







a=10
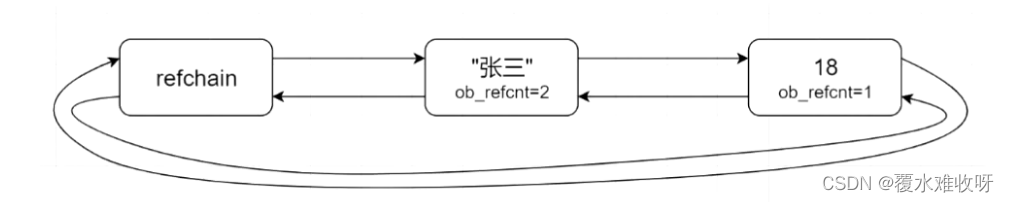
python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一个叫做refchain的双向循环链表中,每个数据都保存如下信息
- 链表中数据前后数据的指针
- 数据的类型
- 数据值
- 数据的引用计数
- 数据的长度(dict,list...)
一、引用计数机制
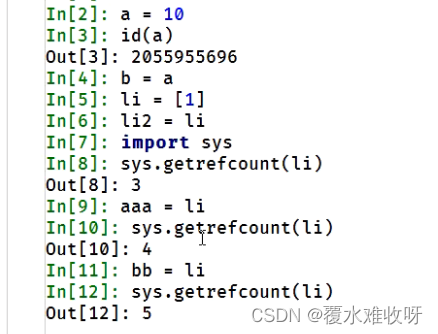
a=1, b=a,那这个时候引用计数就是2。
但是如果li=[1] ,li2 = li,sys.getrefcount(li),那这个时候[1]这个列表的引用计数机制就是3,为什么,因为第三次他是被当成参数传到一个函数里面,所以这个时候他的引用计数就是3
(1)引用计数增加
- 对象被创建
- 对象被别的变量引用(另外起了个名字)
- 对象被作为元素,放在容器中(比如被当做元素放在列表中)
- 对象被当成参数传递到函数中
(2)引用计数减少
-
对象的别名被显式的销毁
-
对象的一个别名被赋值给其他对象(例:比如原来a=10,被改成a=100,那么此时10的引用计数就减少了)
-
对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
- 一个引用离开了它的作用域(调用函数的时候传进去的参数,在函数运行结束后,该函数的引用即被销毁)
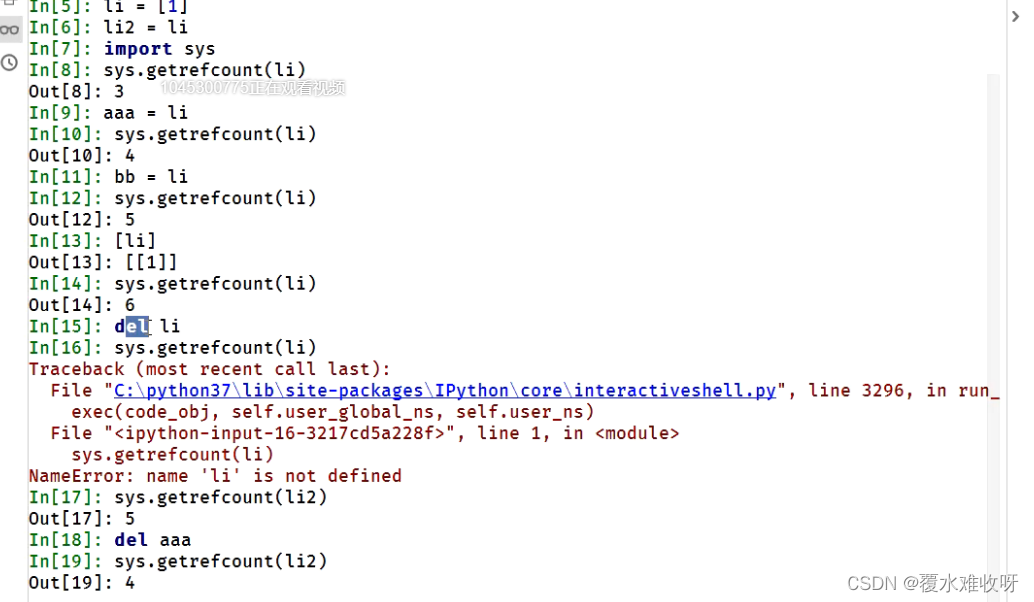
demo1:对象的别名被显式的销毁
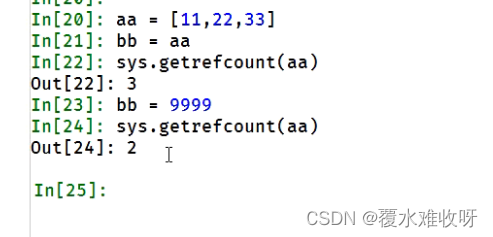
demo2:对象的一个别名被赋值给其他对象(例:比如原来a=10,被改成a=100,那么此时10的引用计数就减少了)
demo3:对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
a=[11,22]
b = [a,33]
b.pop(a)
(3)查看引用计数
import sys
sys.getrefcount(obj)二、数据池和缓存
(1)小整数池
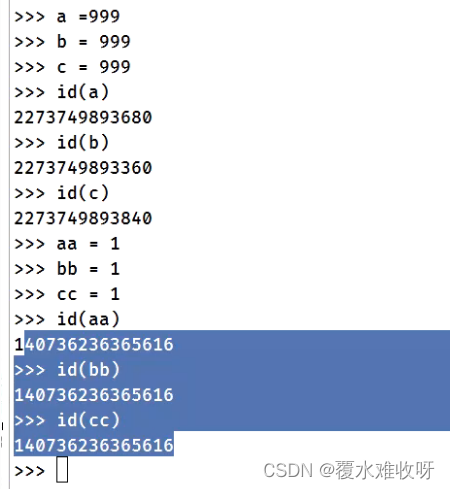
为什么a b c都指向的是999,但是内存地址确是不一样的?
为什么aa bb cc都指向的是1,那他们的内存地址却是一样的呢?
答: Python自动将-5~256的整数进行了缓存到一个小整数池中,当你将这些整数赋值给变量的时候,并不会重新创建对象,而是使用已经创建好的缓存对象,当删除这些数据的引用时,也不会进行回收。
(2)intern机制
intern机制, 也称为字符串驻留池,是针对于字符串内存管理的一种优化处理的机制。

intern机制的优点是,在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的值相同的对象(标识符,即只包含数字、字母、下划线的字符串),如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率。
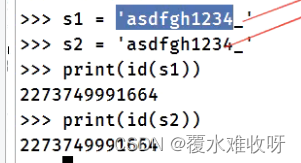
'123'为什么没有被销毁呢?因为他被加到字符串驻留池里面了。

(3)缓存机制
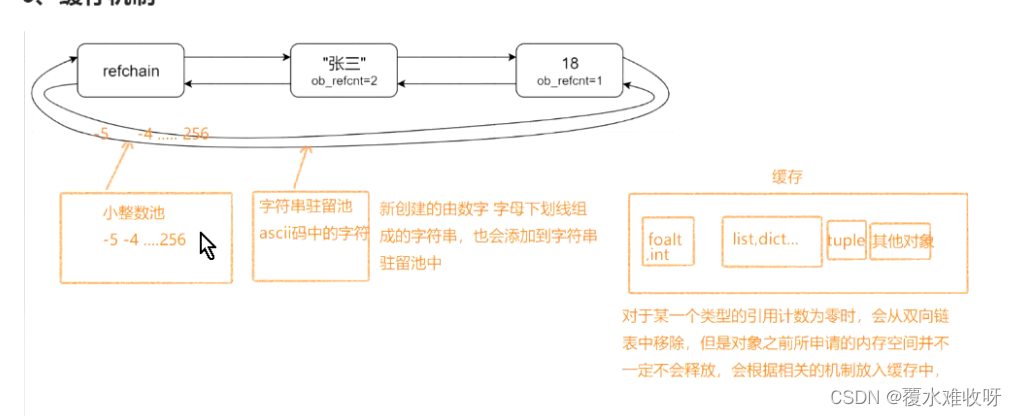
- float、int、list等一些内置的数据类型
- 元祖 会根据元祖数据的长度,分别缓存元祖长度为0-20的对象。
- 其他的类型缓存2个对象
为什么他们的缓存地址是一样的呢?
答:因为当你创建d1 d2的时候,他会去看你这个对象有没有缓存,没有的话就把这2个对象缓存起来,然后下一次你又重新创建了2个对象,他会先去判断你这2个对象有没有缓存,如果有缓存的话,就会去缓存里把原来对象拿出来,再把你的数据传进去,进行一个重新初始化。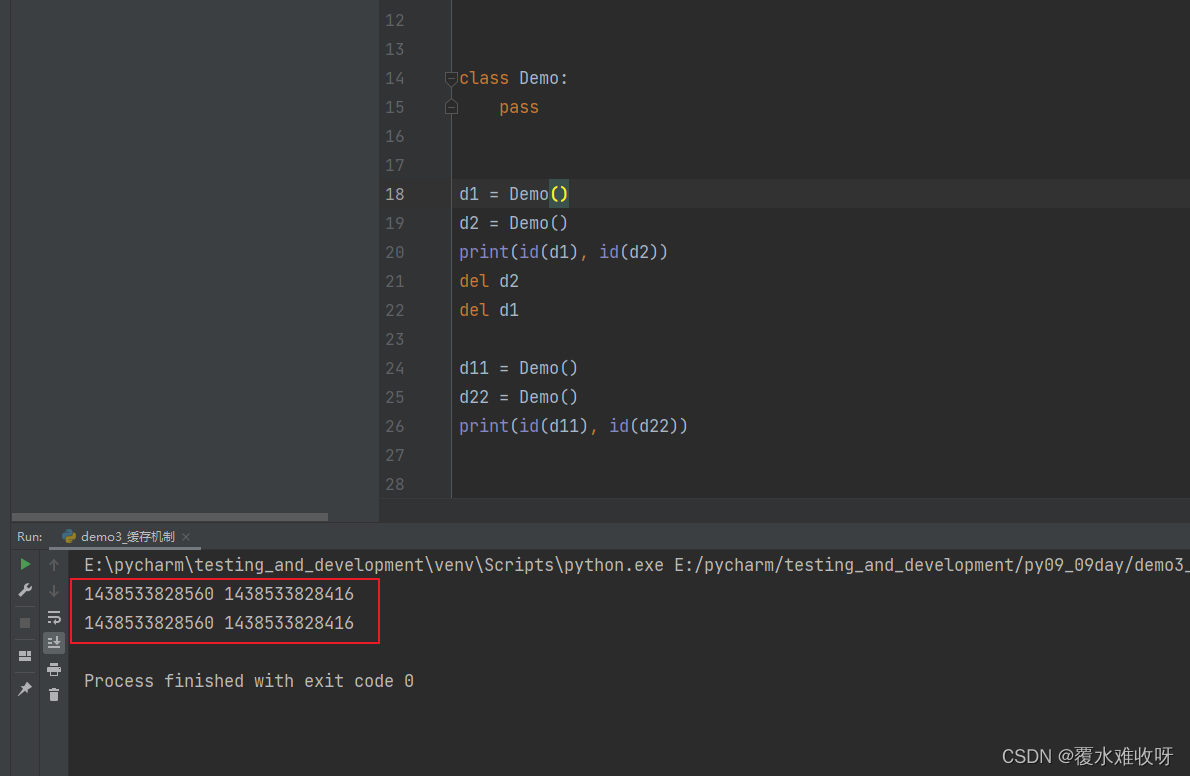
三、深浅拷贝

两个相同的列表,他们会不会是同一个对象?
深浅拷贝:只有在数据嵌套的情况下,才需要去考虑的问题
(1)没有数据嵌套的情况下不需要考虑深浅拷贝的问题
# 没有数据嵌套的情况下不需要考虑深浅拷贝的问题
li = [11, 22, 33]
li2 = li.copy()
print(id(li))
print(id(li2))
# 打印结果
2813111183040
2813111182656那这个时候我们往li里添加一个元素 44,对li2会有影响吗我们试一下。不会有影响。
li = [11, 22, 33]
li2 = li.copy()
print(id(li))
print(id(li2))
li.append(111)
print('li:', li)
print('li2:', li2)
print(id(li))
print(id(li2))
# 打印结果
1472955557568
1472955557184
li: [11, 22, 33, 111]
li2: [11, 22, 33]
1472955557568
1472955557184(2)我们看下数据嵌套的情况下
① 浅复制-----复制的数据引用
描述:拷贝父对象,不会拷贝对象的内部的子对象。
# ----------浅复制:复制的数据引用--------------------
a = [1, 2, 3]
li = [11, 22, a]
li2 = li.copy()
print(li, id(li))
print(li2, id(li2))
# 打印结果
[11, 22, [1, 2, 3]] 2221095920896
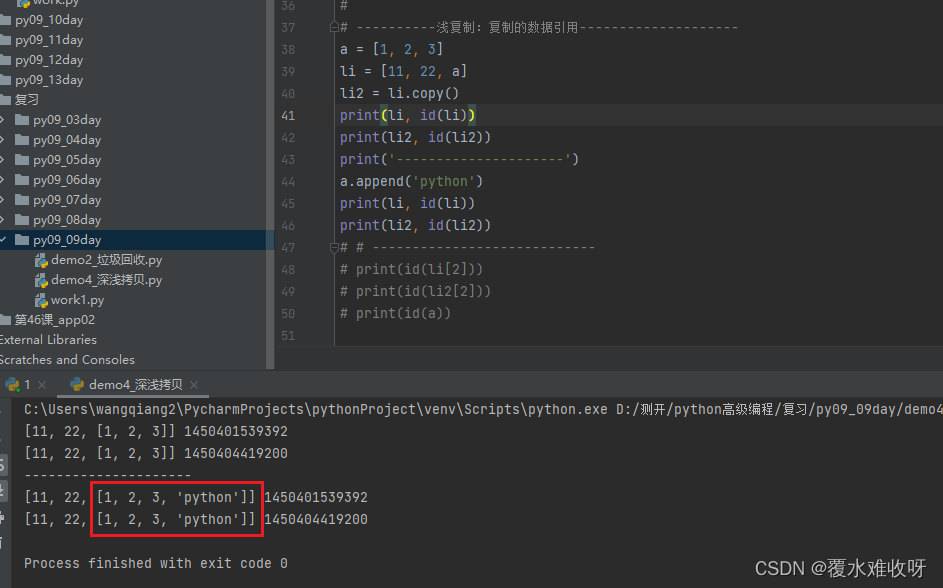
[11, 22, [1, 2, 3]] 2221098804480我们这个时候往li里添加一个元素看看有没有影响?答:没有任何影响。
# ----------浅复制:复制的数据引用--------------------
a = [1, 2, 3]
li = [11, 22, a]
li2 = li.copy()
li.append(999)
print(li, id(li))
print(li2, id(li2))
# 打印结果
[11, 22, [1, 2, 3], 999] 1855386756352
[11, 22, [1, 2, 3]] 1855389636288
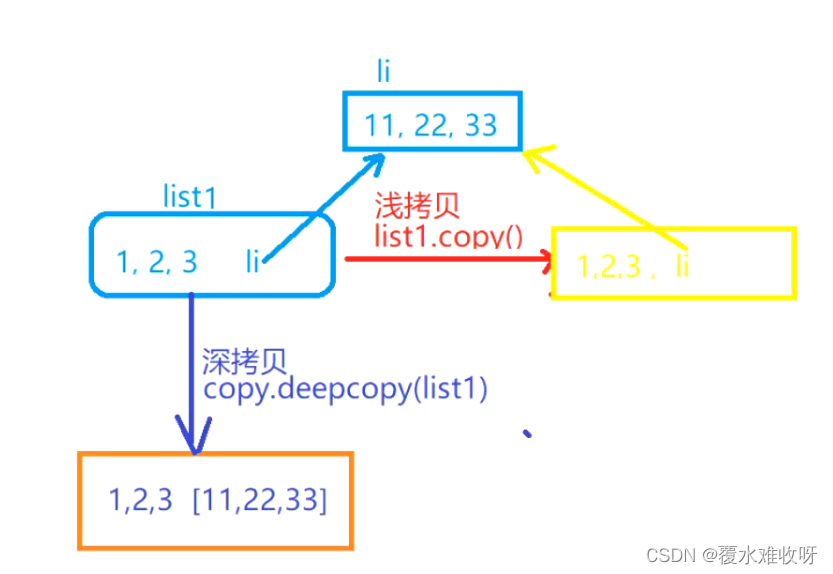
但是我如果修改 a的话,对Li2会有影响吗?答:会
为什么呢?我们把li和li2索引为2的、a的内存地址打印出来看下,发现他们是一样的。为什么呢?
因为:浅复制,复制的是数据引用。我们把引用的对象(引用的变量)复制过来了。
② 深复制(对数据中的值会重新创建一份)
描述:copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
很明显li[2]和li2[2]的内存地址不一样了,因为他对a的值重新创建了一份。
# ----------深复制:对数据中的值会重新创建一份--------------------
import copy
a = [1, 2, 3]
li = [11, 22, a]
li2 = copy.deepcopy(li)
print(id(a))
print(id(li[2]))
print(id(li2[2]))
# 打印结果
1779520501568
1779520501568
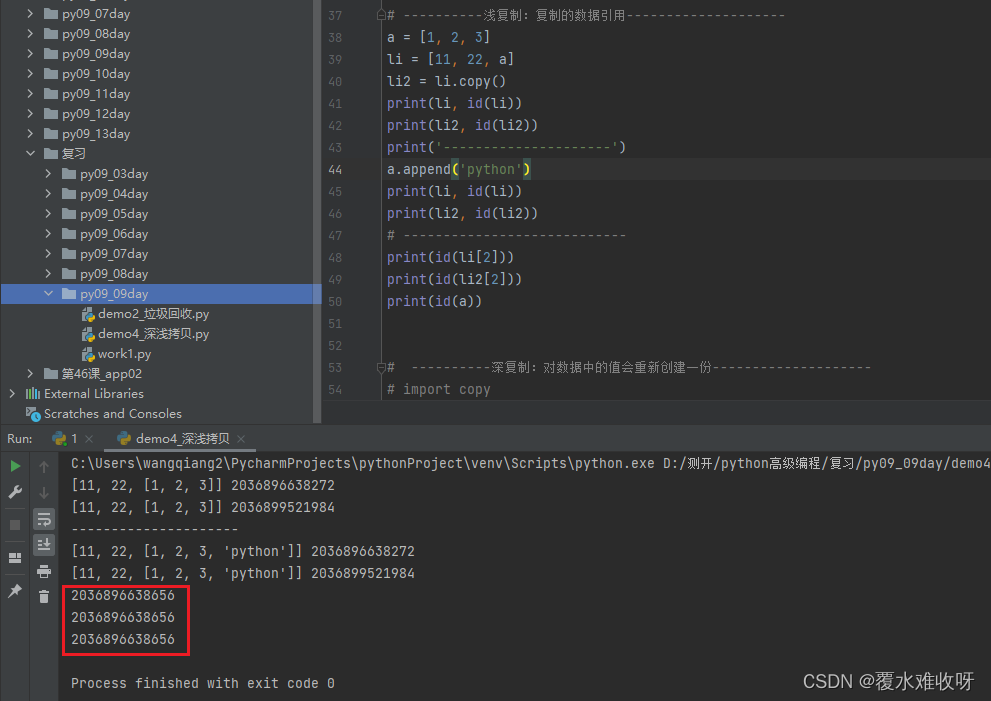
1779523000256这个时候我去修改一下a,那么我们看下对li和 li2哪个有影响。
import copy
a = [1, 2, 3]
li = [11, 22, a]
li2 = copy.deepcopy(li)
print(id(a))
print(id(li[2]))
print(id(li2[2]))
a.pop()
print('-----------')
print(li)
print(li2)
# 打印结果
1840960763712
1840960763712
1840963262528
-----------
[11, 22, [1, 2]]
[11, 22, [1, 2, 3]]
四、垃圾回收机制
(1)引用计数
之前讲对象的引用我们讲到了,每个对象创建之后都有一个引用计数,当引用计数为0的时候,那么此时的辣鸡回收机制会自动把它销毁,回收内存空间。
弊端:引用计数存在一个缺点:那就是当两个对象出现循环引用的时候,那么这个2个变量始终不会被销毁,这样子就会导致内存泄漏。
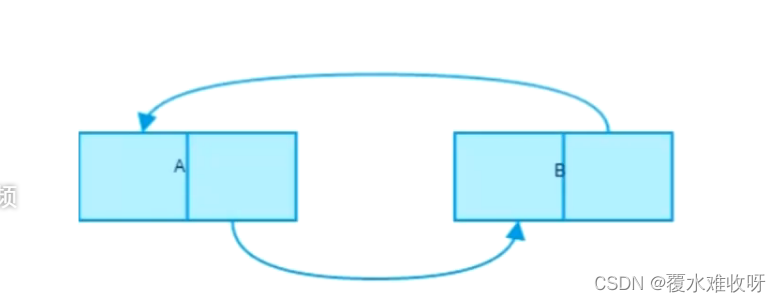
a = [11]
b = [1]
a.append(b)
b.append(a)
print(a)
# 打印结果 当两个对象出现循环引用的时候,那么这个2个变量始终不会被销毁,这样子就会导致内存泄漏。
[11, [1, [...]]](2)标记清除
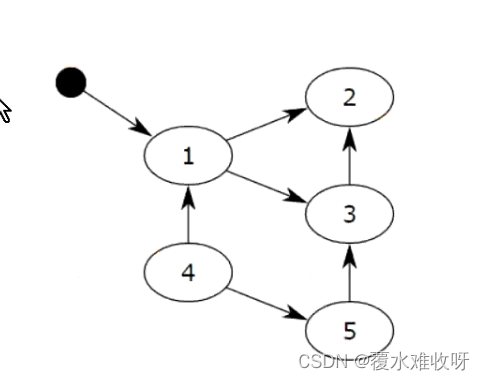
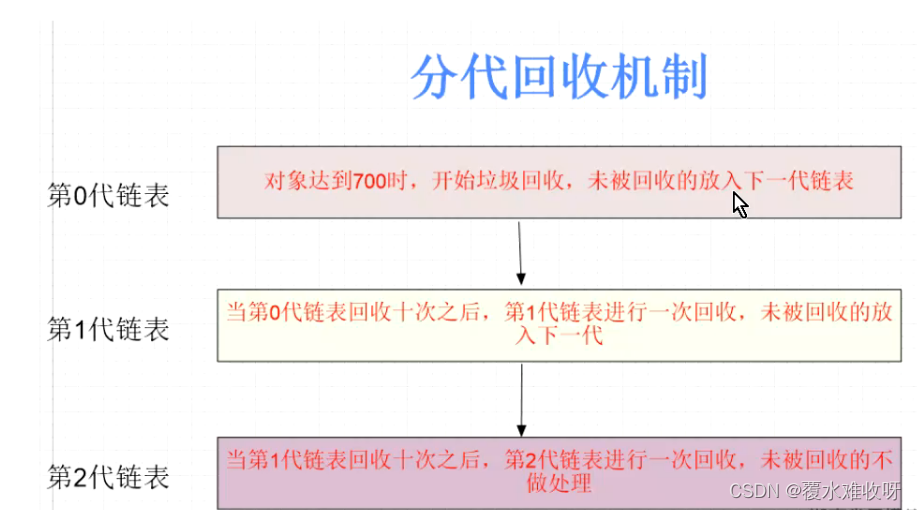
(3)分代回收
对于所有有可能会被循环引用的数据,会创建第0代链表,放在里面。那么这个数据什么时候被抹除掉?先看有没有引用计数为0的,为0的就先抹除掉。如果有全局变量引用了这个对象,那我就标识一下(你是活的,你有用),然后看里面有没有引用其他数据,然后再标记一下(这是活得,有用),如果数据没有被全局变量直接引用或者间接引用它的话,那就会标记为死的。标记完了之后,没有被标记到的或者标记为死的,就直接进行垃圾回收。
我们来直接举个栗子吧。
11, 22 有引用,所以我们删除a,删除b, 他们不会被释放。因为他们有全局变量引用或者其他的引用。
















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









