







参考:https://cs231n.github.io/convolutional-networks/
目录
一 基本概念
卷积神经网络(Convolutional Neural Networks)与普通神经网络非常相似,它们都是由神经元组成,拥有可学习的权重(weights)和偏置(biases)。每个神经元接收多个输入,通过点成和非线性运算输出结果。
整个网络实现评分功能:从一端输入图片,另一端得到相应类别的概率。在最后一层网络(全连接层)依然包含损失函数(如SVM/Softmax),适用于普通神经网络的学习方法依然实用于卷积神经网络。
1.1 普通神经网络
普通神经网络输入一个矢量(single vector),并通过一系列隐藏层。每一个隐含层均有大量神经元组成,每一个神经元都与前一层所有的神经元相连,并且每一层的神经元之间完全独立,没有任何链接。最后一层网络,全连接层,也称“输出层”,在分类问题中中它代表每一类别的得分。下图为普通的3层神经网络。

普通的神经网络并不适合一张完整的图片,在数据集CIFAR-10中,图片的尺寸为 [ 32 ∗ 32 ∗ 3 ] [32*32*3] [32∗32∗3](32宽,32高,3颜色通道),所以一个普通神经网络的第一个隐藏层的神经元应该包含 32 ∗ 32 ∗ 3 = 3072 32*32*3=3072 32∗32∗3=3072个权重。虽然这些权重依然不算太多,但是这种全连接的结构根本不适合更大的图片。例如,一个更大的尺寸 [ 200 ∗ 200 ∗ 3 ] [200*200*3] [200∗200∗3],这将需要包含 200 ∗ 200 ∗ 3 = 120000 200*200*3=120000 200∗200∗3=120000个权重的神经元,而且,我们将需要很多这样的神经元。很明显,这种全连接结构是非常浪费的,如此巨大的参数量将会导致过度拟合。
1.2 卷积神经网络
与普通的神经网络不同,卷积神经网络的神经元包含三个维度:宽度、高度、深度(深度指activation volume,而不是网络的深度。)。例如,CIFAR-10中输入的图片维度为 [ 32 ∗ 32 ∗ 3 ] [32*32*3] [32∗32∗3](宽度,高度,深度)。每一层的神经元与后一层的小部分区域相连接。CIFAR-10的输出层的维度为 [ 1 ∗ 1 ∗ 10 ] [1*1*10] [1∗1∗10],因为在卷积神经网络的结尾,我们将整个图片变成一个向量,这个向量代表它是每一类的得分情况。
卷积神经网络的神经元由三个维度(宽度、高度、深度)组成。每一层都是由3维数据输入、3维数据输出。如下图,红色输入代表一张图片,所以它的宽、高代表图片的尺寸,深度为3(代表RGB三个颜色通道)。

二 卷积神经网络的层
通常,卷积神经网络包含三种层结构:卷积层(Convolutional Layer)、池化层(Pooling Layer)、全连接层(Fully-Connected Layer)。通过堆积这些层结构就能形成卷积神经网络结构。
举一个样例,对于CIFAR-10分类问题的卷积神经网络结构。
输入层(INPUT)-卷积层(CONV)-激活层(线性整流,RELU)-池化层(POOL)-全连接层(FC)
【神经网络】激活函数的作用及常用激活函数ReLu、Sigmoid
- 输入层(INPUT):输入的为 [ 32 ∗ 32 ∗ 3 ] [32*32*3] [32∗32∗3]的像素值,图像宽为32,高为32,带有RGB三个颜色通道。
- 卷积层(CONV):根据输入层输入计算输出,对权重和输入层的输出进行点乘运算。如果此处使用12个过滤器(filter),那将生成维度为 [ 32 ∗ 32 ∗ 12 ] [32*32*12] [32∗32∗12]的输出。
- 激活层:采用线性整流函数(RELU), m a x ( 0 , x ) max(0,x) max(0,x),这不会使输出的维度发生变化,依然是 [ 32 ∗ 32 ∗ 12 ] [32*32*12] [32∗32∗12]
- 池化层(POOL):将在空间维度上(宽度、高度)进行下采样,生成维度为 16 ∗ 16 ∗ 12 16*16*12 16∗16∗12的输出。
- 全连接层(FC):输出维度为 [ 1 ∗ 1 ∗ 10 ] [1*1*10] [1∗1∗10],这10个输出相当于每一类得得分,如CIFAR-10中的10类。正如名字所包含的含义,该层网络的神经元与前面网络的每一个神经元相连。
卷积神经网络通过一层层结构将原始图片像素值转换成各种类的得分。在这些层中,卷积层和全连接层包含参数,而激活层和池化层不包含参数,这些后面会有讲解
简短的总结卷积神经网络的特点:
- 卷积神经网络是由一系列简单的网络结构组成,将图片转换为输出。
- 它是由不同类型的层组成。(CONV、FC、RELU、POOL,这是比较常用的层)
- 每一层输入3维数据,输出3维数据。
- 每一层都包含/不包含参数。(CONV/FC包含,RELU/POOL不包含)
- 每一层都包含/不包含超参。(CONV/FC/POOL包含,RELU不包含)
参数(parameter):可以训练的参数,如权重,偏置。
超参(hyperparameter):不可以训练的参数,而是认为设定的值,如卷积核数量。(后面将详细介绍每一个参数)

这是一个卷积神经网络结构,第一列代表原始的图片像素,最后一列代表每一类的得分,其中car的得分最高。中间过程如中间这些列所示。
接下来分别详细的介绍每一层的超参、连接情况等详细信息。
2.1 卷积层
卷积层是卷积神经网络的核心,它所占的计算量非常巨大。
2.1.1 概述
首先不考虑含有神经元的计算过程,卷积层由一系列可以学习的过滤器(filter)组成。虽然每个过滤器占很小的空间(带有宽度和高度),但是它可以扩大输出的深度。例如,第一个卷积层中的过滤器的尺寸通常为 [ 5 ∗ 5 ∗ 3 ] [5*5*3] [5∗5∗3](5像素的宽和高,3个颜色通道)。在前向传播过程,我们在输入量的2维平面上滑动过滤器(卷积),并且计算各个位置上输入与整个过滤器的点乘。当我们在输入平面上滑动过滤器将产生二维激活图,该图会给出过滤器在每个空间位置的结果。过滤器在网络上不断地学习,当它看到某种类型的视觉特征时会被激活,例如第一层上的边缘或某颜色的斑点,或在更高层上出现整个蜂窝状或轮图案。
每个卷积层都含有许多过滤器,每一个过滤器都将产生一个不同的二维激活图,将这些二位激活图在深度方向进行堆叠即可得到输出。
下面将从下面几个方面介绍卷积层:局部连接(local connectivity)、空间排列(Spatial arrangement)、参数共享(Parameter Sharing)
2.1.2 局部连接
当面对高维输入时(如图片),每一个神经元与前一层神经元无法做到全连接。所以,只能将每个神经元只与前一层部分神经元相连。这种空间连接范围是一种被称为神经元感受域(receptive field)的超参(等同于过滤器的大小)。在深度方向连接的程度总是等于输入的深度。处理空间尺寸和深度尺寸是不对称的,空间(宽度和高度)的连接是局部的,但在深度上的处理是完整的。
例1. 假设输入维度为 [ 32 ∗ 32 ∗ 3 ] [32*32*3] [32∗32∗3],如果感受域大小为 [ 5 ∗ 5 ] [5*5] [5∗5],那么卷积层的每一个神经元的权重尺寸为 [ 5 ∗ 5 ∗ 3 ] [5*5*3] [5∗5∗3],总计 5 ∗ 5 ∗ 3 = 75 5*5*3=75 5∗5∗3=75个权重(再加上一个偏置参数,共76),延深度方向的连接参数是3,因为输入数据的深度为3。
例2. 假设输入维度为 [ 16 ∗ 16 ∗ 20 ] [16*16*20] [16∗16∗20],如果感受域大小为 [ 3 ∗ 3 ] [3*3] [3∗3],那么卷积层的每一个神经元需要 3 ∗ 3 ∗ 20 = 180 3*3*20=180 3∗3∗20=180个权重连接参数组成。局部空间连接的此次为 3 ∗ 3 3*3 3∗3,但深度为20。

红色代表输入层
(
32
∗
32
∗
3
)
(32*32*3)
(32∗32∗3),蓝色代表卷积层,卷积层内的神经元只与输入量部分区域相连。沿着深度方向有许多神经元(图中为5个),它们的输入均来自同一区域。

卷积神经网络的神经元与普通神经网络的神经元相同,将卷积的权重与输入做点乘,再进行非线性运算。(注意,此时每个神经元的连接只是在固定区域内)
2.1.3 空间排列
前面,我们讲了卷积层的神经元输入的连接,接下来我们讲讲神经元的输出情况。输出的情况由三个超参决定:深度(depth)、步长(stride)、零填充(zero-padding)。
- 深度(depth)
它的值等于过滤器的数量,每一次学习都试图寻找输入之间的不同。例如,第一个卷积层输入原始图片,不同深度的神经元根据不同的边缘或是颜色斑点产生作用。 - 步长(stride)
步长指过滤器滑动的步长,当步长为1时,过滤器一次移动1像素。当步长为2时,过滤器一次移动2像素。步长为2的输出要比步长为1的输出小。 - 零填充(zero-padding)
将0填充在输入的边缘时会让计算更加方便,之后将会讲解。零填充的值可以控制确保输入与输出大大小相同。
当输入尺寸为W,感受域大小(过滤器)为F,步长为S,零填充为P,输出尺寸大小的公式为: ( W − F + 2 P ) / S + 1 (W−F+2P)/S+1 (W−F+2P)/S+1
假设输入尺寸为 7 ∗ 7 7*7 7∗7,过滤器大小为 3 ∗ 3 3*3 3∗3,步长为1,填充为0,那么输出大小为5*5。因为 ( 7 − 3 + 2 ∗ 0 ) / 1 + 1 = 5 (7-3+2*0)/1+1=5 (7−3+2∗0)/1+1=5
当输入大小为5,过滤器大小为3,步长为1,为了使输出同样为5的话,那么零填充就要为1。如果零填充为0的话,那么输出只能是3了。所以通过设置零填充大小,可以控制输出的大小。
为方便理解,我们看一个简单一维案例,输入尺寸W=5,零填充P=1。
从左到右依次为图一、二、三:图一为步长S=1的情况,图二为步长S=2的情况,图三为感受域(过滤器),其大小 F=3。
当步长S=1时,如图一所示,其输出大小为
(
5
+
2
−
3
)
/
1
+
1
=
5
(5+2-3)/1+1=5
(5+2−3)/1+1=5。
当步长S=2时,如图二所示,其输出大小为
(
5
+
2
−
3
)
/
2
+
1
=
3
(5+2-3)/2+1=3
(5+2−3)/2+1=3。
当步长S=3时,将出现错误,因为它不适合这个尺寸。通过公式我们也可以发现,
(
5
−
3
+
2
)
=
4
(5-3+2)=4
(5−3+2)=4不能被3整除。
零填充的用途
如上个案例的图一所示,输入的维度为5,输出的维度同样也为5。这是因为感受域的大小为3,零填充的大小为1。如果零填充为0的话,输出的维度将变为3。通常情况,当步长S=1的情况下,设置零填充为
P
=
(
F
−
1
)
/
2
P=(F-1)/2
P=(F−1)/2以确保输入输出的维度相等。
步长的限制
空间排列的超参(S、F、P)之间相互约束。例如,等输入维度 W=10,零填充 P=0,过滤器尺寸 F=3,那么步长S不可能为3,因为
(
W
−
F
+
2
P
)
/
s
+
1
=
(
10
−
3
+
0
)
/
2
+
1
=
4.5
(W-F+2P)/s+1=(10-3+0)/2+1=4.5
(W−F+2P)/s+1=(10−3+0)/2+1=4.5,这不是整数,因此此时的超参设置是无效的。
实际案例参考
Krizhevsky等人在2012年的ImageNet挑战中采用[227x227x3]尺寸的图像。在第一层卷积层,神经元的感受域尺寸 F=11(准确说是11*11),步长 S=4,零填充 P=0。所以
(
227
−
11
)
/
4
+
1
=
55
(227-11)/4+1=55
(227−11)/4+1=55 ,因为卷积层的深度 K=96,所以卷积层的输出维度为
[
55
×
55
×
96
]
[55\times 55\times 96]
[55×55×96] 。此外,沿着深度的96列神经元都连接到相同的
[
11
×
11
×
3
]
[11\times11\times3]
[11×11×3]输出区域,但是带有不同的权重。顺便说一句,如果您阅读实际的论文,它声称输入图像是224x224,这肯定是不正确的,因为
(
224
−
11
)
/
4
+
1
(224-11)/ 4 +1
(224−11)/4+1显然不是整数。 在ConvNets历史上,这使许多人感到困惑。最佳猜测是,Alex使用了3个额外像素的零填充,这在他的论文中没有提到。
2.1.4 参数共享
在卷积层中使用参数共享方法来控制参数的数量。
举个例子,当第一个卷积层包含 [ 55 × 55 × 96 ] = 290 , 400 [55\times 55\times 96]=290,400 [55×55×96]=290,400 个神经元,并且每个神经元包含 [ 11 × 11 × 3 ] = 363 [11\times 11\times 3]=363 [11×11×3]=363 个权重和1个偏置,第一个卷积层的参数总计为 [ 55 × 55 × 96 × 363 ] = 105 , 705 , 600 [55\times 55\times 96\times 363]=105,705,600 [55×55×96×363]=105,705,600,可见,参数的数量十分巨大。
我们可以通过一个合理的假设以减少参数的数量:如果一个特征在某一空间位置(x,y)进行计算有用的话,那么它在另一位置(x2,y2)进行计算也应该有用。对于一个 [ 55 × 55 × 96 ] [55\times 55\times 96] [55×55×96],我们可以沿着深度方向进行切片,每一切片的尺寸均为 [ 55 × 55 ] [55\times 55] [55×55],对于每一切片上的神经元( [ 55 × 55 ] [55\times 55] [55×55]个)使用相同的权重和偏置。
依然采用上个案例,当使用参数共享的方法,每一层上相当于只使用一个神经元,96片共使用96个不同的神经元,共包含 [ 11 × 11 × 3 + 1 ] × 96 = 34 , 944 [11\times 11\times 3+1]\times 96=34,944 [11×11×3+1]×96=34,944个参数。
2.1.5 卷积层演示
卷积层的计算演示如下:
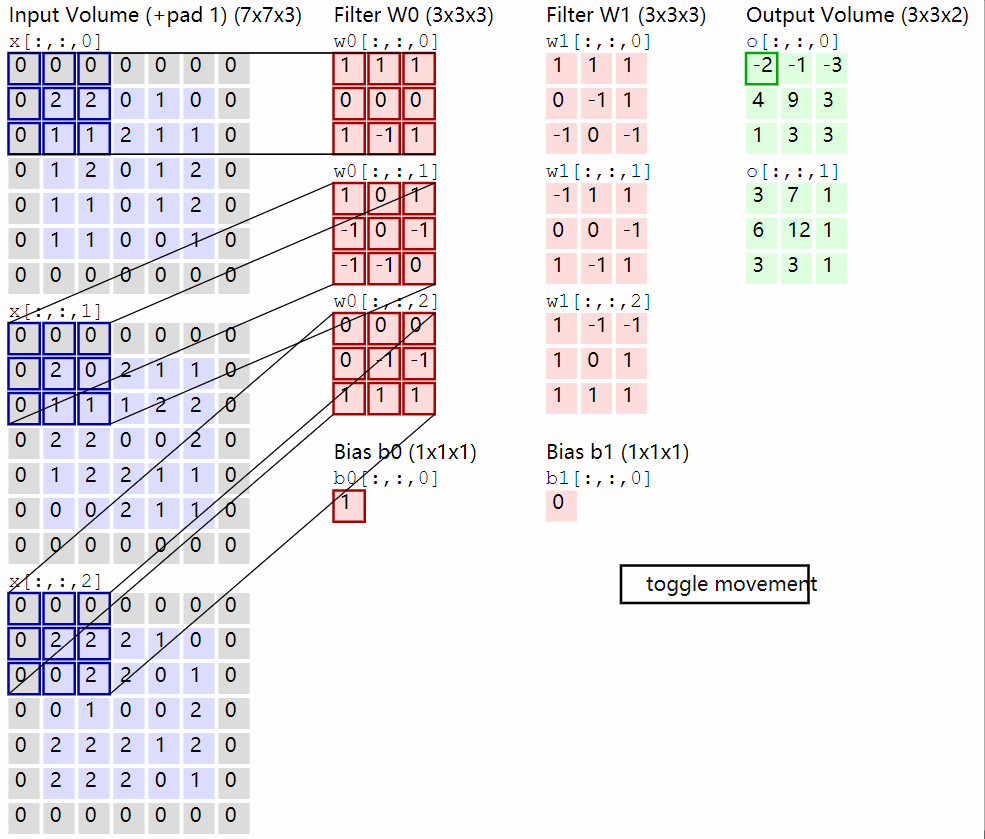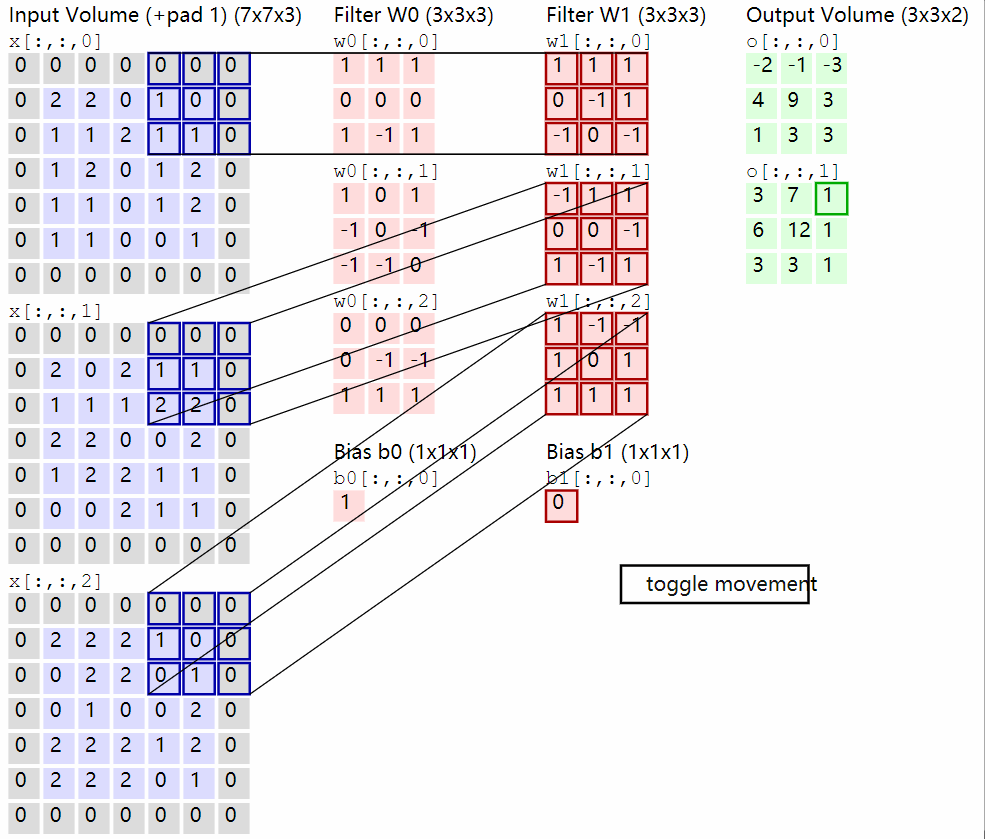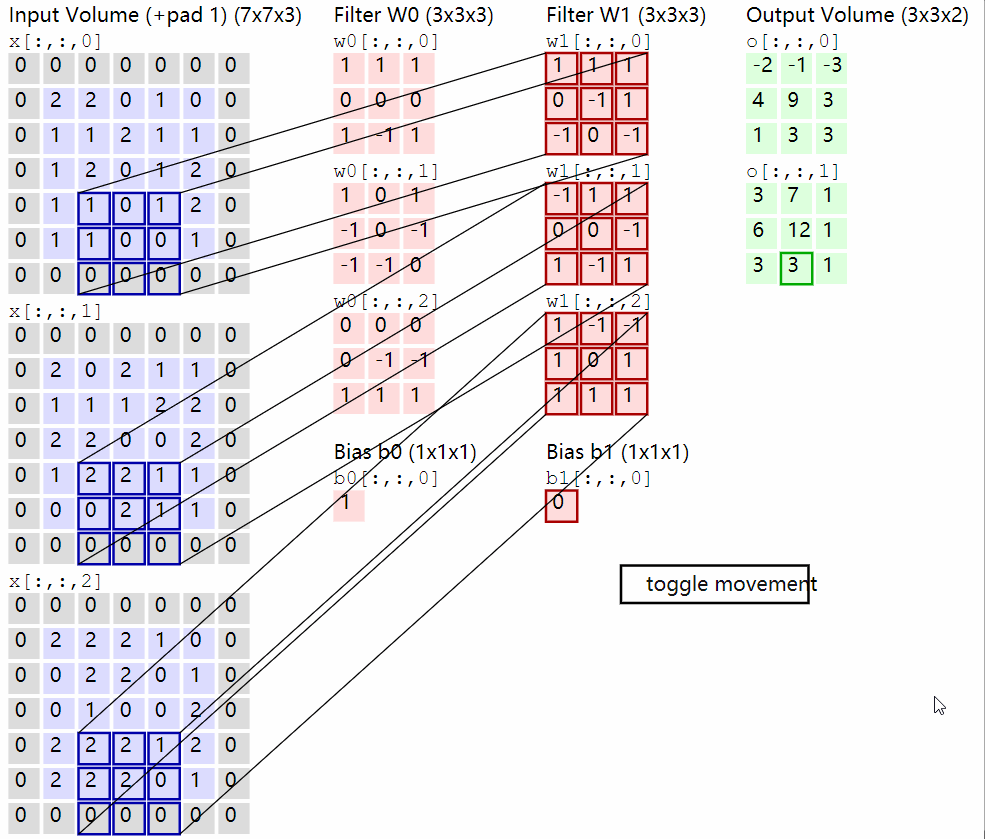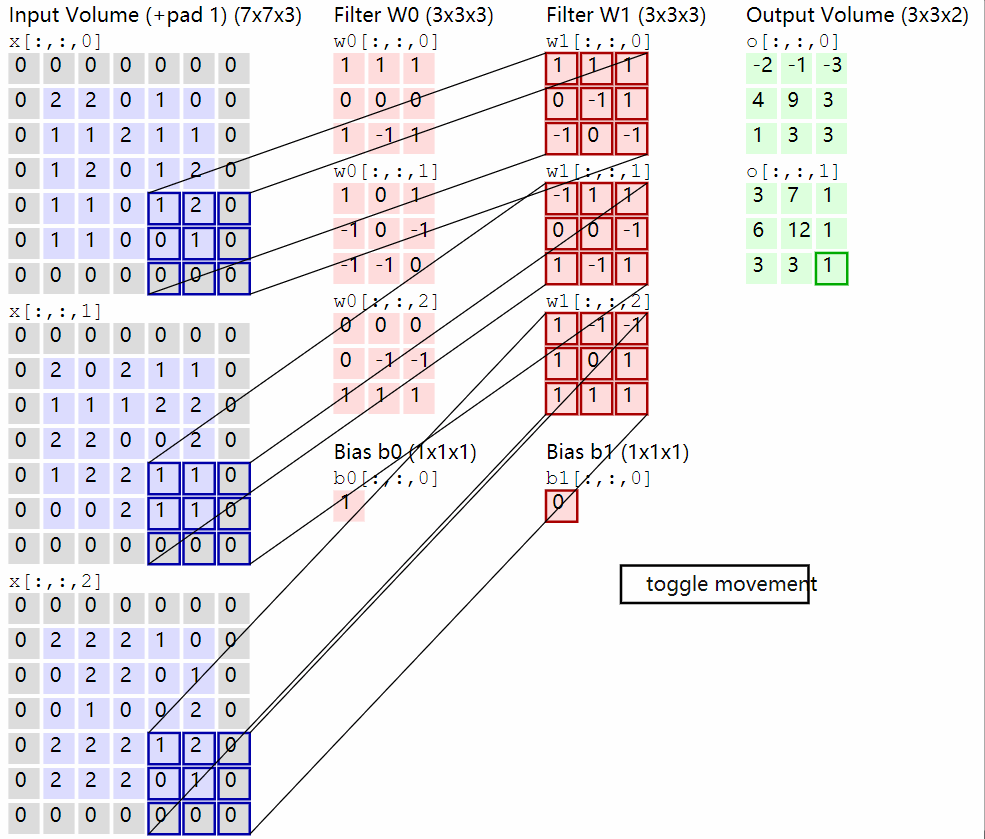
2.2 池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化层也曾下采样层,其具体操作与卷积层的操作基本相同,只不过池化层的卷积核为只取对应位置的最大值、平均值等,即矩阵之间的运算规律不一样,并且不经过反向传播的修改。
如图所示,经过池化层后,输入的维度减小1/2。

下图采用最大池化层(Maxpooling),取
[
2
×
2
]
[2\times 2]
[2×2]内最大的值以替代这
[
2
×
2
]
[2\times 2]
[2×2]区域内的值。

使用平均池化层时,则取取
[
2
×
2
]
[2\times 2]
[2×2]内平均值以替代这
[
2
×
2
]
[2\times 2]
[2×2]区域内的值。
















 5217
5217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











