







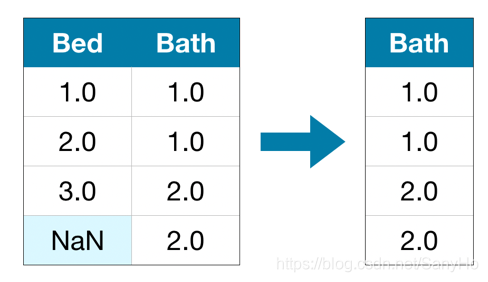
方法一: 移除法(Drop)
将含有残缺值的列直接丢弃。这种方法可能会导致大量有用的信息丢失。
import pandas as pd
# 读取数据
data = pd.read_csv("filename.csv")
# 提取出含有残缺值的列
cols_with_missing = [col for col in data.columns if data[col].isnull().any()]
# 移除含有残缺值的列
reduced_data = data.drop(cols_with_missing, axis=1)
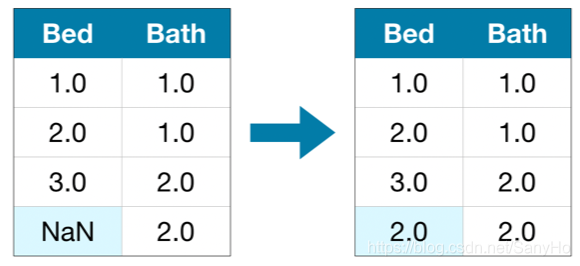
方法二: 插值法(Imputation)
用新的数据填充残缺值的位置,一般可用均值(mean value)填充。虽然填充值并不一定精确,但是它不用丢弃整一列的数据。
from sklearn.impute import SimpleImputer
import pandas as pd
# 读取数据
data = pd.read_csv("filename.csv")
# Imputation 用该列均值填充残缺值
my_imputer = SimpleImputer()
imputed_data = pd.DataFrame(my_imputer.fit_transform(data))
# Imputation 通常会移除列名,因此要将它们取回
imputed_data.columns = data.columns
处理类别变量中的残缺值
from sklearn.base import BaseEstimator, TransformerMixin
class MostFrequentImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
# 选取出现次数最多的同类型类别变量
self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X], index=X.columns)
return self
def transform(self, X, y=None):
return X.fillna(self.most_frequent_)
cat_imputer = MostFrequenctImputer()
imputed_data = pd.DataFrame(cat_imputer.fit_transform(data))
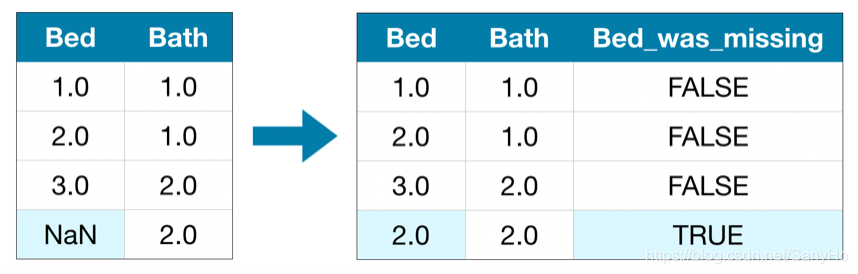
方法三: 插值法的延伸
通常情况下,插值法(imputation)可以很好的解决问题,但是插入的均值要么高于或低于实际值(actual value),因此导致计算的结果与现实情况有所出入。因此,我们除了查入均值外,对于每个含有残缺值的列,我们都额外添加一列来表示该列中残缺值的位置。在某些应用中,这个方法能优化结果,当然有时候也不起作用。
from sklearn.impute import SimpleImputer
import pandas as pd
# 读取数据
data = pd.read_csv('filename.csv')
# 复制该数据集,以免接下来的操作(imputing)更改了原来的数据
data_plus = data.copy()
# 获取含有缺失值的列的列名
cols_with_missing = [col for col in data.columns if data[col].isnull().any()]
# 增添新的列来表明缺失值的位置
for col in cols_with_missing:
data_plus[col + '_was_missing'] = data_plus[col].isnull()
# Imputation 在残缺值的位置插入该列的平均值
my_imputer = SimpleImputer()
imputed_data_plus = pd.DataFrame(my_imputer.fit_transform(data_plus))
# Imputation 通常会移除列名,因此要将它们取回
imputed_data_plus.columns = data_plus.columns
# 统计数据集中每一列的缺失值数目
missing_val_count_by_column = (data.isnull().sum())














 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









