






作者:石公星,雨润集团基础数据平台架构师
导读:数字化转型的浪潮中,高效准确的数据分析能够帮助雨润集团快速洞察市场动态、优化供应链管理、提高生产效率。雨润集团引入了 Apache Doris 构建了统一实时数据仓库,实现了计算效率提升 30 倍、存储资源节省 90%、成本降低超 100 万、人员效率提升 3 倍,为智能化、高效化转型指明了方向。
雨润控股集团是一家集食品、地产、商业、物流、旅游、金融和建筑等七大产业于一体的多元化企业集团,员工总数近 13 万人,下属子(分)公司 300 多家,遍布全国 30 个省直辖市和自治区。企业综合实力位列中国企业 500 强第 112 位,中国制造业 500 强第 39 位,中国民营企业 500 强第 8 位。目前,旗下拥有雨润食品、中央商场两家上市公司。雨润不仅是一个品牌,更是一种生活方式,涉及人民大众生活的方方面面:衣、食、住、行、娱乐等,雨润致力于民生产业,围绕人民大众的生活需求,生产好的产品,提供细致服务,用心创造各种可能。
作为国内知名的食品与农业综合性企业,在数字化转型的浪潮中,雨润集团深刻认识到,数据是企业成功的关键。企业不仅要建立数据驱动的文化,更需要以先进技术来增强数据处理和分析能力并建立完善的数据治理框架,以此帮助企业快速洞察市场动态、优化供应链管理、提高生产效率,以应对快速变化的市场环境并提升核心竞争力。
为此,雨润集团自 2022 年起启动了数据仓库升级项目,引入了 Apache Doris 分别对早期离线数据仓库及实时数仓全面升级改造,构建了统一实时数据仓库。相较于之前,带来了计算效率提升 30 倍、存储资源节省 90%、成本降低超 100 万、人员效率提升 3 倍的显著效益。 不仅强化了雨润集团自身的核心竞争力,更为智能化、高效化转型指明了方向。
业务需求
雨润集团业务数据主要源自生鲜数据、深加工数据和养殖数据这三部分,这些数据具体包括:
- 生鲜数据: 全国 25 家工厂,需记录每个工厂的屠宰信息、冻品信息、供应商信息以及销售信息。
- 深加工数据: 全国 17 家工厂,工厂将采购猪、牛、羊等生鲜产品,并将其加工成熟食进行销售,需记录工厂仓库信息、生产费用、采购费用及销售信息。
- 养殖数据: 全国 8 家养殖场,约养殖 7 万头猪,需记录每头猪的单据数据,包括饲料、产仔、哺乳、配种等信息。
为充分挖掘这些数据的潜在价值,雨润集团希望基于上述几类关键数据,重点提供以下几项数据服务:
- 离线报表: 每天定时产出 T+1 的 BI 报表,为管理者提供决策支持。管理者可依据报表数据检验销售目标是否达成,对市场占有率、库存周转率进行监控,预警冻品过期信息等。
- 实时分析: 对当日零售门店的经营数据进行分析,便于门店及时调整销售策略。
- 即席查询: 为数据分析师提供多维分析宽表,数据分析师可根据宽表生成自助式分析报表、构建数据门户。
早期数据架构
01 基于 Hive 的离线数仓
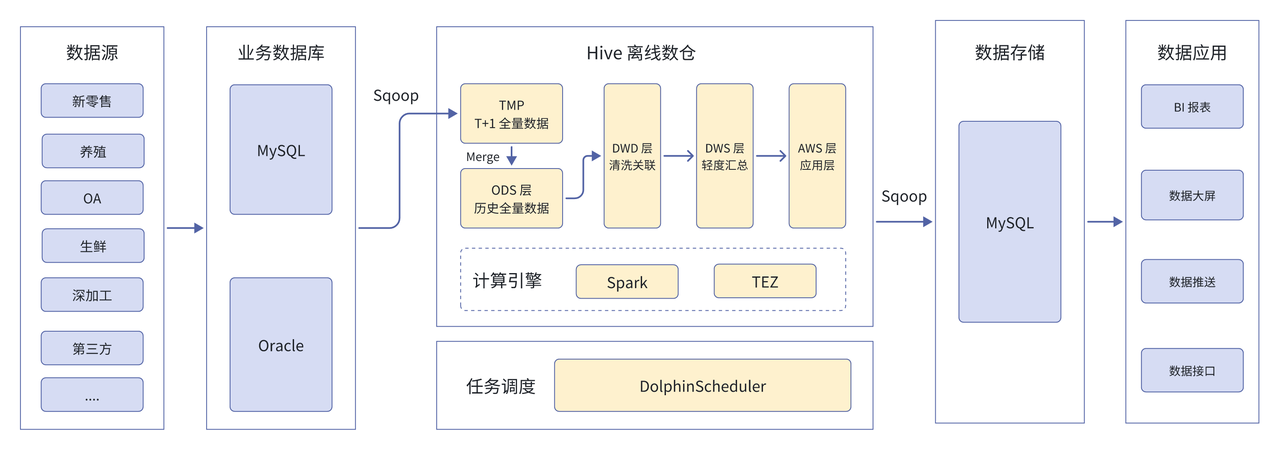
雨润集团的业务数据可细分为新零售(包括传统采购、销售、库存)、养殖数据、OA 数据(审批流程数据)、生鲜(采购的猪牛羊以及加工数据)、第三方数据(价格比对)等数据维度,均被存储在业务数据库 MySQL 和 Oracle 中,通过 Sqoop 将以上数据导入到 Hive 离线数仓中进行处理,为用户提供数据服务。具体来说:
- 在数据接入上: 首先,由 Sqoop 先将 T+1 全量数据导入 TMP 数据库进行临时存储;接着对数据进行 Merge 操作,将数据转移到 ODS 层(这样操作的原因是 Hive 没有主键,分区与不分区性能表现差异较大),进入 ODS 中的全量数据会按照 ODS、DWD、DWS、ADS 标准数仓分层依次进行处理。
- 在数据计算上:为应对多样化计算需求,该架构部署了 Spark 和 TEZ 这两个计算引擎。Spark 性能较好、主要应对大规模数据的计算任务;TEZ 则是为了缓解某些场景下内存占用资源特别多时造成的内存压力。
- 在数据应用服务上:经由 Spark 和 TEZ 处理完成的数据会再通过 Sqoop 从 Hive 中迁移到 MySQL 里,由 MySQL 向 BI 报表、数据大屏、数据推送等数据应用提供服务。
02 基于 HBase 的实时数仓
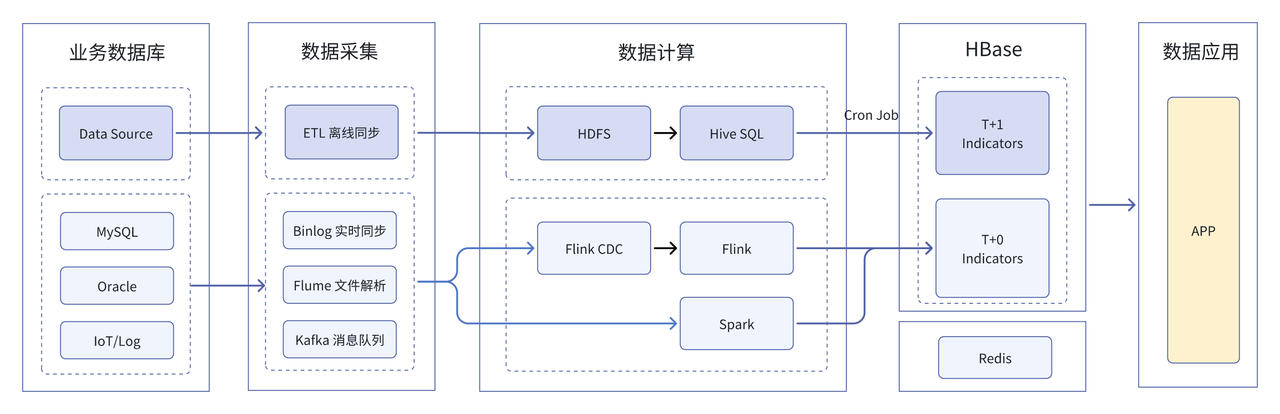
除了每天定时产出 T+1 的 BI 报表以外,为了应对数据时效性较高的场景,例如业务用户需要对零售门店当日经营数据进行实时查询分析,因此我们在离线数据仓库的基础上加入了实时数据处理链路,通过 Kafka 和 Flink 进行实时数据采集并存储在 HBase 中。考虑到某些场景不仅需要调取/查询当天的数据,甚至需要对当月/年的数据进行查询,因此 T+1 的存量历史数据会与 T+0 的实时增量数据汇总存储至 HBase 中进行合并。整体架构如上图所示:
- T+0 实时数据:从业务数据库 MySQL 中实时同步 Binlog、利用 Flume 实时采集 IoT 工厂设备端日志,采集到实时数据会存储在 Kafka 消息队列中,通过 Flink 和 Spark 进行指标计算并将结果存储至 HBase 中。
- T+1 历史数据:T+1 的存量历史数据则会全量存储于 Hive 中,经过 Hive 进行 ETL 处理后通过定时调度写入 HBase 中并对历史数据进行覆盖。
此外,为进一步优化查询性能并降低存储成本,引入了 Redis 作为维度数据的缓存层,将高频访问的热数据缓存于 Redis 中,实现了数据的快速读取与响应,将非频繁访问的冷数据存储在 HBase 中,保证数据可长期被访问。
03 存在的问题
- 历史数据更新复杂:在离线数仓中,历史数据需要手动 Merge 到 ODS 层,对于上百张业务表来说,此过程耗时耗力,增加了人力成本。
- 查询效率较低:如果生产环境出现问题,需要对问题进行追溯,而采用 Hive 跑一个批处理任务,短则至少需要 20 分钟。
- 小文件存储压力大:各业务线数据规模差异较大,比如某些业务线数据压缩后仅有几十 MB,而 HDFS 并不擅长存储这种小文件,会对 NameNode 造成很大压力。
- 人力成本高:HDFS 的运维复杂,对运维人员能力要求比较高;实时数据架构的需求开发要求工程师要全方位掌握 Hive、Flink 等组件的专业知识,开发一个报表需要 5-6 人天才能完成,使用及开发成本均比较高。
基于 Apache Doris 的全新架构
01 选型思考
针对早期架构暴露的诸多问题,我们希望在满足需求的情前提下,尽可能实现架构精简和高效,以降低开发、运维、管理的复杂性。为此我们进行了深度调研并决定引入 Apache Doris,引入 Doris 主要基于以下考虑:
- 运维简单:Doris 不依赖外部系统,不存在小文件问题,节点可线性扩展,大大降低了运维复杂度。
- 便捷迁移:Doris 兼容 MySQL 协议,报表系统只需要简单调整就可以直接对接 Doris,无需投入太多的开发工作量。
- 性能卓越:Doris 支持向量化执行引擎和物化视图等,可有效提升查询效率;同时 Doris 采用高效的 ZSTD 压缩算法,压缩比可以达到 10 倍,大幅降低了存储成本。
- 社区活跃:Doris 的社区非常活跃,同时飞轮科技为社区投入一支专业的技术团队,如在使用过程中遇到的任何性问题,只需在社区交流群反馈,即可快速获取解决方案。
02 基于 Apache Doris 建立统一实时数据仓库
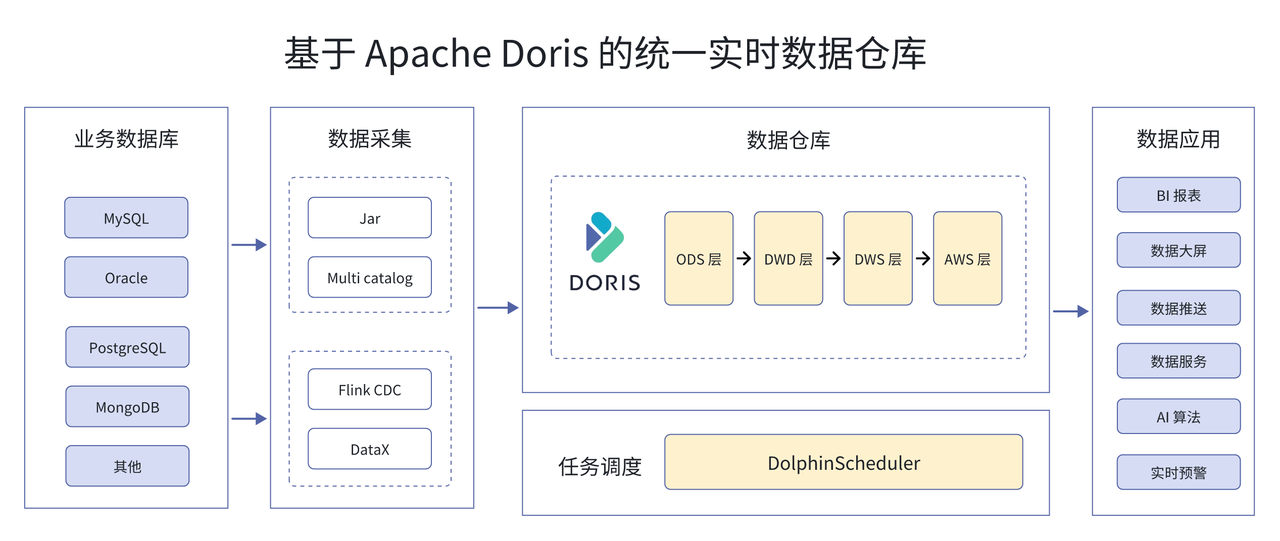
Apache Doris 引入后,我们对离线数仓及实时数仓进行全面升级及改造,构建了统一实时的数据仓库。
在离线数据处理上, 通过自研的 Jar 及 Doris Multi Catalog 将业务数据库数据同步到 Doris 中,数据逐步通过 Doris 的 ODS 层、DWD 层、DWS 层、ADS 层完成清洗、汇总等操作,最后由 ADS 层直接为应用层提供离线数据服务。ODS 层使用了 Doris Unique Key 模型,无需手动 Merge 历史数据,有效降低了数据处理的复杂性。
在实时数据处理上, 通过 Flink CDC 将业务数据库数据实时同步至 Doris ,数据进入 Doris 后同样经过分层处理,由 ADS 层为应用层提供实时数据服务。为避免任务处理时出现异常数据等问题,在实时数据处理流程中,会借助 DataX 进行离线补数。
Apache Doris 的引入,为雨润集团带来非常显著的收益:
- 人员效率提升 3 倍: 首先,只需掌握 SQL,即可快速完成整个实时报表的开发,人员效率提升 3 倍。其次,之前计算逻辑维护在代码中,如需改动代码,修改、打包、上线等,流程繁琐耗费时间,而当前只需要修改 SQL 就可以修改计算逻辑,流程优雅且简洁。
- 成本节省 100 万: 依靠 Doris 极致的数据压缩能力和计算性能,减少了资源存储成本及人力投入,实现高达 100 万的成本节省。
- 计算效率提升 30 倍:相较于 Hive 来说,Doris 计算效率更加高效,效率至少提升 30 倍。
- 导入便捷高效: 实时数据导入流程简化,仅需在页面配置即可完成,避免了以往基于 Flink Jar 包修改上传的繁琐操作与时间消耗。
自研数据治理平台
为提升数据处理效率、确保数据的质量与安全,我们自研了数据治理平台,并集成了数据服务 API 平台、DDL 转换工具、数据集成、元数据管理、数据大屏等核心功能,便于业务部门高效使用及管理数据。接下来,我们对几个重要的功能进行介绍。
01 数据服务 API 平台
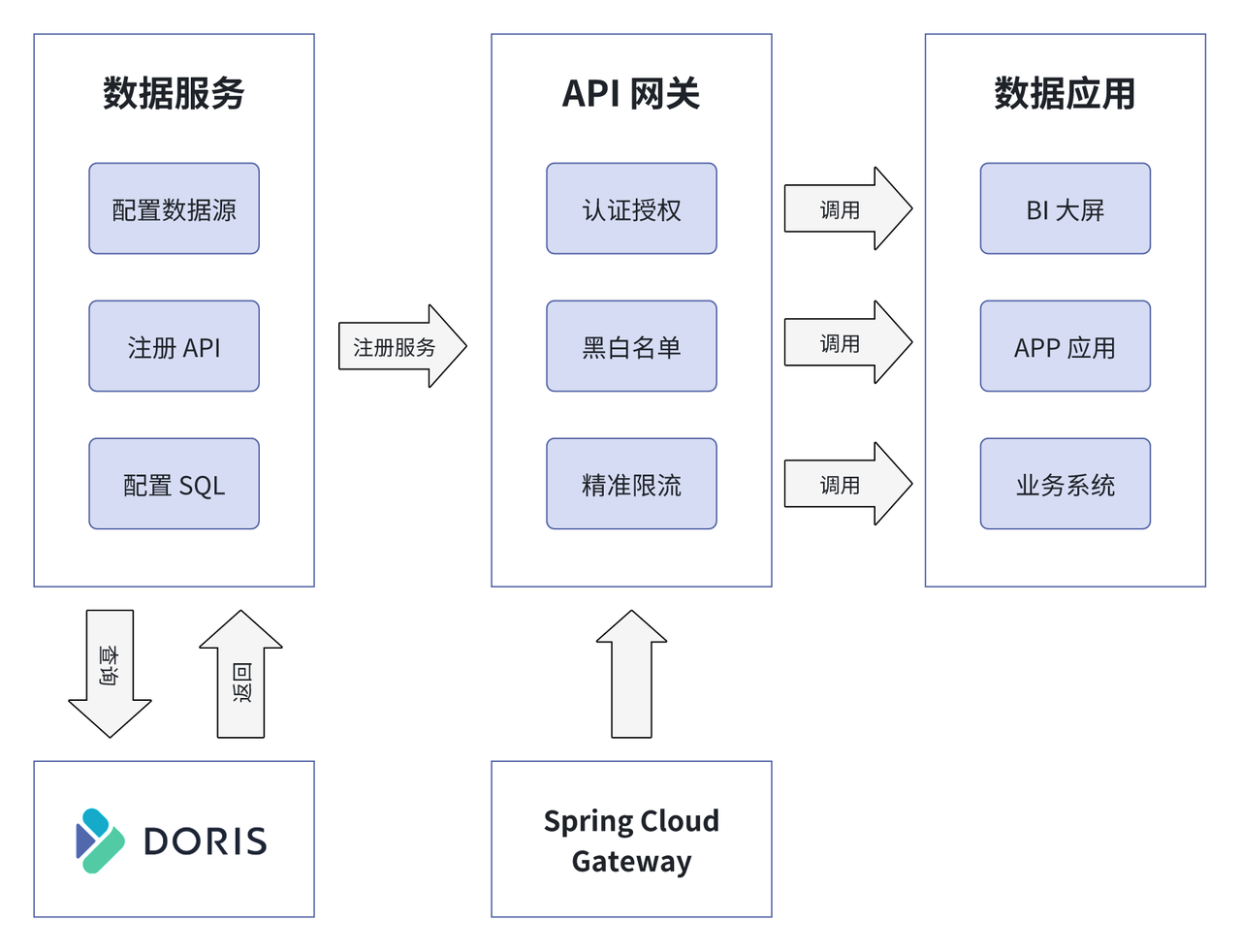
考虑到某些场景数据敏感、某些业务希望把数据中台计算好的数据嵌入到自己的业务系统中,因此,不便于在数据中台展示报表,因此我们基于 Apache Doris 构建了数据服务 API 平台。用户可以在页面上自主配置数据源、请求名称、SQL 配置等操作,当 SQL 配置完成后,就可以从 Doris 中读取数据,数据返回后通过 API 网关的认证授权、黑白名单、精准限流等操作,实现报表内容隐私性的保护。该平台由 Spring Cloud Gateway 提供统一的路由方式,调用数据主要服务 BI 大屏、APP 应用和其他业务系统。
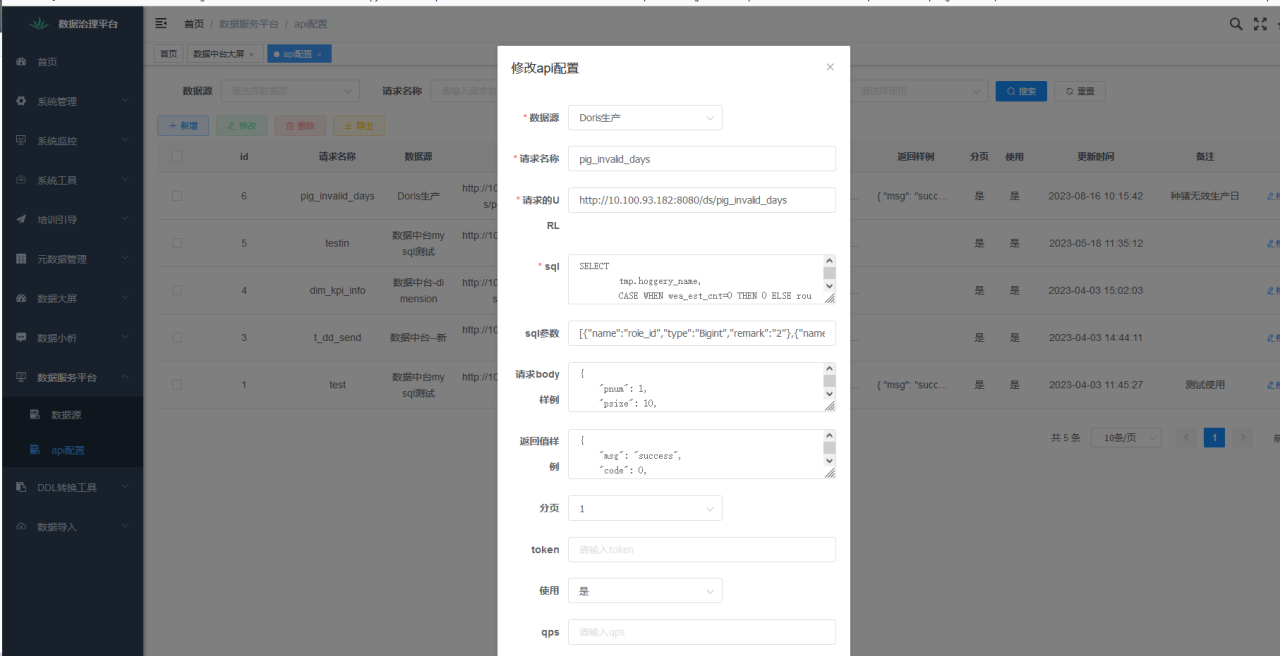
该平台使用简便,即使不精通 Java 和 Spring Cloud 也可以实现接口的开发。在满足报表隐私性要求的前提下,不仅降低了数据服务接口开发的难度和成本,也提升了数据服务的灵活性和可定制性。
02 DDL 转换工具
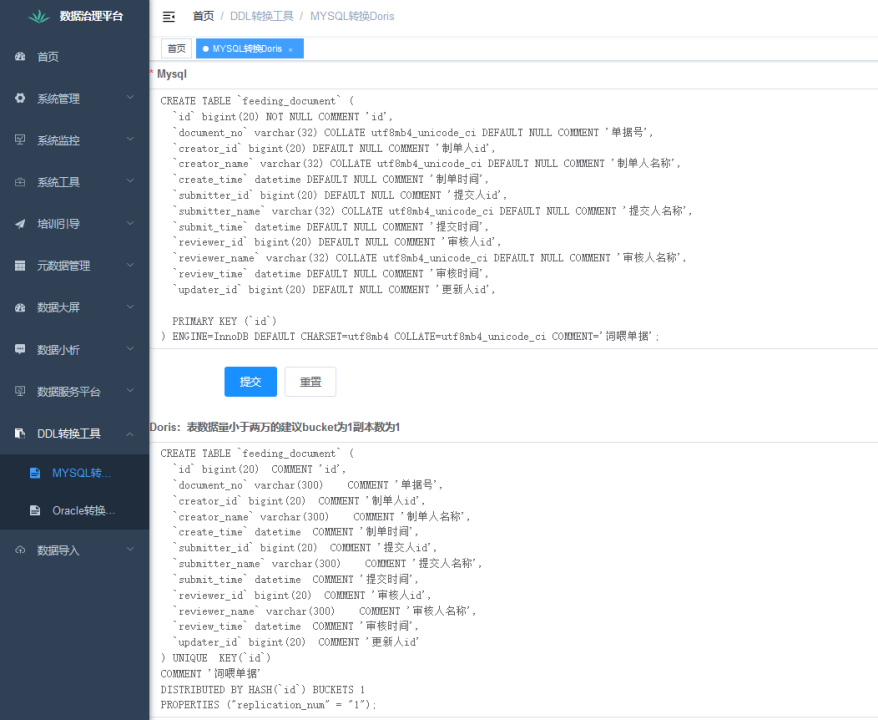
在实际应用过程中,我们发现从 MySQL 或者 Oracle 中同步数据表到 Doris 时,可能存在格式不统一的问题。我们可以通过自研的数据治理平台来实现数据类型的转换,以减少数据导入 Doris 时的建表时间,具体功能包括:
- DDL 转换:识别需要导入到 Doris 的 MySQL / Oracle 字段类型,将这些字段类型转化为 Doris 字段类型,主要通过正则表达式匹配到相应的字符串进行替换。需要说明的是,MySQL 中 varchar 字段导入 Doris 中时,varchar 字段长度需乘以 3。
- DDL 更新:当原表 DDL 发生变化,并需同步结构到 Doris 时,目前的解决方法是定时扫描 MySQL Scheme 信息,并将其转化为 Doris 对应的语句,执行相应的操作以实现 DDL 更新。
- 批量创建: 在数据治理平台中,可通过页面勾选多表,批量创建对应的 Doris 表。
在与社区的交流中,我们了解到 Apache Doris Flink Connector 集成了 FlinkCDC,并支持了 MySQL 等关系型数据库的整库同步,无需提前在 Doris 中建表,用户可以直接使用 Connector 快速将上游业务库的表结构及数据接入到 Doris 中,提升了数据同步的效率及一致性。
具体实现为,当 Flink 任务启动后,Doris Flink Connector 将自动识别对应的 Doris 表是否存在。如果表不存在,Doris Flink Connector 会自动创建表,并根据 Table 名称使用侧输出流进行分流,从而实现下游多个表的 Sink 接入;如果表存在,则直接启动同步任务。
参考文档:https://doris.apache.org/zh-CN/docs/ecosystem/flink-doris-connector/
03 数据集成
当前整体架构主要是 DolphinScheduler 进行任务调度,因此我们选择将导入程序打包成 Jar 通过 Shell 方式运行,目前支持 MySQL、Oracle、Doris 数据库类型导入。在运行时候,指定数据库 ID 、查询 SQL 、目标 Doris 表,即可进行数据导入。
经验分享
我们在探索及使用 Apache Doris 的过程中,积累一些实操的经验,在此分享给读者借鉴参考:
数据集成上:
- 实时数据导入:建议先攒批后导入,以降低 Complication 次数。建议设置每 30 秒导入/更新一次,避免过于频繁的实时改动。
- 离线大数据(初始化)导入:建议分批进行导入,如每天有接近 3-4 千万条的财务数据,建议先查询一列的最大值和最小值,将其划分为不同批次,拼接成多个 SQL 分步进行,避免单个任务占用过多资源而导致调度平台瘫痪。
表模型设计上:
- 索引:对于枚举类型较多的列,建议使用 Bloom Filter 索引;对于枚举类型较少的列,建议使用位图索引。
- 分桶:为避免数据倾斜,建议选择分散性较广的列作为分桶列。一般来说,我们会将 Where 条件列和 Join 列作为分桶列。
分析计算优化上:
- 大表间 Join:大表间的 Join 尽量使用 Colocation Join,原因是大表之间的网络开销很大,如果需要进行 Shuffle 操作,代价较高。
- Join 顺序:建议左表为大表,右表为小表,这样能在开销小的同时更好利用 Runtime Filter,从而提升 Join 性能。
未来展望
未来,雨润集团还计划基于 Doris 进行数据血缘管理和数据地图构建,帮助工程师和分析师更好地管理和理解数据,从而提升数据开发的效率。在血缘管理方面,将构建基于 Doris 的血缘管理平台,当用户在开发 SQL 时,可以将图与图之间的依赖关系存入到图数据库中,并通过可视化表展示表与字段间的血缘关系,便于追溯定位问题、提升开发效率。在数据地图方面,计划基于 Doris 来构建数据地图,对表、对库进行主题域划分和数据域划分,并实现主题索引、表索引和字段索引功能,让数据资产的管理与利用更加高效、便捷。
















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











