






目录
摘要:
本文档介绍了基于Centos7的Hadoop集群的搭建过程,在借鉴别人文章的基础上和自己的试验,扩展总结了Hadoop的基础知识和项目的搭建流程。部署了两个master节点和三个salve节点的Hadoop高可用集群,在master和slave主机上配置了HDFS(hadoop分布式文件系统)、HBase(集群数据库)以及Zookeeper(集群维护服务),同时详细给出部署过程和测试结果。并对部署过程中遇到的bug进行记录。
1 关于集群
1.1 Hadoop是什么
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
1.2 Hadoop能做什么
- 大数据存储:分布式存储
- 日志处理:擅长日志分析
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 机器学习:必如Apache Mahout项目
- 搜素引擎:Hadoop + Lucene实现
- 数据挖掘:目前比较流行的广告推荐,个性化广告推荐
- Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
1.3 怎么使用Hadoop
1. 上传文件到Hadoop集群,实现文件存储:
Hadoop集群搭建好以后,可以通过web页面查看集群的情况,还可以通过Hadoop命令来上传文件到hdfs集群,通过Hadoop命令在hdfs集群上建立目录,通过Hadoop命令删除集群上的文件等等。
2. 编写map/reduce程序,完成计算任务:
通过集成开发工具(例如eclipse)导入Hadoop相关的jar包,编写map/reduce程序,将程序打成jar包扔在集群上执行,运行后出计算结果。
1.4 分布式大数据介绍
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS ,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop,为用户 提供了系统层面细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点,允许用户将Hadoop部署在低廉 的硬件上,轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
HBase是一个开源的非关系(NoSQL)的可伸缩性分布式数据库。它是面向列的,并适合于存储超大型松散数据。HBase适合于实时、随机对Big数据进行读写操作的业务环境。
这些技术可以用来:存储海量数据、实时分析和计算、数据挖掘,国外使用这些技术的有雅虎、亚马逊和facebook等,国内使用该技术的有京东、淘宝、阿里、华为和奇虎360等。
1.5 Zookeeper原理说明
在典型的HA集群中,两台独立的机器被配置为NameNodes。在任何时间点上,正好有一个NameNodes处于活动状态,另一个处于备用状态。活动NameNode负责集群中的所有客户机操作,而备用节点只是充当从节点,维护足够的状态,以便在必要时提供快速故障转移。
为了使备用节点保持其状态与活动节点同步,两个节点都与一组名为“JournalNodes”(JNs)的独立守护进程进行通信。当活动节点执行任何名称空间修改时,它会将修改的记录持久地记录到这些jn中的大多数。备用节点能够从JNs中读取编辑,并不断地监视它们是否对编辑日志进行更改。当备用节点看到编辑时,它将它们应用于自己的命名空间。在发生故障转移的情况下,备用服务器将确保在将自身提升到活动状态之前,它已从journalnodes读取了所有编辑。这可以确保命名空间状态在发生故障转移之前完全同步。
为了提供快速的故障转移,备用节点还必须具有关于集群中块位置的最新信息。为了实现这一点,datanode配置了两个NameNodes的位置,并向两者发送块位置信息和心跳信号。
对于HA集群的正确操作,一次只有一个namenode处于活动状态是至关重要的。否则,名称空间状态将在这两者之间迅速分化,有数据丢失或其他不正确结果的风险。为了确保这个属性并防止所谓的“分裂大脑场景”,JournalNodes每次只允许一个NameNode成为一个writer。在故障转移期间,要变为活动状态的NameNode将简单地接管写入JournalNodes的角色,这将有效地阻止另一个NameNode继续处于活动状态,从而允许新的active安全地继续进行故障转移。
2 项目准备
2.1 Linux Centos 环境准备
1. hbase和hadoop版本匹配表:
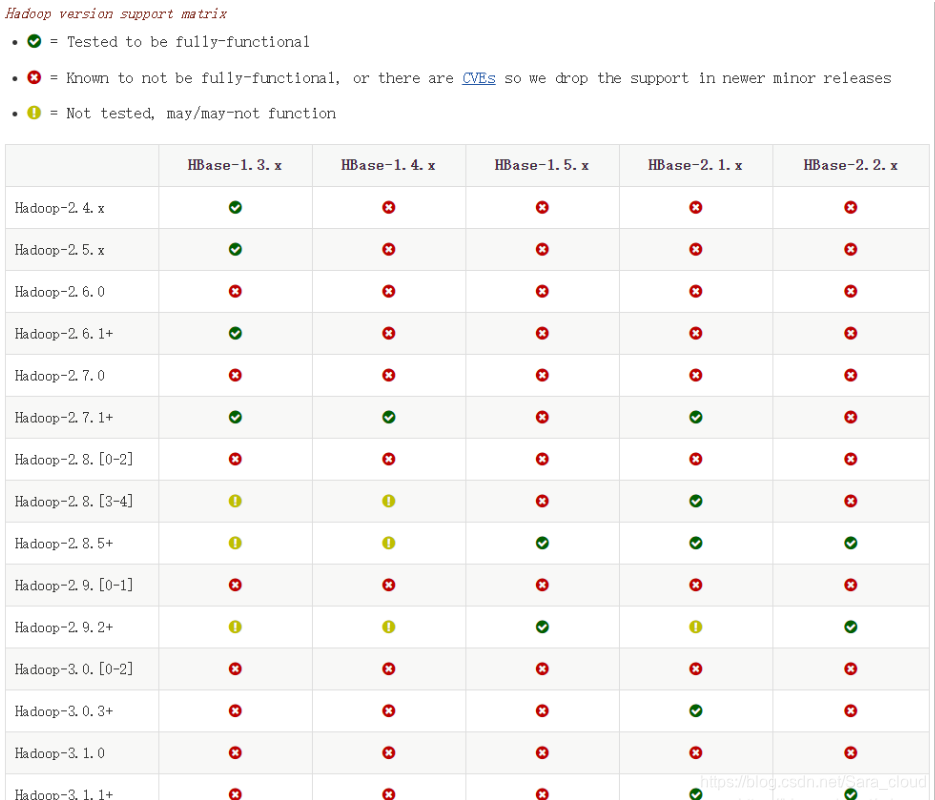
2. 虚拟机:VirtualBox
3. 系统:Centos 7
4. 保证每个节点时同步(否则Hbase集群会报错)
5. JDK:jdk-8u181-linux-x64.tar.gz
6. 安装包:apache-zookeeper-3.5.8-bin.tar.gz
hadoop-3.2.1.tar.gz
hbase-2.2.5-bin.tar.gz
7.各主机节点部署情况:
Zookeeper进程:
Qp:QuorumPeerMain
Hdfs进程:
Nn:Namenode
Dn:DataNode
Jn:JournalNoode
Df:DFSZK Failover Controller
Yarn进程:
Rm:Resource Manager
Nm:NodeManager
Hbase进程:
Hm:Hmaster
Hr:HRegionServer
| IP地址(NAT/桥接) | 主机名 | 大小 | ZK | Hdfs | Yarn | Hbase |
| 192.168.0.101 10.0.2.21 | hmaster1 |
20G | Qp | Nn、Df | Rm | Hm |
| 192.168.0.102 10.0.2.22 | hmaster2 | 20G | Qp | Nn、Df | Hm | |
| 192.168.0.103 10.0.2.23 | hslave1 |
20G | Qp | Dn、Jn | Nm | Hr |
| 192.168.0.104 10.0.2.24 | hslave2 | 20G | Dn、Jn | Rm、Nm | Hr | |
| 192.168.0.105 10.0.2.25 | hslave3 | 20G | Dn、Jn | Nm | Hr |
8. 将所有相关的安装包上传到主节点某个目录(例如:/package)

上述软件均是开源,大家可以网上自行下载
2.2 配置集群间免密登录(ssh服务)
hadoop集群是通过主节点的rpc调用来对整个集群进行统一的操作管理,如果不配置免密登录,则在每次启动集群时都需要输入每个节点的主机密码,免密登录可以很好的解决这个问题。
1. 分别在五台主机上生成ssh链接的私钥和公钥(一直回车。知道结束),再将本机的公钥拷贝到其余四台主机和本机。
# 生成秘钥:会有提示,直接回车即可
ssh-keygen
# 分别发送公钥给所有主机
ssh-copy-id -i 节点IP
# 测试是否成功免密登录
ssh 节点IP 注意:如果执行ssh-keygen报错,说明未安装oopenssh服务,首先安装服务再进行免密配置。
yum install openssh-clients -y
yum install openssh-server -y2. 五台主机关闭selinux
# 临时selinux
setenforce 0
# 永久关闭,修改SELINUX,下一次启动生效
vim /etc/sysconfig/selinux
SELINUX=disabled3. 五台主机关闭防火墙
注意:这是测试环境,在实际项目环境中防火墙开放相对应的服务端口即可。
# 临时关闭防火墙
systemctl stop firewalld
# 永久关闭防火墙
systemctl disable firewalld
2.3 修改主机的hostname,便于区分和后续的配置
1. 操作系统为centos7,可使用自带的 hostnamectl 修改主机名
# 主节点
hostname hamster1 # 临时更改
hostnamectl set-hostname hmaster1 # 永久更改
# 备节点
hostanme hmaster2
hostnamectl set-hostname hmaster2
# 数据节点1
hostname hslave1
hostnamectl set-hostname hslave1
# 数据节点2
hostname hslave2
hostnamectl set-hostname hslave2
# 数据节点3
hostname hslave3
hostnamectl set-hostname hslave3
2. 修改host文件,在文件最后添加主机映射关系
vim /etc/hosts
192.168.0.101 hmaster1
192.168.0.102 hmaster2
192.168.0.103 hslave1
192.168.0.104 hslave2
192.168.0.105 hslave3在一台主机添加完成后,利用前方配置的ssh服务,使用命令 “ scp -r /etc/hosts 主机ip:/etc/ ” ,将hosts文件分别复制到其余主机。
3. 配置集群时间同步
ntpdate pool.ntp.org
# 若报错,没有ntpdate命令,则使用命令 “yum install ntpdate -y ” 安装即可2.4 集群安装java环境
由于hadoop框架的启动时依赖java环境的,所以需要安装jdk。
1. 把五台主机的原有的jdk卸载
rpm -qa | grep java
rpm -qa | grep jdk
rpm -e --nodeps `rpm -qa | grep jdk`
rpm -e --nodeps `rpm -qa | grep java`
# --nodes 依赖关系2. 配置jdk环境变量,在 /etc/profile 文件末尾将以下内容添加到末尾
tar xf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181/ /usr/local/jdk8
vim /etc/profile
# java enviornment
export JAVA_HOME=/usr/local/jdk8 # jdk的安装目录
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVE_HOME/lib/tools.jar
# 配置文件立即生效
source /etc/profile
# 测试java环境配置是否成功
java -version 
将jdk家目录和环境配置文件上传到其余4个节点:
[root@hmaster1 ~]# scp -r /usr/local/jdk8/ hmaster2:/usr/local/
[root@hmaster1 ~]# scp -r /usr/local/jdk8/ hslave1:/usr/local/
[root@hmaster1 ~]# scp -r /usr/local/jdk8/ hslave2:/usr/local/
[root@hmaster1 ~]# scp -r /usr/local/jdk8/ hslave3:/usr/local
[root@hmaster1 ~]# scp -r /etc/profile 192.168.0.102:/etc/
[root@hmaster1 ~]# scp -r /etc/profile 192.168.0.103:/etc/
[root@hmaster1 ~]# scp -r /etc/profile 192.168.0.104:/etc/
[root@hmaster1 ~]# scp -r /etc/profile 192.168.0.105:/etc/
3 安装zookeeper
- 在hmaster1安装配置好zookeeper后;
- 将zookeeper安装目录远程复制到hamster2和hslave1。
mkdir -p /home/hdfs
tar zxvf apache-zookeeper-3.5.8-bin.tar.gz
mv apache-zookeeper-3.5.8-bin /home/hdfs/zookeeper3.1 zookeeper配置
1. 进入zookeeper的 $home/conf 目录下,拷贝 zoo_sample.cfg 为 zoo.cfg
cd /home/hdfs/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
# 对zoo.cfg进行编辑
vim /home/hdfs/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hdfs/zookeeper/data
dataLogDir=/home/hdfs/zookeeper/log
clientPort=2181
autopurge.purgeInterval=1
server.1=hmaster1:2888:3888
server.2=hmaster2:2888:3888
server.3=hslave1:2888:3888
# tickTime 表示节点间通信超时的单位时长,单位是毫秒;
# initLimit 是指follower服务器初始化连接到leader服务器时可以忍受的超时时间,时长以initLimit*tickTime计算,这里是5*2000=10秒;
# dataDir 指定zookeeper的数据目录;
# dataLogDir 指定zookeeper的日志目录;
# autopurge.purgeInterval=1 表示开启日志和镜像文件自动清理功能;
# 2181 指的是对client提供服务的端口;
# server.1=hmaster1:2888:3888 中 “server.1” 表示节点编号;“hmaster1” 表示这台服务器的主机名,也可以直接指定为ip地址;“2888” 表示zookeeper服务间通信的端口;“3888” 表示zookeeper服务与其他服务通信的端口。2. 新建配置文件里数据目录和日志目录(服务启动后会自动创建,为以防万一,可以提前手动创建)
mkdir -p /home/hdfs/zookeeper/{data,log}3.2 同步安装和配置
[root@hmaster1 ~]# scp -r /home/hdfs/zookeeper/ hmaster2:/home/
[root@hmaster1 ~]# scp -r /home/hdfs/zookeeper/ hslave1:/home/3.3 配置zookeeper节点标识文件 myid
- 在dataDir目录下新建myid文件,输入一个数字;
- hamster1为1,hamster2为2,hslave1为3;
-
[root@hmaster1 ~]# echo "1" > /home/hadoop/zookeeper/data/myid - 也可以使用scp命令远程复制到其余2个节点后,修改myid文件中的数字。
zookeeper的工作特点:一个领导者(leader)、多个跟随者(follower)组成的集群,Leader负责投票的发起和决议、更新系统状态;Follower用于接收客户度请求并向客户端返回结果,在选举Leader过程中参与投票。集群中只要有半数以上节点存活,zookeeper集群就能正常服务;并且Leader并不是一成不变的,如果将已有的Leader主机停掉,其余主机又会重新选举出新的Leader。
4 Hadoop高可用集群安装
- 在hmaster1安装配置好hadoop后;
- 将zookeeper安装目录远程复制到其余4个节点。
4.1 解压安装Hadoop
tar -zxvf hadoop-3.2.1.tar.gz
mv hadoop-3.2.1 /home/hdfs/hadoop4.2 配置hadoop相关环境变量
vim /etc/profile
# hadoop environment
HADOOP_HOME=/home/hdfs/hadoop
PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_HOME PATH
# 配置文件生效
source /etc/profile
# 查看是否配置成功
hadoop version4.3 Hadoop高可用完全分布式
编辑配置hadoop的$home/etc/hadoop目录下的文件:core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml,yarn-site.xml,workers。
1. 修改hadoop-env.sh
找到下列代码取消注释,具有添加以本机jdk路径为准:
export JAVA_HOME=/usr/local/jdk8配置hadoop进程id文件路径,HADDOP_PID_DIR默认为/tmp,操作系统重启时可能会清除:
export HADOOP_PID_DIR=/home/hdfs/hadoop/pids手动创建文件:
mkdir -p /home/hdfs/hadoop/pids2. 编辑core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为masters -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 用于序列文件的缓冲区大小。此缓冲区的大小可能是硬件页大小(在Intel x86上为4096)的倍数,它决定在读写操作期间缓冲了多少数据. 默认为4096-->
<property>
<name>io.file.buffer.size</name>
<value>40960</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/hadoop/tmp/${user.name}</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hmaster1:2181,hmaster2:2181,hslave1:2181</value>
</property>
<!-- 解决:Active NameNode日志出现异常IPC‘s epoch [X] is less than the last promised epoch [X+1],出现短期的双Active -->
<property>
<name>ha.health-monitor.rpc-timeout.ms</name>
<value>180000</value>
</property>
</configuration>3. 编辑hdfs-site.xml
dfs.namenode.rpc-address.mycluster.hmaster1
hmaster1:9000
默认为端口为:8020,如果此处配置为8020,则客户端访问可以不加端口号,即客户端调用时不加端口号,如:String uri=“hdfs://192.168.0.101/profile”;否则客户端访问要加端口号,如:String uri=“hdfs://192.168.0.101:9000/profile”。
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,逻辑名分别设置为hmaster1,hmaster2,也可设置为nn1,nn2,后面的配置要统一引用该逻辑名 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>hmaster1,hmaster2</value>
</property>
<!-- hmaster1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.hmaster1</name>
<value>hmaster1:9000</value>
</property>
<!-- hmaster1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.hmaster1</name>
<value>hmaster1:50070</value>
</property>
<!-- hmaster1的servicerpc通信地址 -->
<property>
<name>dfs.namenode.servicerpc-address.mycluster.hmaster1</name>
<value>hmaster1:53310</value>
</property>
<!-- hmaster2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.hmaster2</name>
<value>hmaster2:9000</value>
</property>
<!-- hmaster2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.hmaster2</name>
<value>hmaster2:50070</value>
</property>
<!--hmaster2的servicerpc通信地址 -->
<property>
<name>dfs.namenode.servicerpc-address.mycluster.hmaster2</name>
<value>hmaster2:53310</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hdfs/hadoop/data/mycluster</value>
<final>true</final>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置,必须是/home/hdfs/hadoop/sbin/hadoop-daemons.sh start journalnode启动的节点 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hslave1:8485;hslave2:8485;hslave3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hdfs/hadoop/data/tmp/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_dsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 指定DataNode数据的存放位置,建议一台机器挂多个盘,一方面增大容量,另一方面减少磁盘单点故障及磁盘读写能力 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hdfs/hadoop/data/dn</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.checkpoint.dir.mycluster </name>
<value>/home/hdfs/hadoop/data/dfs/namesecondary</value>
<final>true</final>
</property>
<!--每个DataNode上需预留的空间,给非hdfs使用,默认为0 -->
<property>
<name> dfs.datanode.du.reserved </name>
<value>102400</value>
<final>true</final>
</property>
<!--限制hdfs负载均衡时占用的最大带宽(以每秒字节数为单位). -->
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>10485760000</value>
</property>
</configuration>4. 编辑mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Expert: 将此设置为true,任务跟踪程序将在任务完成时发送带外检测信号,以获得更好的延迟 -->
<property>
<name>mapreduce.tasktracker.outofband.heartbeat</name>
<value>true</value>
</property>
</configuration>5. 编辑yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_HA_ID</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址。因为他们都要占用大量资源,可以把namenode和resourcemanager分开到不同的服务器上 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hmaster1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hslave2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hmaster1:2181,hmaster2:2181,hslave1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/home/hdfs/hadoop/etc/hadoop,
/home/hdfs/hadoop/share/hadoop/common/lib/*,
/home/hdfs/hadoop/share/hadoop/common/*,
/home/hdfs/hadoop/share/hadoop/hdfs,
/home/hdfs/hadoop/share/hadoop/hdfs/lib/*,
/home/hdfs/hadoop/share/hadoop/hdfs/*,
/home/hdfs/hadoop/share/hadoop/mapreduce/lib/*,
/home/hdfs/hadoop/share/hadoop/mapreduce/*,
/home/hdfs/hadoop/share/hadoop/yarn,
/home/hdfs/hadoop/share/hadoop/yarn/lib/*,
/home/hdfs/hadoop/share/hadoop/yarn/*
</value>
</property>
</configuration>6. 编辑workers,将原文件中的localhost修改为下列内容:
hslave1
hslave2
hslave3注意:如果要把主节点和备用节点同时作为数据节点使用的话,加上hmaster1和hmaster2即可。
7. 集群启动前配置操作用户:
进入/home/hdfs/hadoop/sbin/目录,在 start-dfs.sh 和 stop-dfs.sh 文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root在 start-yarn.sh 和 stop-yarn.sh 文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4.4 同步安装和配置
将hadoop的$home目录和/etc/profile发送给集群其余4个节点:
scp -r /home/hdfs/hadoop/ hmaster2:/home/hdfs/
scp -r /home/hdfs/hadoop/ hslave1:/home/hdfs/
scp -r /home/hdfs/hadoop/ hslave2:/home/hdfs/
scp -r /home/hdfs/hadoop/ hslave3:/home/hdfs/
scp -r /etc/profile hmaster2:/etc/
scp -r /etc/profile hslave1:/etc/
scp -r /etc/profile hslave2:/etc/
scp -r /etc/profile hslave3:/etc/
# 注意将环境配置文件复制过去之后,要使配置文件生效:
source /etc/profile
4.5 启动hadoop(初次)
注意:第一次启动严格按照下面的步骤顺序
1. 启动zookeeper集群:hmaster1、hmaster2、hslave1
/home/hdfs/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hdfs/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED查看zookeeper集群节点的启动状态:
[root@hmaser1 ~]# /home/hdfs/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hdfs/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@hmaser2 ~]# /home/hdfs/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hdfs/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
[root@hslave1 ~]# /home/hdfs/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hdfs/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
# jps
6561 Jps
6362 QuorumPeerMain //zookeeper启动的进程
2. 启动journalnode
namenode或者datanode节点上执行启动命令都可以,会自动启动三个workers节点:
// 推荐使用此命令启动
hdfs --workers --daemon start journalnode
或者
/home/hdfs/hadoop/sbin/hadoop-daemons.sh start journalnode
// 此时datanode节点的进程情况
[root@hslave1 ~]# jps
6551 Jps
6141 QuorumPeerMain
6303 JournalNode // hdfs集群的journalnode进程
[root@hslave2 ~]# jps
6147 JournalNode
6437 Jps
[root@hslave3 ~]# jps
6172 JournalNode
6349 Jps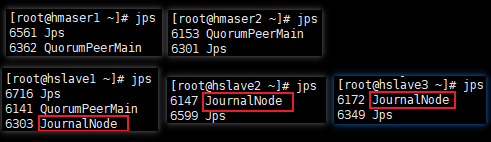
3. 格式化HDFS
在hmaster1上执行此命令:
[root@hmaser1 ~]# hdfs namenode -format格式化后会根据hdfs-site.xml中的hdfs.namenode.name.dir配置生成多个文件夹和元数据,然后拷贝元数据到 hmatser2 节点:
[root@hmaser1 ~]# scp -r /home/hdfs/hadoop/data hmaster2:/home/hdfs/hadoop/4. 格式化ZK(在hmaster1节点上执行即可)
[root@hmaser1 ~]# hdfs zkfc -formatZK5. 启动HDFS(在hmatser1上执行)
[root@hmaser1 ~]# /home/hdfs/hadoop/sbin/start-dfs.sh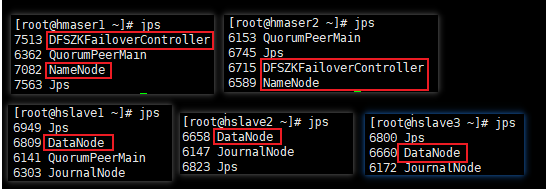
6. 启动YARN(在yarn-site.xml中配置的服务上执行:hmaster1)
[root@hmaser1 ~]# /home/hadoop/hadoop/sbin/start-yarn.sh查看resourcemanager状态:
[root@hmaser1 ~]# yarn rmadmin -getServiceState rm1
active
[root@hmaser1 ~]# yarn rmadmin -getServiceState rm2
Standy强制转换状态命令:
yarn rmadmin -transitionToStandby rm1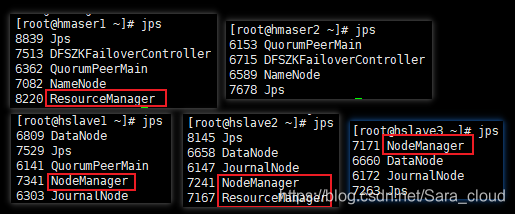
7. 验证进程
[root@hmaser1 ~]# jps
8839 Jps
7513 DFSZKFailoverController
6362 QuorumPeerMain
7082 NameNode
8220 ResourceManager
[root@hmaser2 ~]# jps
6153 QuorumPeerMain
6715 DFSZKFailoverController
6589 NameNode
7678 Jps
[root@hslave1 ~]# jps
6809 DataNode
7529 Jps
6141 QuorumPeerMain
7341 NodeManager
6303 JournalNode
[root@hslave2 ~]# jps
8145 Jps
6658 DataNode
6147 JournalNode
7241 NodeManager
7167 ResourceManager
[root@hslave3 ~]# jps
7171 NodeManager
6660 DataNode
6172 JournalNode
7263 Jps8. HDFS Web端
http://192.168.0.101:50070
Overview ‘hmaster1:9000’ (active)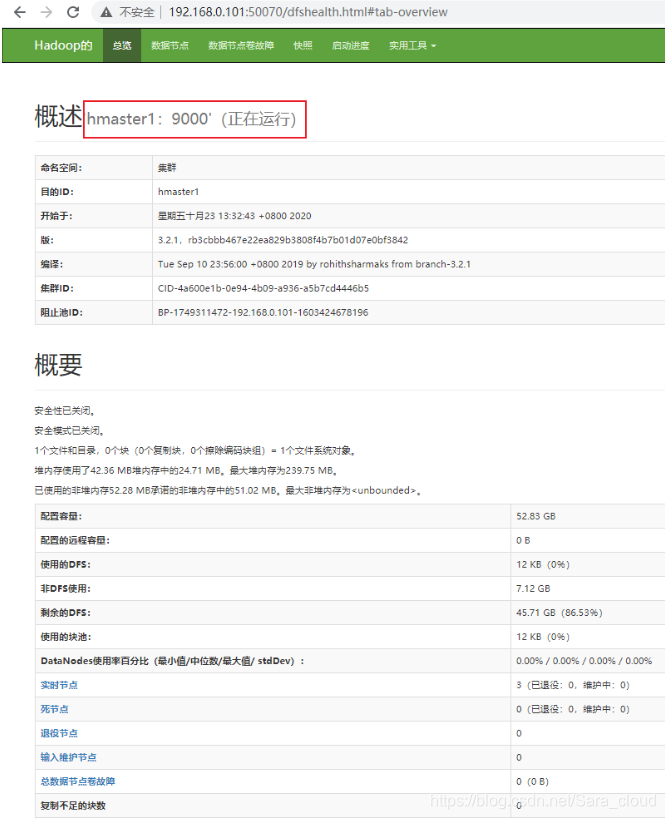
http://192.168.0.102:50070
Overview ‘hmaster2:9000’ (standby) 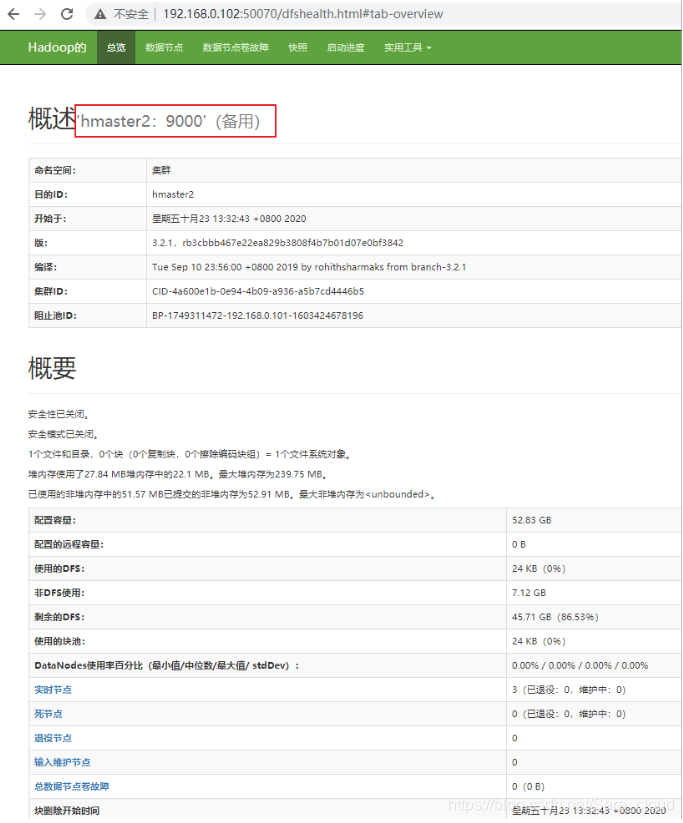
http://192.168.0.101:8088 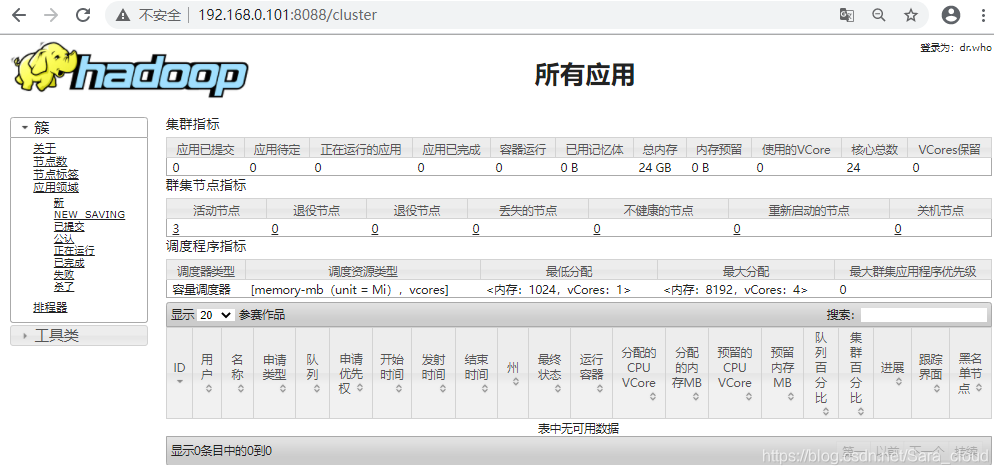
9. 查看个服务器日志
cd /home/hdfs/hadoop/logs启动时有时报异常:
Call From hmaster1/192.168.10.11 to hslave2:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81)
at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:287)
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:143)只要各进程正常启动,这个错并不影响使用,默认情况下namenode启动10s后journalnode还没有启动,就会报上述错误:

解决办法:增加或修改core-site.xml中的ipc参数
<property>
<name>ipc.client.connect.max.retries</name>
<value>60</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>6000</value>
<description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.</description>
</property>至此,Hadoop HA 集群部署完成。
4.6 停止hadoop集群
1. 停止YARN(yarn-site.xml中配置的任意一个服务上执行start-yarn.sh:hmaster1或者hslave2)
stop-yarn.sh
或
/home/hdfs/hadoop/sbin/stop-yarn.sh2. 停止HDFS(在hmaster1节点执行)
stop-dfs.sh
或
/home/hdfs//hadoop/sbin/stop-dfs.sh3. 停止zookeeper集群(在hmaster1、hmstaer2和hslave1节点执行)
[root@hmaster1 ~]# /home/hdfs/zookeeper/bin/zkServer.sh stop
[root@hmaster2 ~]# /home/hdfs/zookeeper/bin/zkServer.sh stop
[root@hslave1 ~]# /home/hdfs/zookeeper/bin/zkServer.sh stop4.7 再次正式启动hadoop
1. 启动zookeeper集群
# 在zookeeepr集群的三个节点均要执行(大几率下默认把第二个开启的zookeeper节点推举为leader角色)
/home/hdfs/zookeeper/bin/zkServer.sh start2. 启动HDFS
# 在hmaster节点执行
start-dfs.sh
或
/home/hdfs/hadoop/sbin/start-yarn.sh3. 启动YARN
# 在hmaster1或者hslave2上执行
start-yarn.sh
或
/home/hdfs/hadoop/sbin/start-yarn.sh4.8 常用命令
1. 查看hadoop文件
// 查看HDFS文件系统根目录下的文件或文件夹
[root@hmaser1 ~]#hadoop fs -ls /
// 检查HDFS整个文件系统的健康状况
[root@hmaser1 ~]#hadoop fsck /
WARNING: Use of this script to execute fsck is deprecated.
WARNING: Attempting to execute replacement "hdfs fsck" instead.
Connecting to namenode via http://hmaster1:50070/fsck?ugi=root&path=%2F
FSCK started by root (auth:SIMPLE) from /192.168.0.101 for path / at Fri Oct 23 13:57:26 CST 2020
Status: HEALTHY
Number of data-nodes: 3
Number of racks: 1
Total dirs: 1
Total symlinks: 0
Replicated Blocks:
Total size: 0 B
Total files: 0
Total blocks (validated): 0
Minimally replicated blocks: 0
Over-replicated blocks: 0
Under-replicated blocks: 0
Mis-replicated blocks: 0
Default replication factor: 3
Average block replication: 0.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 0
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
FSCK ended at Fri Oct 23 13:57:26 CST 2020 in 5 milliseconds
The filesystem under path '/' is HEALTHY2. 创建文件夹
[root@hmaser1 ~]# hdfs dfs -mkdir /inpit
[root@hmaser1 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2020-10-10 09:48 /input3. 上传文件
[root@hmaser1 ~]# hadoop fs -put /etc/profile /input
2020-10-10 09:49:09,567 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[root@hmaser1 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2020-10-10 09:49 /input4. 测试高可用
杀死hmaster1:
[root@hmaser1 ~]# jps
3393 QuorumPeerMain
3697 NameNode
4500 ResourceManager
4085 DFSZKFailoverController
5246 Jps
[root@hmaser1 ~]# kill -9 3697 // 手动模仿宕掉主节点
[root@hmaser1 ~]# jps
3393 QuorumPeerMain
4500 ResourceManager
4085 DFSZKFailoverController
5257 Jps
[root@hmaser1 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2020-10-10 09:49 /input此时hmaster2变为active,
手动启动hmaster1的namenode:
[root@hmaser1 ~]# /home/hadoop/sbin/hadoop-daemon.sh start namenode
或
[root@hmaser1 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /home/hadoop/logs/hadoop-root-namenode-hmaster1.out观察hmster1状态变为standby。
5. 主备切换
[root@hmaser1 ~]# hdfs haadmin -failover hmaster2 hmaster1
Failover to NameNode at hmaster1/192.168.0.101:53310 successful5 Hbase高可用部署(主节点hmaster1操作)
hbase历史版本下载:http://archive.apache.org/dist/hbase/
5.1 配置hbase
1. 安装hbase
tar -zvxf hbase-2.2.5-bin.tar.gz
mv hbase-2.2.5 /home/hdfs/hbase2. 配置环境变量
vim /etc/profile
# hbase environment
export HBASE_HOME=/home/hdfs/hbase
export PATH=.:$HBASE_HOME/bin/:$PATH
source /etc/profile3. 配置hbase-env.sh
vim /home/hdfs/hbase/conf/habse-env.sh
export JAVA_HOME=/usr/local/jdk8
export HADOOP_HOME=/home/hdfs/hadoop
export HBASE_HOME=/home/hdfs/hbase
# 关闭自带zookeeper,采用外部自定义部署的zookeeper
export HBASE_MANAGES_ZK=false
# 修改存储pid文件的目录,默认为/tmp
export HBASE_PID_DIR=/home/hdfs/hbase/pidsmkdir -p /home/hdfs/hbase/pids4. 配置hbase-site.xml
vim /home/hadoop/hbase/conf/hbase-site.xml
<configuration>
<!-- hadoop集群名称 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hmaster1,hmaster2,hslave1</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- 是否是完全分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 完全分布式式必须为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 指定缓存文件存储的路径 -->
<property>
<name>hbase.tmp.dir</name>
<value>/home/hdfs/hbase/data/hbase_tmp</value>
</property>
<!-- 指定Zookeeper数据存储的路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hdfs/hbase/data/zookeeper_data</value>
</property>
</configuration>mkdir -p /home/hdfs/hbase/data/{hbase_tmp,zookeeper_data}注意:$HBASE_HOME/conf/hbase-site.xml 的 hbase.rootdir 的value值(包括主机和端口号)要与 $HADOOP_HOME/conf/core-site.xml 的 fs.default.name 的value值(包括主机和端口号)一致。
5. 配置regionservers
修改文件 $HBASE_HOME/conf/regionservers,添加DataNode节点的IP或者主机名:
vim /home/hdfs/hbase/conf/regionservers
hslave1
hslave2
hslave35.2 配置Hmaster高可用
为了保证Hbase集群的高可靠性,Hbase支持多 Backup Master 设置;当 Active Master 宕掉后,Backup Master 可以自动接管整个Hbase集群;
在 $HBASE_HOME/conf/ 目录下新增配置文件 backup-masters,在其内添加要用做 Backup Master 的节点。
vim /home/hdfs/hbase/conf/backup-masters
hmaster2在没设置backup-masters前启动hbase,只有主节点启动了HMaster进程;
当配置完成后,,重亲启动整个集群,会发现在backup-master清单上的主机,都启动了HMaster进程。
复制hmaster1的hbase目录到集群的其余四个主机节点:
[root@hmaser1 ~]# scp -r /home/hdfs/hbase hmaster2:/home/hdfs/
[root@hmaser1 ~]# scp -r /home/hdfs/hbase hslave1:/home/hdfs/
[root@hmaser1 ~]# scp -r /home/hdfs/hbase hslave2:/home/hdfs/
[root@hmaser1 ~]# scp -r /home/hdfs/hbase hslave3:/home/hdfs/
[root@hmaser1 ~]# scp -r /etc/profile hmaster2:/etc/
[root@hmaser1 ~]# scp -r /etc/profile hslave1:/etc/
[root@hmaser1 ~]# scp -r /etc/profile hslave2:/etc/
[root@hmaser1 ~]# scp -r /etc/profile hslave3:/etc/
// 环境配置文件生效
source /etc/profile5.3 启动HBase
1. 按照上面4.7的步骤顺序先启动hadoop集群,然后再再hmaster1上启动hbase
[root@hmaster1 ~]# start-hbase.sh
或
[root@hmaster1 ~]# /home/hdfs/hbase/bin/start-hbase.sh
[root@hmaster1 ~]# jps
31988 DFSZKFailoverController
524 Jps
32532 HMaster
32763 Main
31670 NameNode2. 停止hbase
[root@hmaster1 ~]# stop-hbase.sh
或
[root@hmaster1 ~]# /home/hdfs/hbase/bin/stop-hbase.sh
3. log4j冲突处理
启动hbase时会报错:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hdfs/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hdfs/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]原因是有两个log4j的jar起了冲突,删除每个主机节点的其中一个即可:

cd /home/hdfs/hbase/lib/client-facing-thirdparty/
mv slf4j-log4j12-1.7.25.jar slf4j-log4j12-1.7.25.jar.bak4. HBase Web
HMaster:http://192.168.0.101:16010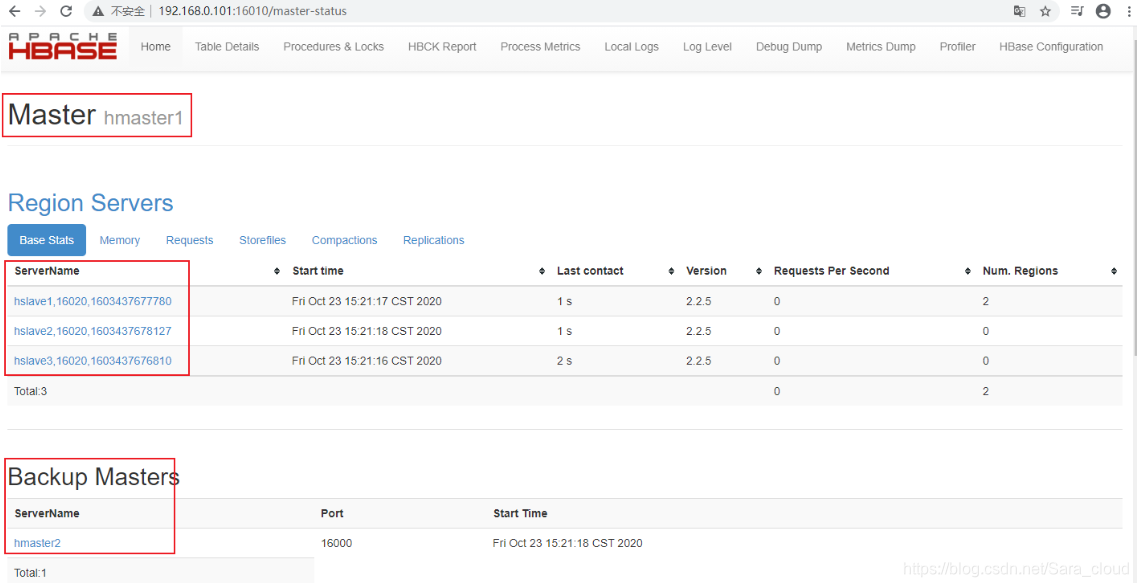
HMaster:http://192.168.0.102:16010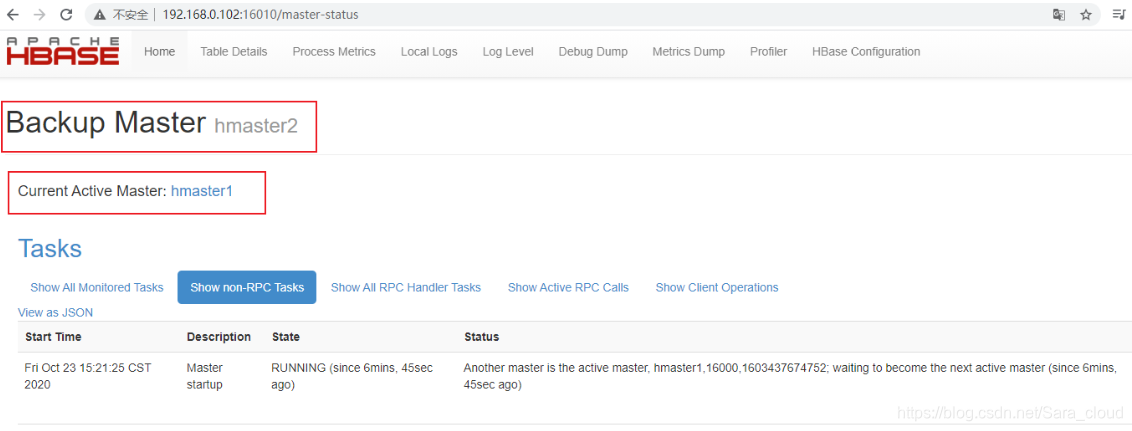
5.4 最终进程
[root@hmaster1 ~]# jps
7073 DFSZKFailoverController
7475 ResourceManager
8501 HMaster
8917 Jps
7911 NameNode
6441 QuorumPeerMain
[root@hmaser2 ~]# jps
5137 HMaster
5491 Jps
4244 QuorumPeerMain
4372 NameNode
4457 DFSZKFailoverController
[root@hslave1 ~]# jps
4656 NodeManager
5281 Jps
4322 QuorumPeerMain
4933 HRegionServer
4538 JournalNode
4444 DataNode
[root@hslave2 ~]# jps
4432 JournalNode
5233 Jps
4338 DataNode
4547 ResourceManager
4923 HRegionServer
4621 NodeManager
[root@hslave3 ~]# jps
5028 Jps
4298 JournalNode
4731 HRegionServer
4204 DataNode
4414 NodeManager5.5 HBase常用命令
1. Common
- 启动hbase shell:hbase shell
- 帮助查看所有命令:help
- 查看版本:version
- 查看当前用户:whoami
2. DDL
- 创建表:create ‘firstTable’,‘cf1’, ‘cf2’
- 使用create命令创建一个表,必须指出表名和ColumnFamily名(列族名)
- 列出表清单:list
- 查看表数据:list ‘firstTable’
- 展示一个表的详细信息:describe ‘firstTable’
- 禁用表:disable ‘firstTable’
- 启用表:enable ‘firstTable’
- 查看是否启用/禁用: is_enabled/is_disabled
- 删除表:先禁用再 drop ‘tablemame’
- 查看命名空间:list_namespace
3. DML
- 插入记录:put ‘firstTable’,‘rowkey’,cf:key’,‘value’
put ‘firstTable’, ‘row1’, ‘cf1’, ‘row1cf1value’
put ‘firstTable’, ‘row1’, ‘cf2’, ‘row1c21value’
put ‘firstTable’, ‘row2’, ‘cf1’, ‘row2cf1value’
put ‘firstTable’, ‘row2’, ‘cf2’, ‘row2c21value’- 获取记录:get ‘firstTable’,‘rowkey’,‘cf:key’
get ‘firstTable’,‘row1’,‘cf1’
get ‘firstTable’,‘row1’,‘cf1’- 扫描记录:scan ‘firstTable’
HBase 的 HA 高可用集群部署完成。
6 高可用进程
zookeeper集群分别部署在三个节点上,可以在active master宕掉的基础上,自动选举出一个新的leader,顶替已经挂掉的master,由standby的备用状态转换为active状态,从而不影响正在运行的集群服务。
已经宕掉的hmaster在恢复后,作为standby状态,自动加入集群服务;可以手动切换两个hmaster的主备状态,将之前宕掉后又恢复的hmaster状态手动切换回active;由此可以进行测试hdfs的高可用是否可行。
在hdfs HA集群测试成功后,hbase HA高可用集群可接着部署安装配置;在java程序接入成功测试后,则代表Hdfs+HBase的HA集群正式部署成功。
7 Hdfs+HBase HA集群启动 - 停止
7.1 启动集群
1. 启动zokeeper集群(hmaster1、hmaster2、hslave1)
/home/hdfs/zookeeper/bin/zkServer.sh start2. 启动hadoop集群
启动hdfs(hmaster1):
start-dfs.sh启动yarn(hmaster1或hslave2):
start-yarn.sh3. 启动hbase集群(hmaster1)
start-hbase.sh7.2 停止集群
1. 停止hbase集群(hmaster1)
stop-hbase.sh2. 停止hadoop集群
停止yarn(hmaster1或hslave2):
stop-yarn.sh停止hdfs(hmstaer1):
stop-dfs.sh3. 停止zookeeper集群(hmstaer1、hmatser2、hslave1)
/home/hdfs/zookeeper/biin/zkServer.sh stop

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









