







一. ReLU函数介绍
1. 函数表达式
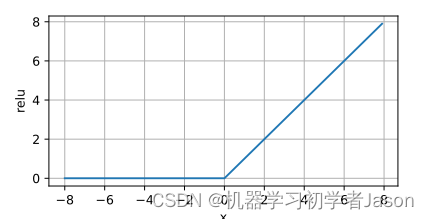
在x大于0时输出x,否则输出0。
公式为:𝑓(𝑥)=max(0,𝑥)
2. 函数图像
二. ReLU函数使用
ReLU(修正线性单元)是一种常用的激活函数,在深度学习中广泛应用。它具有以下几个优点,适用于不同的场景:
-
非饱和性(Non-saturation):ReLU在正区间(x>0)上是线性的,没有梯度消失问题,因此在反向传播过程中能够更有效地传播梯度,使得网络的训练更加稳定和快速。
-
稀疏激活性(Sparsity of Activation):由于ReLU在负值部分输出为0,因此它引入了稀疏性,使得神经网络中的许多神经元变得不活跃。这有助于减少过拟合并提高模型的泛化能力。
-
计算简单:ReLU的计算简单且高效,只需比较输入是否大于零即可,不涉及复杂的数学运算,因此在实际应用中的计算开销较小。
-
解决梯度消失问题:在深层网络中,使用Sigmoid或Tanh等饱和激活函数容易导致梯度消失问题,而ReLU可以在一定程度上缓解这个问
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2043
2043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









