






一. 支持向量机的介绍
支持向量机(Support Vector Machine,SVM)是一种常用于分类和回归分析的监督学习模型。它在机器学习领域中具有广泛的应用,尤其在数据挖掘、模式识别和人工智能领域中得到了广泛的关注和应用。
SVM 的核心思想是找到一个最优的超平面来分隔不同类别的数据点。在二维空间中,这个超平面就是一条直线,而在高维空间中,它是一个超平面。最优的超平面是指能够最大化类别间的间隔,使得不同类别的数据点尽可能远离超平面。
具体来说,SVM 在分类问题中的工作原理如下:
①支持向量:在数据点中,离超平面最近的那些点被称为支持向量。它们决定了超平面的位置和方向。
②间隔最大化:SVM 的目标是找到一个超平面,使得支持向量到超平面的距离(即间隔)尽可能大。这样可以提高模型的泛化能力,减少对未知数据的误分类风险。
③核函数:在非线性问题中,SVM 使用核函数将数据映射到高维空间,从而使得数据在高维空间中线性可分,进而找到一个有效的超平面进行分类。
除了在分类问题中的应用,SVM 也可以用于回归分析,即支持向量回归(Support Vector Regression,SVR)。在这种情况下,SVM 旨在找到一个超平面,使得数据点尽可能接近这个超平面,同时保持间隔不超过一定的阈值。
1. 支持向量机的优点
①有效处理高维空间的数据。
②在数据量较小的情况下也能表现良好。
③在处理非线性问题时,可以通过选择合适的核函数来进行转换,从而实现非线性分类。
2. 支持向量机的缺点
①对大规模数据集和特征数量较多的数据处理效率较低。
②对于数据噪声和缺失值敏感。
③需要选择合适的核函数和参数,这个过程可能需要一定的专业知识和经验。
二. 支持向量机的原理及实现步骤
1. 支持向量机的原理
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归分析的监督学习算法。它的核心原理是通过找到一个最优的超平面来分隔不同类别的数据点,并且使得这个超平面与支持向量之间的间隔最大化。支持向量是离超平面最近的数据点,它们决定了超平面的位置和方向。
在SVM中,间隔的概念非常重要,它表示支持向量到超平面的距离。SVM通过最大化间隔来确定最优的超平面,从而提高模型的泛化能力,减少对未知数据的误分类风险。为了实现这一目标,SVM将分类问题转化为一个凸优化问题,并通过求解约束条件下的最优化问题来找到最佳的超平面。在处理线性不可分的情况时,SVM引入松弛变量来处理间隔内的数据点,这就是软间隔(Soft Margin)SVM。
此外,SVM还可以通过核函数将数据映射到高维空间,从而使得非线性问题在高维空间中变得线性可分。常用的核函数包括线性核函数、多项式核函数、高斯径向基函数(Radial Basis Function,RBF)等。通过这些核函数的使用,SVM可以处理更加复杂的分类问题,提高了其在实际应用中的灵活性和适用性。
2. 支持向量机的实现步骤
具体的步骤可以划分以下几步:
①数据准备: 首先需要准备带有标签的训练数据集,包括特征和对应的类别标签。这些数据可以是二维或多维的,但SVM通常适用于中小型数据集。
②特征缩放: 对数据进行特征缩放是一个常见的预处理步骤,可以使得不同特征的取值范围相近,有助于模型的训练和收敛。
③选择核函数: SVM可以通过核函数将数据映射到高维空间,从而处理线性不可分的问题。常见的核函数包括线性核函数、多项式核函数和高斯径向基函数(RBF)等。选择合适的核函数可以提高模型的分类性能。
④模型训练: 使用训练数据集对SVM模型进行训练。训练过程中,SVM会尝试找到一个最优的超平面来分隔不同类别的数据点,并且使得超平面与支持向量之间的间隔最大化。
⑤模型评估: 训练完成后,使用测试数据集对模型进行评估。评估指标可以包括准确率、精确率、召回率、F1分数等,用于衡量模型在未知数据上的分类性能。
⑥调参优化: 根据评估结果,可以进行模型的调参优化,包括选择合适的正则化参数(C参数)、核函数参数(如多项式核函数的次数、高斯核函数的带宽)、优化算法(如SMO算法)等,以进一步提高模型的性能。
⑦预测应用: 训练完成并调优后的SVM模型可以用于实际的预测应用,对新的未知数据进行分类或回归预测。
三. Matlab主函数完整代码
完整代码源文件及数据集见附件
%% 初始化
clear
close all
clc
warning off
%% 导入数据
res = xlsread('数据集.xlsx');
%% 分析数据
num_class = length(unique(res(:, end))); % 类别数(Excel最后一列放类别)
num_res = size(res, 1); % 样本数(每一行,是一个样本)
num_size = 0.7; % 训练集占数据集的比例
res = res(randperm(num_res), :); % 打乱数据集(不打乱数据时,注释该行)
flag_conusion = 1; % 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1 : num_class
mid_res = res((res(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size * mid_size); % 得到该类别的训练样本个数
P_train = [P_train; mid_res(1: mid_tiran, 1: end - 1)]; % 训练集输入
T_train = [T_train; mid_res(1: mid_tiran, end)]; % 训练集输出
P_test = [P_test; mid_res(mid_tiran + 1: end, 1: end - 1)]; % 测试集输入
T_test = [T_test; mid_res(mid_tiran + 1: end, end)]; % 测试集输出
end
%% 数据转置
P_train = P_train'; P_test = P_test';
T_train = T_train'; T_test = T_test';
%% 得到训练集和测试样本个数
M = size(P_train, 2);
N = size(P_test , 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input );
t_train = T_train;
t_test = T_test ;
%% 转置以适应模型
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
%% 创建模型
c = 10.0; % 惩罚因子
g = 0.01; % 径向基函数参数
cmd = ['-t 2', '-c', num2str(c), '-g', num2str(g)];
model = svmtrain(t_train, p_train, cmd);
%% 仿真测试
T_sim1 = svmpredict(t_train, p_train, model);
T_sim2 = svmpredict(t_test , p_test , model);
%% 性能评价
error1 = sum((T_sim1' == T_train)) / M * 100;
error2 = sum((T_sim2' == T_test )) / N * 100;
%% 数据排序
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
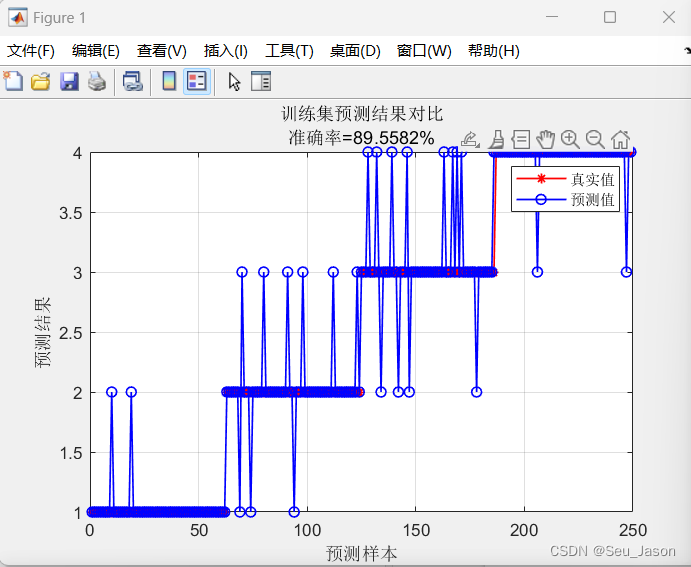
string = {'训练集预测结果对比'; ['准确率=' num2str(error1) '%']};
title(string)
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
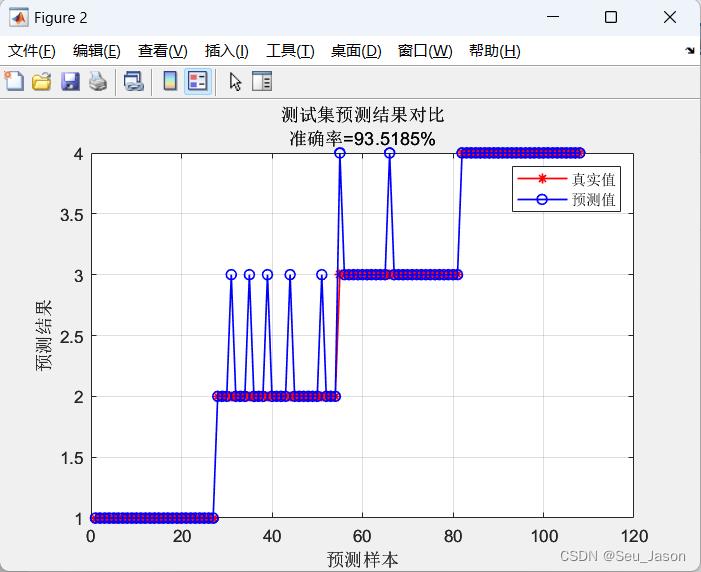
string = {'测试集预测结果对比'; ['准确率=' num2str(error2) '%']};
title(string)
grid
%% 混淆矩阵
figure
cm = confusionchart(T_train, T_sim1);
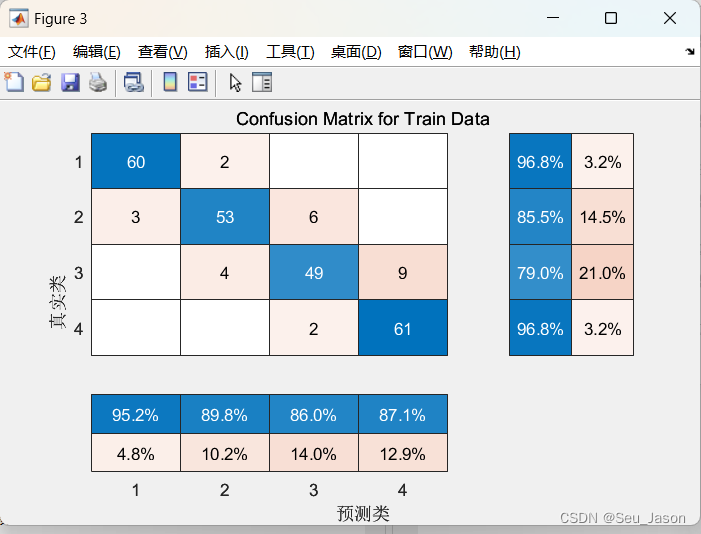
cm.Title = 'Confusion Matrix for Train Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
figure
cm = confusionchart(T_test, T_sim2);
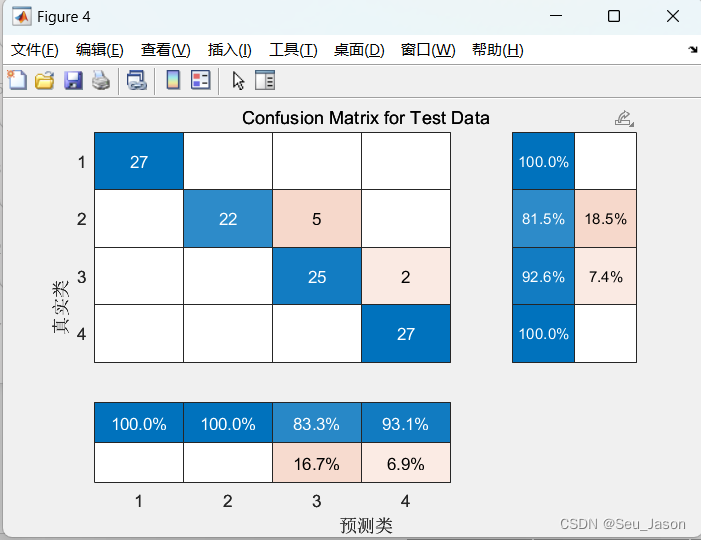
cm.Title = 'Confusion Matrix for Test Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';四. Matlab仿真展示
1. 训练集预测结果
2. 测试集预测结果
3. 训练集混淆矩阵
4. 测试集混淆矩阵


















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









