








 01 前言
01 前言
在前面的几篇最佳实践中,我们分享了利用巨杉数据库SequoiaDB,实现业务系统同城双中心、两地三中心容灾的最佳实践。
在生产系统中,随着数据库集群接入的业务系统数量更多,业务量逐渐增大,对数据库的承载能力也提出了更高的要求。最初搭建的数据库集群,存储资源和计算资源已无法支撑未来的业务需求,这就需要对集群进行扩容。
在本次分享中,我们将分上、下两篇,为大家讲解SequoiaDB在线扩容的最佳实践,包含扩容规划、技术原理、操作步骤。从而为数据库系统的容量规划和运维,提供一些指导和建议。
02 背景
2.1. 数据库扩容
在移动互联的背景下,传统的业务办理模式发生了新的变化,对数据库系统也提出了新的要求,主要体现为:容量快速扩展、高并发交易查询等。传统的集中式数据库,在处理这些问题时,遇到了明显的瓶颈。
分布式数据库技术的出现,这些将会问题迎刃而解。现如今,一个业务系统,从最初的数据库架构设计开始,就应当具备随着业务扩展,进行弹性伸缩、高并发访问的能力。
2.2. SequoiaDB扩容能力
SequoiaDB 巨杉数据库是一款原生分布式数据库,基于存算分离的思想进行设计,不但可以轻松应对海量数据的存储和访问,对弹性扩展的支持,也是非常强大的。
• 采用通用、开放的硬件平台,计算能力和存储容量均可扩展
• 扩容过程对应用程序透明,无需修改配置及应用代码
• 操作简便、灵活,支持图形化和命令行操作
• 支持多种分区方式,如水平、垂直、多维分区,也支持散列、范围分区算法
• 支持在线对数据进行重分布(rebalance)
03 SequoiaDB 扩容技术
3.1 技术概念
集合:用来存储数据表的对象,相当于传统数据库中的Table。
集合空间:是一种用来存储集合的物理对象,每个集合空间在数据节点均对应一个文件,类似于MySQL中的Database。每个集合只能属于一个集合空间。
域:域是若干个数据组构成的组合。可以通过域,来灵活地管理集合空间中数据的在数据组中的分布。例如:创建一个域d_bills,包含group[1,2,3]这3个数据组,创建集合空间bills时,指定到域d_bills。这样一来,bills下的分区表,将会默认分布在group[1,2,3]数据组上。域还可以用来做数据的物理隔离,进行多租户管理。
分区:在分布式数据库SequoiaDB中,分区功能,是将一张表的数分散存储到多个物理位置,达到更好的并发读写性能。在数据量很大时,性能提升更为明显。
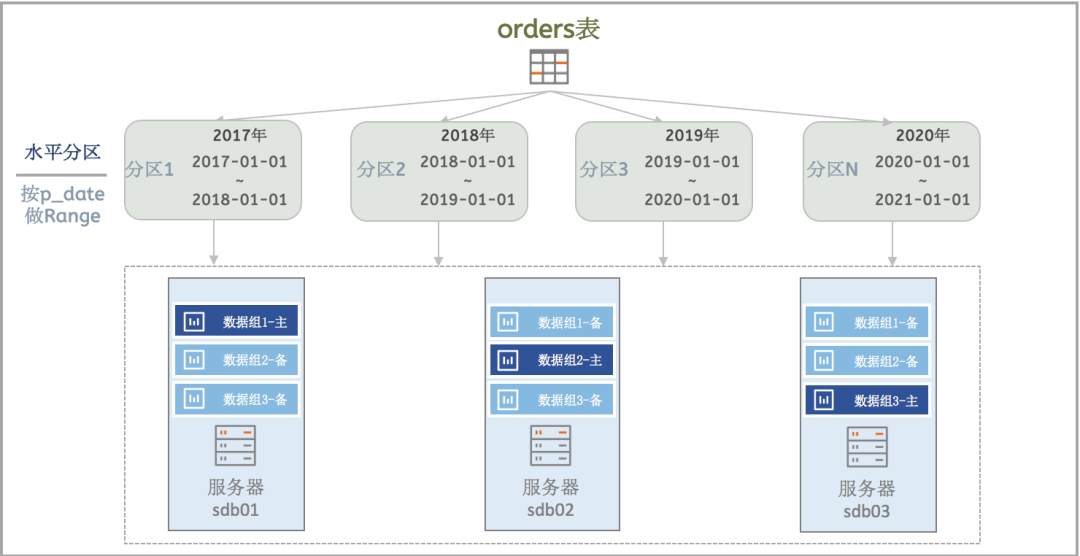
水平分区:将一个表,按照规则,分散到位于不同服务器上的数据组中来存储。
-
Hash:哈希分区,按照Hash算法,利用分区键的 hash 值进行分区从而均匀打散数据;
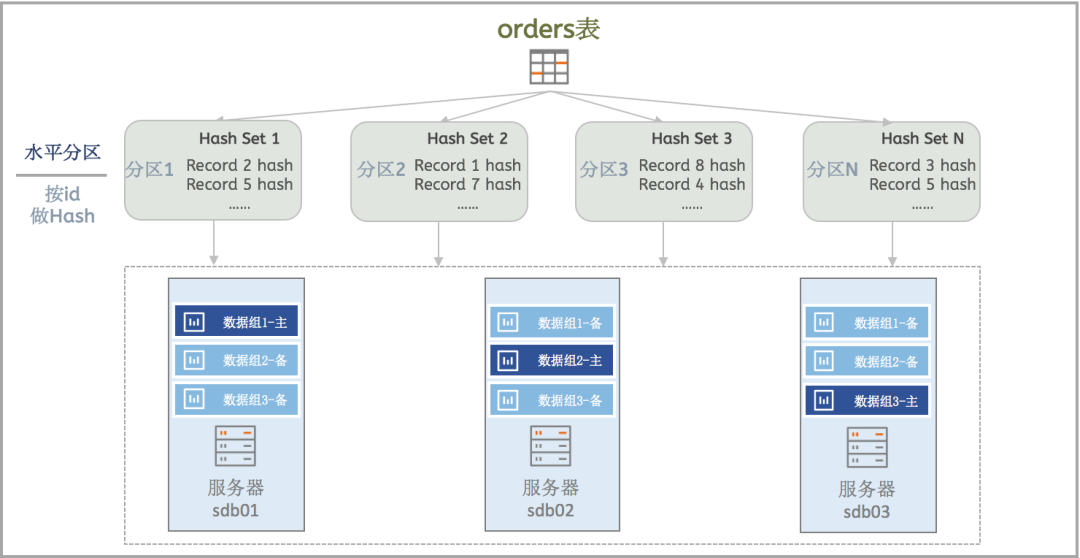
-
Range: 范围分区,是指将集合数据,按照不同的取值范围,对数据进行分区。
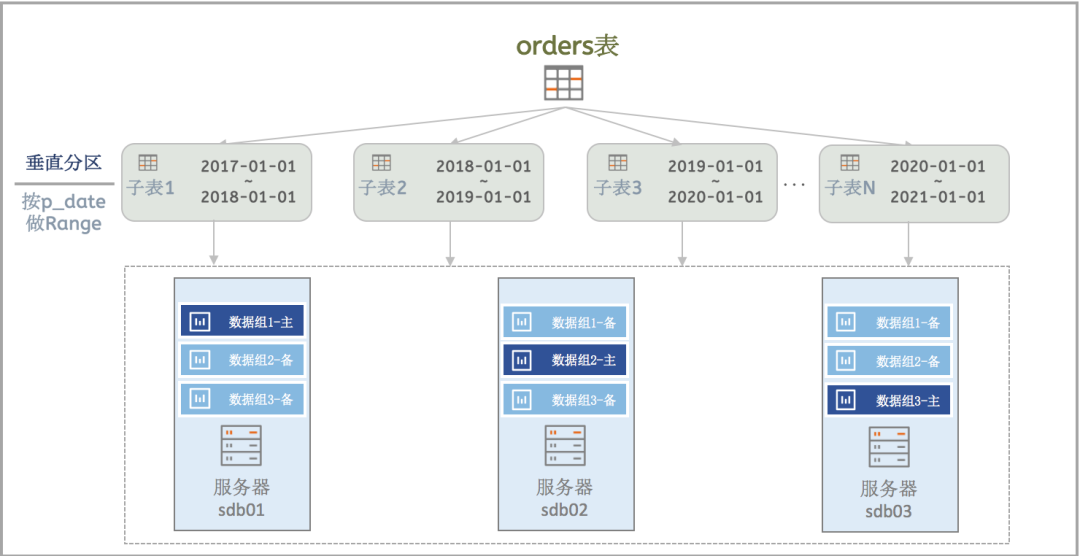
垂直分区:将一个表,切分成多个子表(只能按Range),每个子表存放某个范围的数据,并位于某个数据组。事实上,数据存储在各个子表中,挂载到主表后,由主表向应用提供访问,主表并不存储数据。(注:垂直分区,主要是结合水平分区,用在多维分区场景,单纯的垂直分区实际效果与水平Range分区一致)
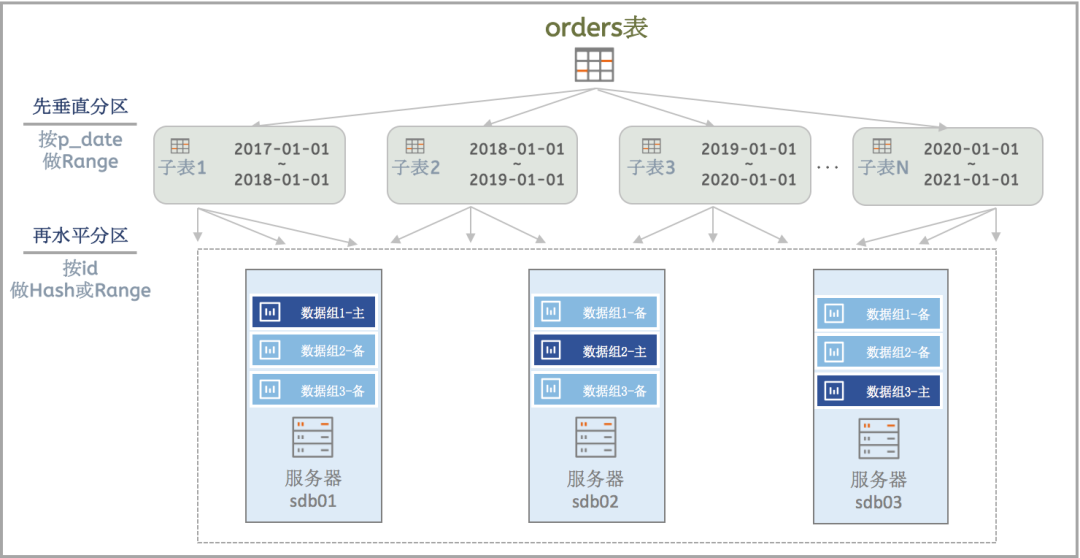
多维分区:将数据进行两层分区。首先做垂直分区,把一个表切分成多个子表;然后将子表再进行分区,分散到不同的数据组中。
3.2 扩容步骤简述
扩容操作步骤分为两部分。
-
数据扩容:包括主机配置、集群中添加主机、数据节点扩容、数据重分布、验证等。
-
计算扩容:主要是增加协调节点、增加计算实例。
SequoiaDB数据库扩容过程如下图所示:

04 SequoiaDB 扩容规划
4.1 概述
在本文用到的环境中,SequoiaDB数据库集群目前有3个数据组datagroup[1,2,3]。现在空间使用率较高,某业务交易延时也出现了显著升高。因此,需要对存储能力、计算能力进行扩容。
4.2 环境信息收集
由于业务的复杂性,在早期做数据存储的规划时,不同的业务表上,其集合、集合空间、域的管理方式没有统一,可能会存在数据分布策略不相同的情况:
-
创建集合空间时,有的采用了域管理,有的没有采用,而是采用了系统默认的域,即全部数据组
-
创建集合(表)时,有的单独指定了数据组,有的没有指定,则默认存放在集合空间所使用的数据组
-
有的域开启了自动分布特性,有的域没有开启
-
因此,扩容前,应当对这些信息加以收集,以便做好容量规划,从而决定扩容后的数据重分布策略
因此,应当对表、集合空间、分区类型、数据分布状况、域的使用策略,进行收集,并以此来设计数据重分布方案。
下表的信息,来自本实验环境。在生产环境中,请按照实际情况进行收集。
表1 集合信息收集表
| 集合名称 (表) | 分区 类型 | 所属集合空间 | 数据域 | 数据分布 |
| orders_hash | 水平 Hash | bills | d_bills | group[1,2,3] |
| orders_range | 水平 Range | bills | - | group[1,2,3] |
| orders_vertical | 垂直 分区 | bills_hist | - | group[1,2] |
| orders | 多维 分区 | bills | d_bills | group[1,2,3] |
| orders_hist | 水平 Hash | bills_hist | - | group[1,2,3] |
表2 集合空间信息收集表
| 集合空间 | 数据分布 | 数据域 |
| bills | group[1,2,3] | d_bills |
| bills_hist | group[1,2,3] | - |
表3 域信息收集表
| 域 | 数据组 | 开启自动重分布 |
| d_bills | group[1,2,3] | 否 |
实验环境集合(表)信息如下:

4.3 方案设计
根据表1,目前系统中共五张表,我们逐个去分析,并设计其数据重分布方案。
| 字段 | 数据类型 | 描述 |
| order_id | int | 订单编号 |
| p_date | date | 订单生成日期 |
| location | varchar(100) | 交易发生地点 |
orders_hash表:采用了水平分区(Hash),表的数据平均分布在d_bills域的三个数据组中group[1,2,3]中。现在扩容后,需要将数据重新分布,均匀分布在6个数据组中。
orders_range表:采用了水平分区(Range),不同范围的数据,位于不同的数据组group[1,2,3]中,没有采用域管理。现在扩容后,需要手动进行数据重分布,将部分数据移动到新的数据中。
orders_vertical表:采用了垂直分区(Range),数据被拆分成多个子表,每个子表的数据分布在数据组group[1,2]中的一个。现在扩容后,需要将子表新建到新增的数据组上,然后将子表挂载到主表。这样一来,新产生的数据,就可以存储在新增的数据组。
orders表:采用了多维分区,即先按Range做垂直分区,再按Hash做水平分区(本文的例子中,Range分区键采用p_date字段,Hash分区键采用order_id字段),数据分布在d_bills域的3个数据组中group[1,2,3]中。现在扩容后,首先要将新建的数据组,加入原有的域d_bills,其次对每个子表进行数据重分布,使其均匀分布在6个数据组。最后,为新的业务数据(例如2021年)新建子表并完挂载,使新子表也都分布在域中的6个数据组。
orders_hist表:采用了水平分区(Hash),表的数据分布在三个数据组中group[1,2,3]中。由于是历史表,后续打算继续使用group[1,2,3]来存放历史数据,所以本次扩容后,无需进行数据重分布。
由于orders表采用了多维分区,操作相对更复杂,因此本文(下篇)将以这个场景为例,来演示数据的重分布过程。
4.4 扩容规划
扩容操作前,需要对容量、服务器、IP地址、数据组、数据节点进行规划。
容量及服务器规划:
| 规划 | 当前集群 | 新增 |
| 容量 | 600G | 600G |
| 数据目录 | /data/sequoiadb | /data/sequoiadb |
| 服务器个数 | 3 | 3 |
| IP地址、主机名 | 192.168.100.201 sdb01 192.168.100.202 sdb02 192.168.100.203 sdb03 | 192.168.100.204 sdb04 192.168.100.205 sdb05 192.168.100.206 sdb06 |
节点规划:
| 节点 | 当前集群 | 新增 |
| 计算实例 | 3个 | 增加3个 |
| 协调节点 | 3个 | 增加3个 |
| 编目节点 | 3个,1主2备 | 保持现状 |
| 数据节点 | 3个,datagroup[1,2,3] | 增加3个,datagroup[4,5,6] |
至此,扩容实施前的收集和规划已完成。
05 待续
在本文中,我们为大家介绍了巨杉数据库SequoiaDB在线扩容的信息收集、规划、扩容大体步骤。其间,也对分区类型、域、数据切分等概念做了讲解,便于大家加深理解,为接下来的扩容操作做好准备。
那么,数据库扩容要怎么来操作:
-
如何向现有集群中,增加新的主机?
-
如何在新的主机上,增加数据组?
-
如何完成现有业务数据的重分布?
-
如何配置新增业务数据的分布?
-
如何添加协调节点?
-
如何增加计算实例?
我们将在近期推出《SequoiaDB在线扩容最佳实践》(下篇),为大家一步一步演示操作过程,敬请期待!
















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









