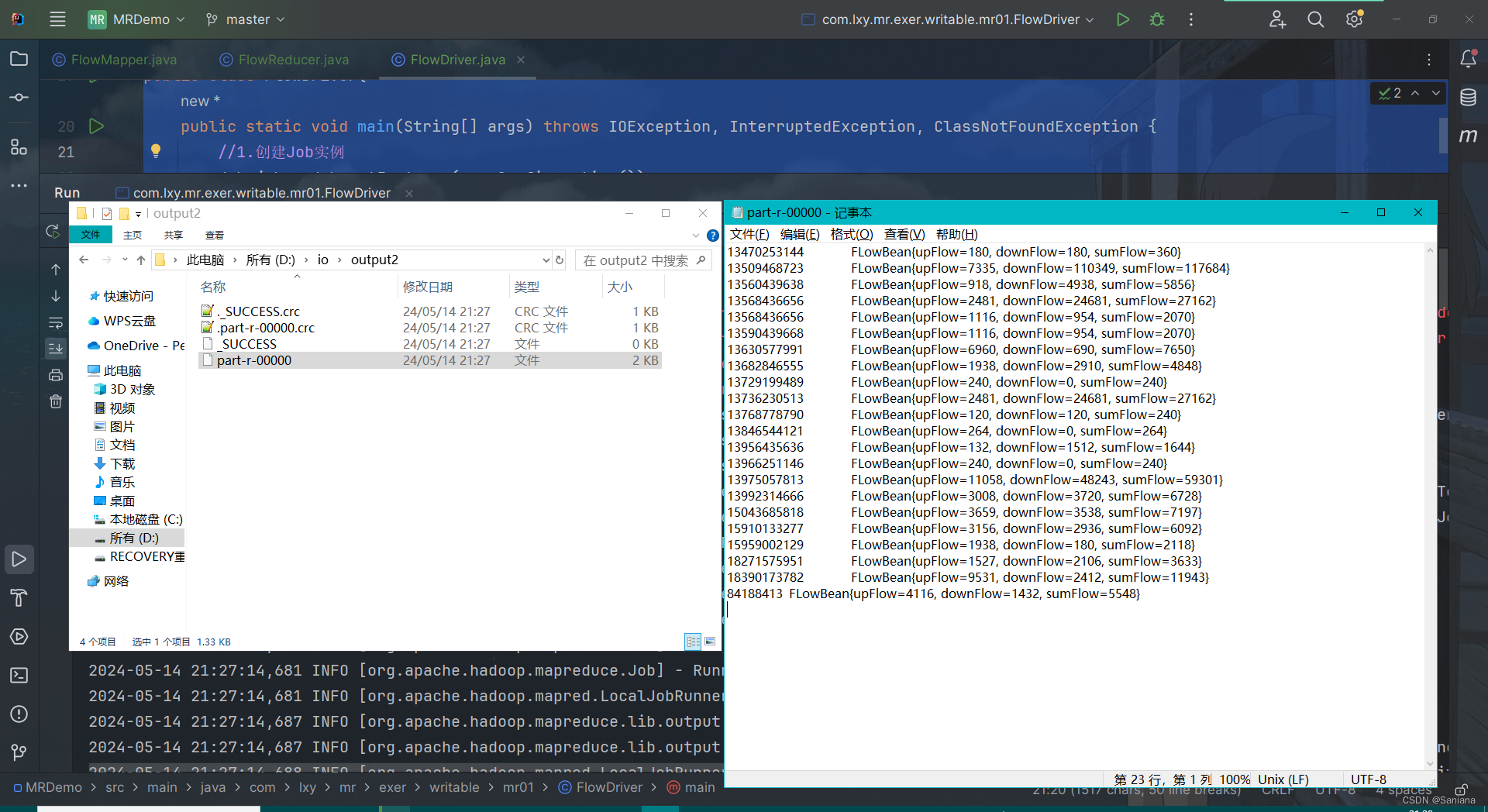















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









