










2023/09/30 - 2023/10/02
该文章主要记录自己在阅读论文和代码时的一些思路
原文地址:Unsupervised Time-Aware Sampling Network with Deep Reinforcement Learning for EEG-Based Emotion
github代码库:TAS-NET
解决问题:
这篇论文试图解决使用脑电信号识别人类情感时所面临的困难。由于情感状态是动态变化的,而传统方法只能给整个情感诱发过程分配一个固定的标签,无法充分考虑情感动态和脑电信号的非平稳性。因此,论文提出了一种基于深度强化学习的无监督情感识别方法,该方法可以检测关键情感片段并忽略无关和误导性的部分。具体来说,该方法将从脑电信号时间序列中挖掘关键情感片段的过程建模为马尔可夫决策过程,并通过深度强化学习训练一个具有时间感知能力的智能体。智能体从特征提取器获取深度特征作为输入,并生成反映每个样本包含的情感相关信息的样本重要性分数。基于获得的样本重要性分数,该方法保留了具有相关情感的前X个连续脑电片段,并丢弃其余部分。最后,将这些连续片段视为关键情感片段,并将它们馈入超图解码模型进行无监督聚类。
Q&A:
Q:该论文给出的eeg处理流程是什么样的?
A:该论文提出了一种基于深度强化学习的时间感知采样网络(TAS-Net),用于无监督情绪识别。首先,该方法使用特征提取器提取深度特征,并将其作为时间感知代理的输入,生成反映每个样本所含情感相关信息的样本级重要性评分。然后,基于得到的样本级重要性评分,该方法保留具有相关情感的前X个连续EEG片段,并且丢弃其余的片段。最后,将这些连续片段作为关键情感片段输入到一个超图解码模型中进行无监督聚类。同时,该方法还提出了一种适应性高、无需标注信息的关键情感片段选择方法,称为时间感知采样方法。该方法使用马尔可夫决策过程来解释从EEG时间序列中挖掘关键情感片段的过程,并通过DRL训练时间感知代理进行关键情感片段的选择。以上信息主要来源于C. time-aware sampling,D. unsupervised clustering model
Q:图神经网络在这里起到了什么样的作用?
A:在这篇论文中,图神经网络被用作时间感知采样网络(TAS-Net)的一部分。具体来说,TAS-Net使用深度强化学习(DRL)训练一个时间感知代理来检测关键情感片段并且舍弃不相关和误导性的片段。图神经网络被用于TAS-Net中的局部基于时间的图卷积网络(GCN)部分来计算图的拉普拉斯矩阵。因此,图神经网络在这篇论文中的作用是提供了一种有效的方法来处理 EEG 时间序列信号,并可以帮助提高情感识别的准确性。
Q: 在这里如何选取需要的EEG片段,具体方法是什么?
A:在这篇论文中,提出了一种基于时间感知采样网络(TAS-Net)的方法来自动检测EEG信号中的关键情感片段。具体方法如下:
- 首先,使用深度特征提取器(EEG-FuseNet)从EEG信号中提取样本级别的深层次EEG特征。
- 接着,使用时间感知代理(TAS)将这些深层次特征映射到样本级别的情感相关信息,生成代表每个样本所包含情感相关信息的样本级别重要性分数。
- 根据样本级别重要性分数,保留与情感相关的前X个连续的EEG片段,并将其作为关键情感片段。
- 最后,使用超图解码模型进行无监督聚类,实现情感识别。
因此,选取需要的EEG片段的具体方法是基于时间感知代理(TAS)生成的样本级别重要性分数,保留与情感相关的前X个连续的EEG片段,并将其作为关键情感片段。
代码分析:
图1 文件夹详情
p.s.以下代码含有自己修改的部分
1.数据集处理
在这个步骤中,因为源代码并没有给出用于跑代码的原数据,故只能通过自己处理SEED数据集得到所需的数据文件,即图1中build_data.py中的内容,具体如下:
# 构建用于feature_extractor的数据集
import os
import numpy
import h5py
import scipy.io as sio
# 每个.mat文件中的数据label
basic_label = [1, 0, -1, -1, 0, 1, -1, 0, 1, 1, 0, -1, 0, 1, -1]
def read_files(read_path, save_path):
# 读取文件夹下所有.mat文件
print("read_all_files start...")
# 遍历Preprocessed_EEG文件夹下所有.mat文件,每三个文件一轮
file_list = []
for root, dirs, files in os.walk(read_path):
for file in files:
if os.path.splitext(file)[1] == '.mat':
file_path = os.path.join(root, file)
file_list.append(file_path)
print("共读取了{}个文件".format(len(file_list)))
for sub in range(0, 1):
# 15位被试
# 在save_path下创建文件夹
sub_path = os.path.join(save_path, 'sub_' + str(sub + 1))
if not os.path.exists(sub_path):
os.makedirs(sub_path)
for session in range(0, 3):
# 每位被试三个mat文件
# 创建文件夹
session_path = os.path.join(sub_path, 'session' + str(session + 1))
if not os.path.exists(session_path):
os.makedirs(session_path)
# 读取数据,读取第sub*3+session个
file_path = file_list[sub * 3 + session]
data = sio.loadmat(file_path)
# 构建存入新mat文件的字典,可以按以下格式读取
"""
data, label = scio.loadmat(info)['Data'][0, 0]['eeg_data'], scio.loadmat(info)['Data'][0, 0][
'label']
"""
# 获取单个文件中的keys并转化为list,获取数据所在key
keys = list(data.keys())[3:]
for i in range(len(keys)):
# 获取数据
stamp = data[keys[i]]
# 转化为二维数组
stamp = stamp.reshape(stamp.shape[0], stamp.shape[1])
# 取每个通道的100*n 到 100*n + 384的数据
for j in range(0, 3394):
new_data = {}
new_data['Data'] = {}
new_data['Data']['eeg_data'] = []
new_data['Data']['label'] = []
eeg_data_list = stamp[:, j:j + 384]
label = basic_label[i]
new_data['Data']['eeg_data'] = eeg_data_list
new_data['Data']['label'].append(label)
# 保存数据
save_file_path = os.path.join(session_path, 'sub_' + str(sub + 1) + '_session' + str(
session + 1) + '_data' + str(i + 1) + '_eeg_data' + str(j + 1) + '.mat')
sio.savemat(save_file_path, new_data)
def main():
read_path = '。。。。。'
save_path = 'dataset_auto_384_seed'
read_files(read_path, save_path)
# 读取文件features/session_1/source_h5_file.h5
f = h5py.File('features/session_1/source_h5_file.h5', 'r')
print(f['source_10_video_01'])
if __name__ == '__main__':
main()
由feature_extractor.py中以及作者github上对于数据集情况的问答,我们可以得到代码所用数据集的大致情况。
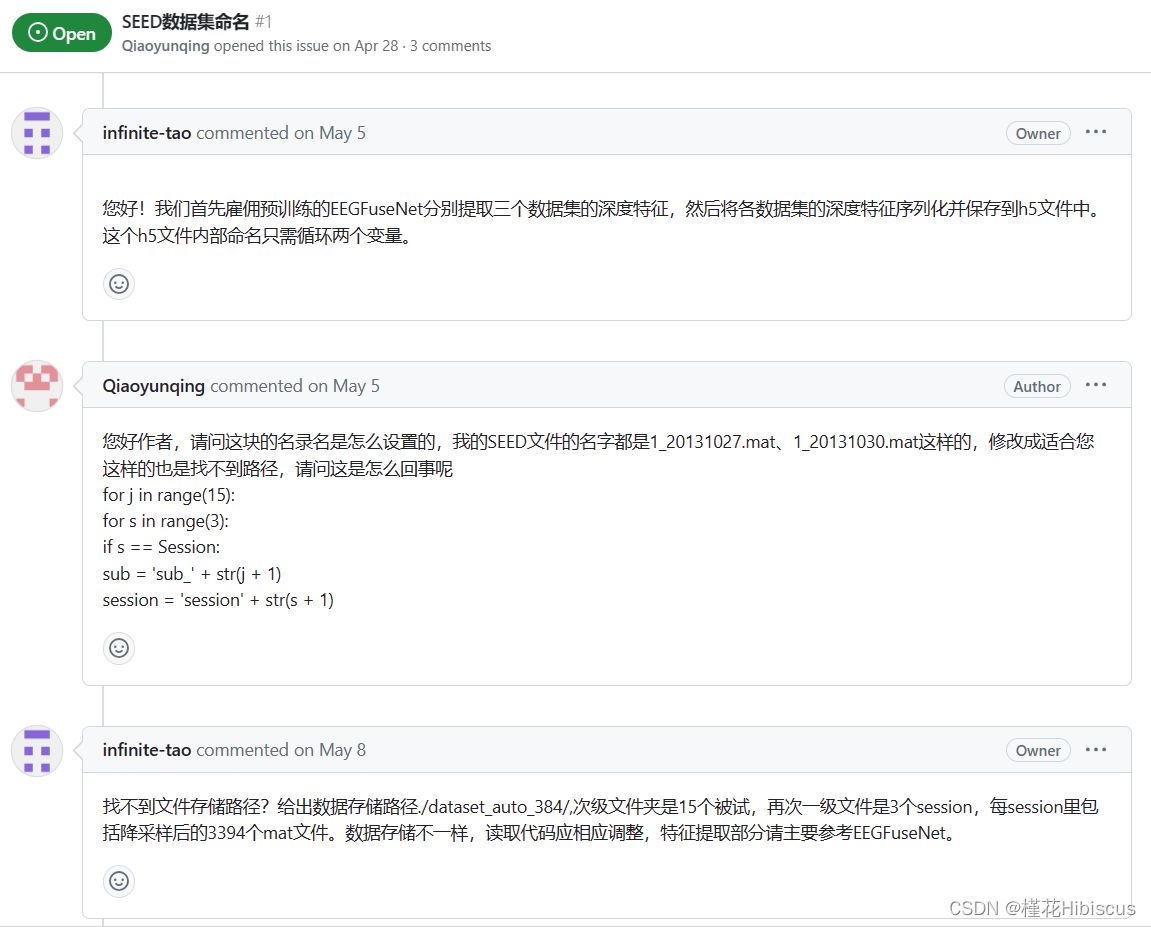
图2 数据集构造方式
给出数据存储路径./dataset_auto_384/,次级文件夹是15个被试,再次一级文件是3个session,每session里包括降采样后的3394个mat文件。
p.s 按照seed数据集的原数据,每个session下面可是有15个试次,我很疑惑是怎么分出3394个文件的,但按照代码后面,每一个视频的采样点数量是不同的,这与降采样后采样点的数量有关。
由于不知道作者降采样的具体细节,为了使数据的构造更加简单规整,在这里我们暂且只使用一个被试的数据构建数据集,在每个session下面放15个试次*3394个文件,并用于之后的代码。如果按作者的方法来将所有的数据构建为数据集,那么数据集的大小会达到50G-60G之多。
当然像本文这样这样构造数据肯定是存在一些问题的,即将跨被试问题转化为了较为简单的同一被试问题,且标签有部分错乱,读者可能需要自己进一步修改。这里采用较为简单的数据集构造方式,即只使用一个被试,具体如下所示:
检查feature_extractor.py文件,通过读取mat文件的函数来获得需要生成mat文件的格式;
def get_dataset_seed(norm_type, resolution, Session):
data_list = []
label_list = []
# mark:被试修改为1人
for j in range(1):
for s in range(3):
if s == Session:
sub = 'sub_' + str(j + 1)
session = 'session' + str(s + 1)
data_path = 'dataset_auto_384_seed/'
path_im = os.path.join(data_path, sub)
path = os.path.join(path_im, session)
times = 1
for info in os.listdir(path):
domain = os.path.abspath(path) # 获取文件夹的路径
info = os.path.join(domain, info) # 将路径与文件名结合起来就是每个文件的完整路径
data, label = scio.loadmat(info)['Data'][0, 0]['eeg_data'], scio.loadmat(info)['Data'][0, 0][
'label']
for i in range(times):
data_list.append(data)
label_list.append(label)
# X_data是一个四维数组(样本数,——,通道数,采样点数)
X_data = np.reshape(data_list, (np.shape(data_list)[0], 1, 62, 384))
X_label = np.reshape(label_list, (np.shape(data_list)[0], 1))
print(X_data.shape)
print(X_label.shape)
"""
(50910, 1, 62, 384)
(50910, 1)
"""
# 在这里根据传入参数对数据进行不同的归一化处理
if norm_type =='ele':
data_tmp = copy.deepcopy(X_data)
label_tmp = copy.deepcopy(X_label)
for i in range(len(data_tmp)):
for j in range(len(data_tmp[0])):
data_tmp[i][j] = utils.norminy(data_tmp[i][j])
if norm_type == 'global_scale_value':
data_tmp = (X_data - np.min(X_data)) / (np.max(X_data) - np.min(X_data))
if norm_type == "global_gaussian_value":
data_tmp = (X_data - np.mean(X_data)) / np.std(X_data)
if norm_type == "pixel_scale_value":
data_tmp = data_norm(X_data, resolution)
if norm_type == "origin":
data_tmp = X_data
# X_data, valid_data = train_test_split(X_data, test_size=0.1, random_state=0)
return data_tmp, label_tmp每一个被试对应3个session,这在SEED原数据集上对应每个被试3个mat文件,每一个session内又存在15个试次,15个试次每个都对应降采样后的3394个mat文件。
因为现在我们将使用的被试数量变为一个,因此在一个试次中我们便需要生成3394个mat文件:15(被试)*3(session)*3394(文件)= 1(被试)*3(session)*(15(试次)*3394(文件))。可以看出这样构造得到的数据量是一样的,只要在一个试次中得到3394个mat文件即可,且根据读入数据的X_data,可得每一个mat文件包括62个通道的384个采样点和1个label,数据集的构造参考如下:
数据存储路径/dataset_auto_384_seed/sub_{1,15}\\session{1,3}/.mat mat contains {'Data':{'eeg_data': ,'label': }}p.s.存储路径的文件夹需要提前创建好
这样经过处理之后便可以得到X_data,格式为(50910, 1, 62, 384)。
2.深度特征提取
关于前文的数据集构造部分,重新看了一遍好像还是有诸多前后矛盾的问题,但是按照上文给出的公式 15(被试)*3(session)*3394(含15试次的总文件数量,每个试次数量不同)= 1(被试)*3(session)*(15(试次)*3394(文件))来看应该没什么问题,如果想要正确构造数据集应该按前面的式子来,这里暂且略去不表,接下来能动就行。
在创建完数据集并可以成功读取之后,接下来是进行深度特征提取的过程,该论文中使用EEGFuseNet进行深度特征提取,参考特征提取代码后面部分h5文件的构造,h5文件中存在15(被试)*15(视频)的数据,每份数据包括得到的特征和标签。
以下是与该网络相关的部分代码和解释:
model = EEGfuseNet_Channel_62(16, 1, 1, 384).to(device)loader_data = Data.DataLoader( dataset=torch_dataset_train(shape:(50910, 1, 62, 384)), batch_size=BATCH_SIZE(128), shuffle=False, num_workers=0, )class EEGfuseNet_Channel_62(nn.Module): ## Channel 62 network for SEED dataset. def __init__(self,hidden_dim,n_layer,n_filters,input_size):# - hidden_dim: 循环层中的隐藏单元数。
# - n_layer: 循环层的数量。
# - n_filters: 卷积层中的滤波器数量。
# - input_size: 输入特征的维度。
下面是该网络前向传播层的部分解释:
def forward(self,x):
# encoder
# 经过conv1后,输出的shape为(128, 16, 62, 384)
# 通道内进行卷积(横卷积)
x = self.conv1(x)
# 批量归一化
x = self.batchNorm1(x)
# Layer 2
# 经过depthwiseconv2后,输出的shape为(128, 32, 62, 384)
# 通道间进行卷积(纵卷积)
x = self.depthwiseconv2(x)
# 批量归一化
x = self.batchNorm2(x)
# 激活函数
x = F.elu(x)
# 经过pooling1后,输出的shape为(128, 32, 62, 96)
x,idx2 = self.pooling1(x) # get data and their index after pooling
# dropout
x = self.dropout1(x)
# Layer 3
# 经过separa1conv3后,输出的shape为(128, 32, 62, 96)
x = self.separa1conv3(x)
# 经过separa2conv4后,输出的shape为(128, 16, 62, 96)
x = self.separa2conv4(x)
# 批量归一化
x = self.batchNorm3(x)
# 非线性激活函数
x = F.elu(x)
# 经过pooling2后,输出的shape为(128, 16, 62, 12)
x,idx3 = self.pooling2(x)
# Layer 4:FC Layer
# permute函数用于维度交换,x.permute(0,3,2,1)表示将x的第0维和第1维交换,第2维和第3维交换,第3维和第4维交换
# 维度交换后,x的shape为(128, 12, 62, 16)
x =x.permute(0,3,2,1)
# x[:,:,-1,:,]表示取x的第2维的最后一个元素,即只取最后一个通道的数据,x的shape变为(128, 12, 16)
# 这里的变换是为了之后gru的输入维度匹配,该通道的感受野已经包含了所有通道的信息
x =x[:,:,-1,:,]
# 经过fc1后,输出的shape为(128, 12, 16)
x =self.fc1(x)
# 非线性激活函数
x =F.elu(x)
# 如果输入的tensor有三个维度,gru的输入方式是:(sequence_length, batch_size, input_size)
# 在设置batch_first=True的情况下,gru的输入方式是:(batch_size, sequence_length, input_size)
out,_=self.gru_en(x)
# 经过gru_en后,因为是双向,因此输出的shape为(128, 12, 32)
x=out
# 经过fc2后,输出的shape为(128, 12, 16)
x = self.fc2(x)
# code的shape为(128, 192)
code=x.reshape((x.shape[0],int(16*self.n_filters)*int(self.length)))
# decoder
# 解码
x = self.fc3(x)
out,_=self.gru_de(x)
x = out
x = self.fc4(x)
x = F.elu(x)
x = x.reshape((x.shape[0],x.shape[1],1,x.shape[2]))
x = x.permute(0,3,2,1)
x = self.unpooling2(x, idx3)
x = self.desepara2conv4(x)
x = self.desepara1conv3(x)
x = self.batchnorm4(x)
x = self.dropout4(x)
# Layer 3
x = F.elu(x)
x = self.unpooling1(x, idx2)
x = self.dedepthsepara1conv3(x)
x = self.batchnorm5(x)
# Layer 4
x = self.deconv1(x)
return x,code这个网络的设计还是挺复杂的,采用了VAE的结构,分为编码器和解码器两个部分,最后x的输出维度跟输入维度相同。得到的特征是网络中间的code。之前一直在疑惑深度学习中的编码器和解码器架构的意义,今天看了一下午EEGFuseNet终于有所体会,原来提取深度特征是这个意思:通过将原始信号抽象解构为特征编码,再将其重构为原始信号,loss与输入输出信号的相似度相关,如果得出的输出信号与原始信号越接近,说明得到的特征编码越有意义,这是一个不断更新网络中参数使网络输出与原始信号更加接近的过程。
源代码中使用EEGFuseNet提取特征还需要一个预训练参数文件,这就需要针对这个模型进行预训练,这里就需要理解其中使用的生成对抗网络的思想,使用判别器(原论文中使用的是原数据与生成数据的均方误差)来对该网络进行训练。
在提取出深度特征之后,将其存入h5文件中供main.py进行处理,流程简单,可参考源代码。
参考文献:
EEGFuseNet高维脑电图混合无监督深度特征表征与融合模型及其在情绪识别中的应用
深入理解深度学习——Transformer:编码器(Encoder)部分
3. 强化学习选取特征片段
在划分完测试集训练集之后,接下来是强化学习的训练部分,在这个部分中,需要着重理解的是其中使用的深度学习网络classifierGNN和DSN。
强化学习实现的大概流程如下图所示:
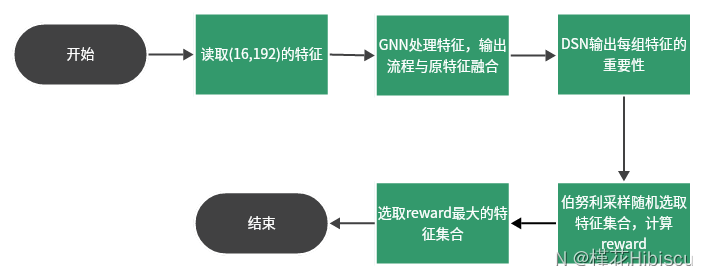
图3 强化学习流程
以上流程便是该论文中选取时间片的算法,接下来将对此展开具体阐述。
首先查看一下图神经网络classifierGNN的结构:
"""
这个模型是一个用于图数据的图神经网络(GNN),用于节点分类任务。
它包括两个子模型,一个用于处理图边,另一个用于处理图节点,以及将它们组合在一起的前向传播过程。
模型的目标是学习节点特征表示,并输出节点的特征表示和边的相似性。
"""
class ClassifierGNN(nn.Module):
def __init__(self, in_features, edge_features, out_features, device):
# 每次读取特征数量为192个
# 每次读取边特征数量为32个
# 输出特征数量为192个
# 输入数据的shape基本为(16, 192)
super(ClassifierGNN, self).__init__()
self.edge_net = EdgeNet(in_features=in_features,
num_features=edge_features,
device=device)
# set edge to node
self.node_net = NodeNet(in_features=in_features,
num_features=out_features,
device=device)
# mask value for no-gradient edges
self.mask_val = -1
def label2edge(self, targets):
''' convert node labels to affinity mask for backprop'''
# 作用是将标签转换为反向传播的亲和力掩码
num_sample = targets.size()[0]
label_i = targets.unsqueeze(-1).repeat(1, 1, num_sample)
label_j = label_i.transpose(1, 2)
edge = torch.eq(label_i, label_j).float()
target_edge_mask = (torch.eq(label_i, self.mask_val) + torch.eq(label_j, self.mask_val)).type(torch.bool)
source_edge_mask = ~target_edge_mask
init_edge = edge * source_edge_mask.float()
return init_edge[0], source_edge_mask
def forward(self, init_node_feat):
# 输入数据的shape基本为(16, 192)
# 计算归一化和非归一化的相似度矩阵
edge_feat, edge_sim = self.edge_net(init_node_feat)
# compute node features and class logits
# 计算节点特征和类别logits
features_gnn = self.node_net(init_node_feat, edge_feat)
return features_gnn, edge_sim这个图神经网络最后得到的输出数据shape与输入数据相同,之后还将GNN得出的特征与原来的特征相加,这一步融合特征的操作其实我不是很理解。
接下来对DSN网络进行研究,这个网络较为简单,注重于上下文信息,根据注意力机制输出每组特征的重要性,同样也是深度强化学习中的策略输出网络:
class DSN(nn.Module):
"""Deep Summarization Network"""
def __init__(self, in_dim=1024, hid_dim=256, num_layers=1, cell='lstm'):
super(DSN, self).__init__()
assert cell in ['lstm', 'gru'], "cell must be either 'lstm' or 'gru'"
if cell == 'lstm':
self.rnn = nn.LSTM(in_dim, hid_dim, num_layers=num_layers, bidirectional=True, batch_first=True)
else:
self.rnn = nn.GRU(in_dim, hid_dim, num_layers=num_layers, bidirectional=True, batch_first=True)
self.fc = nn.Linear(hid_dim*2, 1)
def forward(self, x):
h, _ = self.rnn(x)
# p = F.sigmoid(self.fc(h))
p = torch.sigmoid(self.fc(h))
# pdb.set_trace()
return p在每个epoch中,为每组特征(特征排布为时序)根据网络输出重要性的伯努利分布采样五次并计算每次选取片段集合的reward,reward分为多样性奖励和代表性奖励两个部分。其中,多样性奖励由选取时间片段之间的相似度决定,相似度越大reward越大。而代表性奖励似乎同样与时间片段之间的相似度有关,但是本人不是很理解这里所说代表性奖励的意义,其代码如下:
dist_mat = torch.pow(_seq, 2).sum(dim=1, keepdim=True).expand(n, n)
# dist_mat 是一个对称矩阵,因此可以将其转置并与原始矩阵相加,以获得每对帧之间相似度
dist_mat = dist_mat + dist_mat.t()
dist_mat = torch.addmm(input=dist_mat, beta=1, mat1=_seq, mat2=_seq.t(), alpha=-2)
# 选择帧的子矩阵
dist_mat = dist_mat[:, pick_idxs]
if len(dist_mat.shape) == 1:
dist_mat = dist_mat.unsqueeze(dim=1)
dist_mat = torch.min(dist_mat, 1, keepdim=True)
dist_mat = dist_mat[0]
# 代表性奖励(reward_rep)
reward_rep = torch.exp(-dist_mat.mean())最后输出的reward是多样性、代表性reward两者的均值。据本人看来,这里的强化学习范式应用了基线奖励等思想以及深度学习网络,应该是梯度策略算法,宜与参考资料结合理解。
4.模型评估与聚类
模型使用之前选取的测试集进行评估得出recall分数,并将能得出最大recall分数的模型参数存储在本地文件中——涉及这个方面的是evaluate.py文件中的内容。
这里的计算方法让我有些疑惑,因为作者已经用不知道什么方法直接指定了测试集的重要时间片段local_labels,只要得出的结果与其重叠率越高便越好。这个指定方法不得而知,只能去GitHub上询问作者。
显然作者的代码未展示完全,尚缺少聚类的部分,但是这个问题也不大。在设置training为false之后,通过与模型评估类似的流程,同样过了一遍测试集后记录日志,开始提取剩下数据的代表性时间片段及其特征,并且在标明与之相应的label后存入文件中,按照作者的意图,在之后应当针对这些代表性时间片段进行聚类。
总结:
写到这里我大概明白了,作者的意图在于代表性的时间片特征提取出来,表征在观看视频整个阶段中的情感动态变化的过程,但是这样的方法似乎也有失偏颇,如果需要体现出该方法的优越性,我认为一个体现了被试情感在一个时间段内连续变化且带有阶段性标签的数据集更加符合需求。除此之外,关于GNN的应用,本文并没有将脑电通道之间的关系纳入GNN的范围内考虑,而是直接提取深度特征,将时序上邻近的特征向量输入GNN中,我暂时想不到为何要使用这种方法。最后,也是在模型评估部分提到的,作者尚未给出测试集中关键情感时间片段数据的由来,这一点需要等待作者回答,当然也可能是我在阅读的过程中仍然有所疏忽。
该论文使用的方法,特别是强化学习的策略梯度方法以及提取深度特征的方法让我获益颇丰,也感到了自己的不足,这几天的所得必将活用于下一次。
update at 2023/10/11:
将该方法用于疲劳分级中,三分类得到准确率大概为0.38-0.45左右。
















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









