






为了了解文生图模型中的图文一致,借助AI工具搜集了一些资料和论文,对评价图文一致的相关指标内容做了一些简单的了解。在这里记录一下学习成果。
序
对于这里说到的图文一致性,主要是考虑图像内容和文本内容的语义一致性,也就是在人类视角下认为的图像内容和文本内容的匹配程度。一致性越高说明当人类看到图像后会联想到对应的文本内容的可能性越大。具体来说就是看山是山,看水是水。
计算机视觉领域的目标识别我认为可以被视为最早的图文匹配。在目标识别中最常见的方法是获取一个已经标注好的数据集,如机器学习中常见的手写数字数据集,猫狗数据集等。在获得数据集后我们可以建立一个分类器,先通过卷积等方式处理后提取图像的特征,对特征进行表示后再与对应标签一同送入分类器习得特征和标签之间的关系。这一过程中标签一般是一个单词,可以看做简单的文本,送入图像进行分类得到的预测概率就可以看作是“图像与对应标签之间的一致概率”。而随着技术的不断发展,加之近年来文生图模型的兴起,图文一致指标更是成为了文生图模型性能优劣的一项重要指标。下面我们将从几篇论文来简单梳理一下图文一致指标的发展过程。
大致的发展脉络
第一阶段:早期探索与基础方法(约2016 - 2020早期)
这一时期模型能力有限(如AttnGAN, DM-GAN),评估方法相对基础粗糙,侧重于判断图像是否“大致相关”,而非精细的一致性。
第二阶段:CLIP范式主导与精细化(约2020中期 – 2022)
CLIP模型的横空出世为图文跨模态表示学习带来了革命,也迅速成为了图文一致性评估的核心工具。
第三阶段:大模型时代与新范式(约2022下半年 – 现在)
大模型(如DALL-E 2, Imagen, Stable Diffusion, Midjourney)生成能力极强,细节丰富。传统指标的局限性愈发明显。新的评估范式涌现,强调细粒度对齐检测、人类偏好和利用强大AI模型作为评委
由于第一阶段的内容受限于当时的技术发展,后续的研究对这些方法就很少再有改进,因此我们主要以第二阶段开始详细的看一些现有的方法。
综述
首先介绍一篇与文生图模型相关的图文评估指标综述文章
论文题目:A Survey on Quality Metrics for Text-to-Image Generation
论文地址:[2403.11821] A Survey on Quality Metrics for Text-to-Image Generation
这篇综述文章,比较了2015-2024年的T2I评估指标,根据指标的考量内容进行了分类。主要分为两大类,一类是只根据图像内容和质量的评测指标,另一类为根据图像和文本两个内容的评价指标。
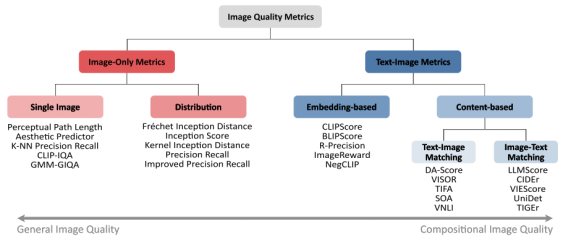
1.分类方法与评测指标
分类(第2小节)
| 图像质量指标 | 仅图像指标 | 单图像 | 只分析图像的结构和语义组成 | |
| 分布指标 | 比较生成图像与真实图像的分布 | |||
| 图文对指标 | 基于编码 | 计算文本编码和图像编码的嵌入向量距离 | ||
| 基于文本 | 文图匹配 | 根据提示中的关系询问问答模型检测图像内容是否符合 | ||
| 图文匹配 | 从图像出发,获取图像的描述,与文本进行匹配 |
不同方法下的评测度量指标(主流且具有代表性)
| 图文对指标评测度量 | 基于编码 | CLIPScore | 基于对比图像预训练(CLIP)。通过文本嵌入向量与图像嵌入向量之间的余弦相似度计算CLIP距离。 | CLIP只能获得提示与图像的整体语义,是一种无参考的指标。 后续有各种改进版本如RefCLIPScore有参考版本 | |
| BLIPScore | BLIP采用图像-文本对比学习(ITC)来生成用于计算余弦相似度的嵌入向量,而其图像-文本匹配(ITM)变体则专注于图像-文本对的二进制分类。 | 引入了多模态编码器,相较于CLIP的分别获得特征,BLIP利用transformer网络处理多模态的图像文本数据。随着着大模型的出现,2023年,BLIP 2作为一种高效的视觉语言预训练方法被引入,该方法利用预训练的图像编码器和具有较少可训练参数的大型语言模型(LLM),实现了从图像生成文本的新基准和先进的零样本能力。 | |||
| 其他 | MosaiCLIP(图分解) LXMERT(引入额外的Transformer模型来学习跨模态编码) CLIPR-Precision(计算图片与所给文本的相似度) Mutual Information Divergence (MID)(通过真实的和生成的样本之间的负高斯交叉互信息计算) DreamSim(用图像三元组,一张参考两张生成,由人工标注数据集,学习人类偏好) DreamBooth(使用CLIP [27]和DINO [83]的余弦相似性将生成的图像与相同视图的地面实况图像进行比较。因此,基于CLIP的度量仅要求图像显示相同的主题以返回高相似性,而基于DINO的度量被包括以测量更细粒度的差异。) | ||||
| 基于内容的评测度量 | 文图匹配(不需要将图像投影到嵌入空间) | Decompositional-Alignment Score (DA-Score) | 通过分解文本提示为多个独立的断言,并利用视觉问答模型分别评估每个断言的准确性。 | ||
| Semantic Object Alignment (SOA) | 利用预训练的目标检测模型评估图像中是否包含文本提示中提到的对象。 | ||||
| Text-Image Alignment Metric (TIAM) | 利用预训练的分割模型评估图像与提示之间的对齐情况,提示使用模板增强的词标签和可选属性。 | ||||
| VISOR | 通过预训练的目标检测器检测文本提示中提到的对象,并根据检测到的边界框的中心点推导出空间关系。 | ||||
| Positional Alignment (PA) and Counting Alignment (CA) | 分别评估生成图像与文本中位置细节和计数细节的一致性。 | ||||
| TIFA | 利用GPT-3通过上下文学习生成多项选择问答对,并应用多任务问答模型进行验证。 | ||||
| LLMScore | 利用LLM进行图像描述,然后结合局部推理和全局推理来评估生成的图像。 | ||||
| 其他 |
VIEScore:基于LLM的手工制作提示模板,分别计算感知质量和语义一致性得分。 Visual Concept Evaluation (ViCE):利用GPT-3.5-turbo从提示中形成问答对,并利用BLIP2-based VQA模型根据这些问答对评估图像。 VQAScore:细化输入到VQA模型的问题格式,并使用预训练的双向编码器-解码器语言模型和CLIP视觉编码器来预测答案可能性。 | ||||
| 图文匹配 | SPICE metric (Semantic Propositional Image Cap- tion Evaluation) | 将生成的句子和参考句子转换为对象,属性和关系的场景图,并使用Fscore进行比较,来评估为图像标题生成的文本的语义细节。 | |||
| LEIC metric (Learning to Evaluate Image Captioning) | 利用CNN进行图像编码,利用LSTM进行文本编码,利用二进制分类器将生成的文本质量与人类判断进行比较,可能比传统指标更接近人类评估。 | ||||
| TIGEr (Text-to-Image Grounding for Image Caption Evaluation) | 通过整合文本图像基础来考虑图像内容来改进评估,比基于单词的指标(如BLEU,ROUGE和METEOR)更好地与人类判断保持一致。 | ||||
| 其他 | ViLBERTScore:通过将对象检测器应用于目标图像并将图像区域特征和文本嵌入对馈送到预训练的ViLBERT模型来计算上下文嵌入。最后,ViLBERTScore由参考字幕嵌入和候选字幕嵌入之间的余弦相似度定义。 | ||||
| 仅图像指标评测度量 | 比较生成图像分布 | nception Score (IS) | 使用预训练的Inception网络比较生成样本的类别预测,奖励类别预测的低熵和边际类别分布的高熵。 | ||
| Fréchet Inception Distance (FID) | 比较生成和目标分布的特征均值和协方差,使用Inception网络提取特征。 | ||||
| Kernel Inception Distance (KID) | 计算Inception表示的平方最大均值差异,以解决FID的样本大小偏差问题。 | ||||
| Improved Precision and Recall (I-PRD) | 通过建模支持流形来直接计算精确度和召回度。 | ||||
| 评估单个图像质量 | Aesthetic Predictor | 预测人类对生成图像的美学评分,基于LAION Aesthetic数据集训练。 | |||
| PAL4VAST | 用于评估图像中的感知伪影,训练二元分割模型自动检测图像中的伪影。 | ||||
| Perceptual Artifact Ratio (PAR) | 也称为PAL4InPainting,用于评估图像中伪影的相对面积。 | ||||
2.常用数据集
图像描述数据集(Image Caption Datasets)
这些数据集包含图像及其对应的文本描述,通常用于训练和评估图像描述模型。它们为T2I生成模型的评估提供了基础,因为这些数据集中的图像和描述可以用来测试模型生成图像与文本提示的一致性。
SBU Captioned Photo Dataset:包含1百万张从Flickr.com收集的图像,每张图像都配有文本描述。
Conceptual Captions:通过网络爬虫收集的超过300万图像-文本对,经过严格过滤以确保高质量。
COCO Captions:基于MS COCO数据集,提供了164,062张图像的1,026,459个描述。
nocaps :包含超过600个对象类别的图像,用于评估模型在新对象上的表现。
视觉问答数据集(Visual Question Answering Datasets)
这些数据集包含图像、问题和答案的组合,用于评估模型对图像内容的理解能力。它们在评估T2I生成模型时,可以用来测试模型生成的图像是否能够合理地回答与文本提示相关的问题。
VQA:包含超过760,000个问题和10,000,000个答案,用于评估模型的视觉问答能力。
VQAv2.0:VQA的增强版,通过添加互补图像对来提高模型对视觉提示的关注度。
VCR:专注于评估模型的认知级视觉理解能力,包含复杂的问答对。
组合性基准数据集(Compositionality Benchmarks)
这些数据集专注于评估模型对复杂文本提示的理解和生成能力,即所谓的组合性。它们通常包含需要模型理解多个对象及其关系的提示。
Winoground:包含800个图像-文本对,用于评估模型在视觉语言组合推理方面的表现。
Visual Genome:包含超过108k张图像,每张图像平均有35个对象,用于全面的场景理解。
T2I-CompBench:包含6,000个文本-图像对,用于研究图像生成模型的属性绑定、对象关系和复杂组合技能。
其他特定用途的数据集
Pinterest40M:包含超过40 million张图像和300 million个句子,用于探索视觉-语言预训练方法。
ABC-6K 和 CC-500:用于评估属性绑定和概念组合的数据集。
I2P:包含4,703个提示,用于评估模型生成不适当图像的情况。
数据集特点和适用场景分析
规模和多样性:如Pinterest40M和Conceptual Captions等数据集,提供了大规模的图像-文本对,适合用于预训练模型以捕捉广泛的视觉和语言特征。
组合性和复杂性:像Winoground和T2I-CompBench这样的数据集,专注于评估模型处理复杂提示的能力,适合用于研究模型的组合性和语义理解能力。
特定任务评估:例如I2P数据集专注于评估模型生成不适当内容的倾向,适用于安全性和内容过滤的评估。
内容太长,具体的代表工作等后续再总结吧。
以上内容为作者本人观点,可能存在偏颇,欢迎批评指正。
创作不易,看到这里点个赞吧!^-^

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









