







最近笔者在用Python对字符串进行简单的异或运算加密时遇到一个问题:字符串转为字节类型后,长度比原先的字符串长了一倍。怎样才能将转换后的字节长度保持与原字符串长度相同?
举个简单的加密例子:
origin = 'I Love PY Coding'
# key是参与异或运算的密钥
key = 100
enc_str = ''
for i in origin:
# 对原字符串逐个字符异或运算
enc_str += chr (ord(i) ^ key)
enc_byte = bytes (enc_str, 'utf-8')
print ('原字符串长度:', len(origin))
print ('加密后的字符串:', enc_str)
print (f'转换字节为:{str(enc_byte)}\n长度:{len(enc_byte)}')运行结果如下图:

看起来没毛病,是吧?
但是,当key值大于等于128、小于等于255时,加密的字节却长了一倍。
比如我随便把key值改为129:
key = 129运行结果:
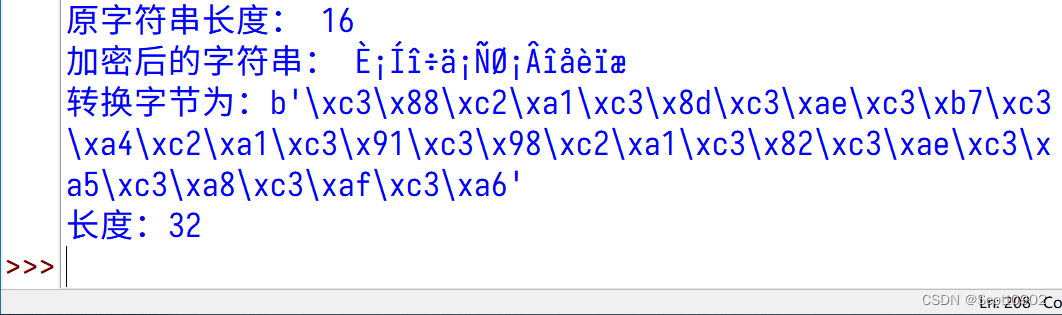
为什么此时转了字节后的长度大了一倍?如果要将转换后的结果写入二进制文件,文件尺寸翻倍,这不是我期待的结果。我猜想大概是bytes转换时加了设定 utf-8 编码导致。如果不用 utf-8 编码,改用 gbk 编码如何?结果却报错了,我又把 gbk 编码改为 ansi、ascii,结果同样出错。对于ASCII值在127~255范围内的字符串确实只能用 utf-8 编码才不会报错:

笔者仔细查阅了Python的字符串与字节转换的相关文章再作调试。
若要保持与原字符串长度一致,正确的姿势是先把加密后的各个字符保存为列表,再作bytes转换,需要注意的是,对列表进行转换bytes是不需要指定encoding编码的。代码修正如下:
origin = 'I Love PY Coding'
# key是参与异或运算的密钥
key = 129
enc_str = []
for i in origin:
# 对原字符串逐个字符异或运算,这次先保存字符ASCII值为列表
enc_str.append (ord(i) ^ key)
# 然后将列表进行bytes转换
# 注意此时不需要指定encoding了
enc_byte = bytes (enc_str)
print ('原字符串长度:', len(origin))
print ('加密后的字符串:', enc_str)
print (f'转换字节为:{str(enc_byte)}\n长度:{len(enc_byte)}')















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









