






论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
(Liang-Chieh Chen, George Papandreou, Senior Member, IEEE, Iasonas Kokkinos, Member, IEEE, Kevin Murphy, and Alan L. Yuille, Fellow, IEEE)
个人学习笔记。
论文出处:下载.
论文相关代码、模型出处:DeepLab.
文章主要提出了三点:
1.使用上采样滤波器的卷积,或者作为密集预测任务中的强大工具,“atrous covolution”。Atrous卷积允许我们明确地控制在深度卷积神经网络内计算特征响应的分辨率。它还使我们能够有效地扩大过滤器的视野,以在不增加参数数量或计算量的情况下结合更大的上下文。
(关于atrous covolution名称的来源:滤波器上采样相当于在非零滤波器抽头之间插入孔(法语为“trous”)。 这种技术在信号处理方面有着悠久的历史,最初是为了有效地计算 undecimated wavelet transform而开发的,该方案也被称为“algorithme a` trous”。 我们使用术语atrous convolution作为与上采样滤波器卷积的简写。)
2.其次,Atrous Spatial pyramid pooling(ASPP)以在多个尺度上强健地分割对象。 ASPP用多个采样率和有效的视场来探测具有滤波器的输入卷积要素图层,从而以多个比例捕获对象以及图像上下文。
3.第三,通过结合DCNN和概率图模型的方法,我们改进了对象边界的局部化。在DCNNs中最常使用的最大汇集和下采样的组合实现了不变性,但是对定位精度有影响。我们通过将最终的DCNN层的响应与完全连接的条件随机场(CRF)相结合来克服这个问题,所述条件随机场(CRF)被定性和定量地显示以改善局部性能。
VGG-16或ResNet-101等深度卷积神经网络以完全卷积的方式使用,使用无量级卷积来降低信号下采样的程度(从32x下降到8x)。 双线性插值阶段将特征映射放大为原始图像分辨率。 然后应用完全连接的CRF来细化分割结果并更好地捕捉对象边界:

用于密集特征提取和视野扩大的atrous convolution:
(如果使用deconvolutional layers ,需要额外的内存何时间)

2-D中的atrous convolution。 顶行:在低分辨率输入特征图上使用标准卷积进行稀疏特征提取。 底行:密度特征抽取,速率r = 2的无限卷积,应用于高分辨率输入特征图。
通过上图中一个简单的例子来说明算法在2D中的运算:给定一个图像,假设我们首先有一个下采样操作,将分辨率降低2倍,然后用内核进行卷积 - 这里是垂直高斯导数。如果在原始图像坐标中植入所得到的特征图,则我们意识到,我们仅在1/4图像位置处获得了响应。相反,如果我们将全分辨率图像与“带孔”滤波器进行卷积,我们可以计算所有图像位置处的响应,其中我们将原始滤波器上采样2倍,并在滤波器值之间引入零。尽管有效的滤波器尺寸增加,但我们只需要考虑非零滤波器值,因此滤波器参数的数量和每个位置的操作数量都保持不变。由此产生的方案使我们能够轻松而明确地控制神经网络特征响应的空间分辨率。
多尺度图像表示使用Atrous Spatial Pyramid Pooling(ASPP)

上图:Atrous Spatial Pyramid Pooling(ASPP)。 为了对中心像素(橙色)进行分类,ASPP通过采用具有不同速率的多个并行滤波器来利用多尺度特征。 有效的视野以不同的颜色显示。
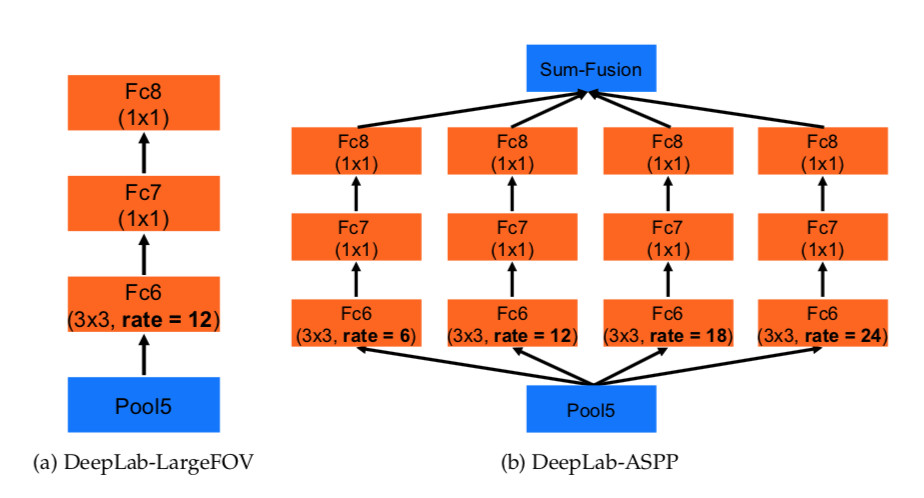
第二种方法受到R-CNN空间金字塔池化方法的成功启发,该方法表明任意尺度的区域可以通过对单一尺度提取的卷积特征进行重采样来准确而有效地进行分类。 我们已经实现了他们的方案的变体,它使用具有不同采样率的多个平行的非均匀卷积层。 针对每个采样率提取的特征在不同的分支中进一步处理并融合以产生最终结果。 所提出的“atrous spatial pyramid pooling”(DeepLab-ASPP)方法概括了我们的DeepLab-LargeFOV变量.
Structured Prediction with Fully-Connected Condi- tional Random Fields for Accurate Boundary Recovery

然而,顶层节点的增加的方差和大的感受野只能产生平滑的响应。 如上图所示,DCNN的score map可以预测对象的存在和粗略位置,但不能真正划定其边界。
论文提出了在耦合DCNN的识别能力和完全连接的CRF的细粒度定位精度的基础上,寻求一种替代方向,并表明在解决区域化挑战,产生准确的语义分割结果和恢复物体边界 详细程度远远超出现有方法的范围。
To overcome these limitations of short-range CRFs, weintegrate into our system the fully connected CRF model of[22]. The model employs the energy function
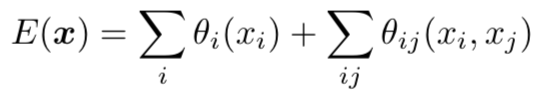
where x is the label assignment for pixels. We use as unarypotential θi(xi) = − log P (xi), where P (xi) is the labelassignment probability at pixel i as computed by a DCNN.
The pairwise potential has a form that allows for efficientinference while using a fully-connected graph, i.e. whenconnecting all pairs of image pixels, i,j. In particular, asin [22], we use the following expression:
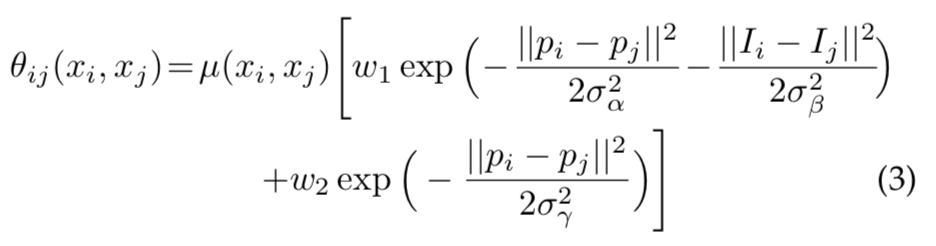
where μ(xi , xj ) = 1 if xi ̸= xj , and zero otherwise, which,as in the Potts model, means that only nodes with dis-tinct labels are penalized. The remaining expression usestwo Gaussian kernels in different feature spaces; the first,‘bilateral’ kernel depends on both pixel positions (denotedas p) and RGB color (denoted as I), and the second kernelonly depends on pixel positions. The hyper parameters σα,σβ and σγ control the scale of Gaussian kernels. The firstkernel forces pixels with similar color and position to havesimilar labels, while the second kernel only considers spatialproximity when enforcing smoothness.
实验结果:

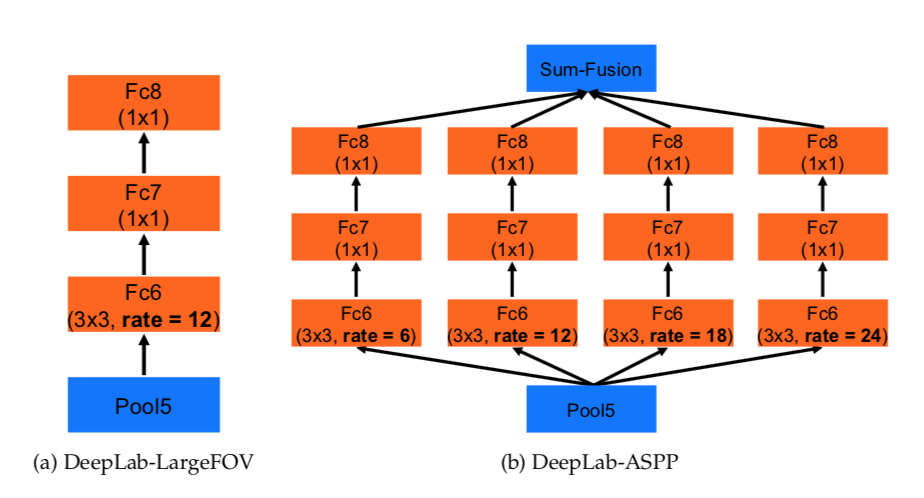
DeepLab-ASPP采用不同速率的多个过滤器来捕捉多个尺度的对象和上下文。
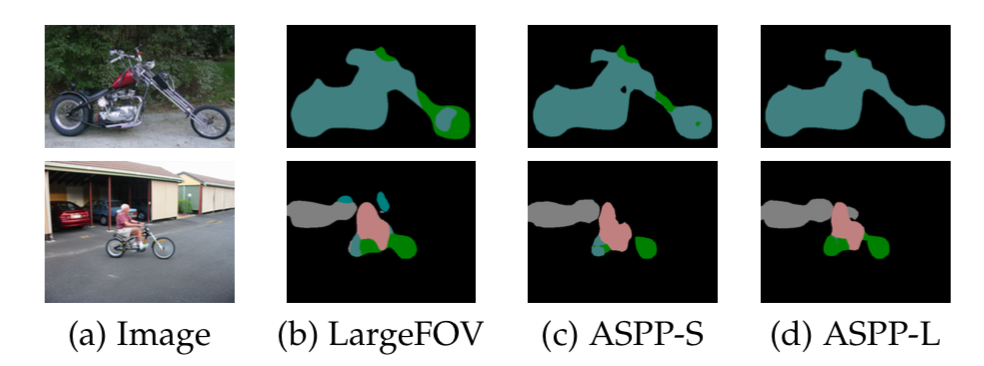
与基线LargeFOV模型相比,ASPP的定性分割结果。 采用多个FOVs的ASPP-L模型可以成功地在多个尺度上捕获对象以及图像上下文。
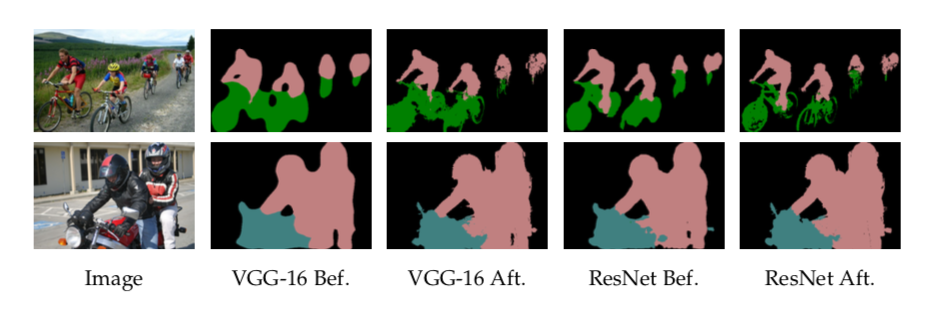
在CRF之前和之后,基于VGG-16网络或ResNet-101的DeepLab结果。 CRF对于准确预测沿着VGG-16的物体边界是至关重要的,而ResNet-101甚至在CRF之前还有可以接受的性能。
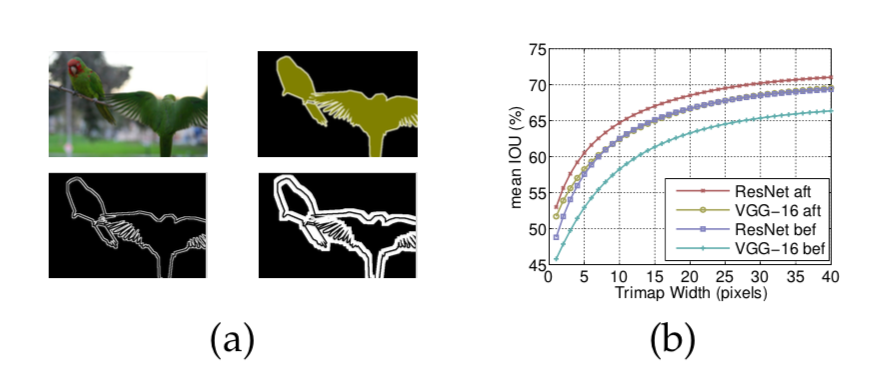
(a)Trimap示例(左上:图像,右上:ground-truth,左下:2像素的trimap,右下:10像素的trimap)。 (b)当在CRF之前和之后使用VGG-16或ResNet-101时,作为围绕物体边界的带宽的函数的像素平均IOU。

也有失败的:
















 7099
7099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









