






 本文探讨了在量化交易软件中采用软性扮演者-评论者算法,通过引入熵分量增强模型的灵活性和探索性。文章详细描述了如何在OpenCL环境中实现随机动作选择,克服采样与学习分布不匹配的问题,并优化了训练过程中的动作选择策略。
本文探讨了在量化交易软件中采用软性扮演者-评论者算法,通过引入熵分量增强模型的灵活性和探索性。文章详细描述了如何在OpenCL环境中实现随机动作选择,克服采样与学习分布不匹配的问题,并优化了训练过程中的动作选择策略。
1. 模型优化
赫兹量化交易软件转到直接优化我们构建的模型之前,我要提醒您,软性扮演者-评论者是一种在连续动作空间中随机模型的强化学习算法。这种方法的主要特点是在奖励函数中引入了熵分量。
使用随机扮演者策略可令模型更加灵活,并且能够解决复杂环境中的问题,在这些环境中,某些操作可能不确定或无法定义明确的规则。在处理包含大量噪声的数据时,该策略往往更健壮,因为它考虑到概率分量,并且不受明确规则的约束。
添加熵分量可以鼓励对环境的探索,从而增加低概率动作的奖励。探索和开发之间的平衡由温度比率支配。
在数学形式中,软性扮演者-评论者方法可表述为以下等式。
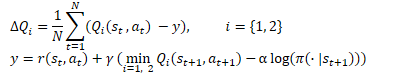
添加图片注释,不超过 140 字(可选)
1.1向扮演者政策里增添随机性
赫兹量化交易软件的实现中,由于利用 OpenCL 实现的复杂性,我们放弃了使用随机扮演者政策。类似于 TD3,我们将其替换为某些环境中所选动作的随机偏移量。这种方式更易于实现,并允许模型探索环境。但它也有其缺点。
引起注意的第一件事是采样动作与模型学习的分布之间缺乏联系。在某些情况下,当学习的分布比采样区域宽时,这会压缩研究区域。这意味着模型政策很可能不是最优的,而是取决于随机选择的学习起点。毕竟,在初始化新模型时,我们用随机权重填充它。
在其它情况下,采样动作也许会落在学习分布外围。这扩大了研究界域,但与奖励函数的熵分量相冲突。从模型的观点,学习分布之外的动作其概率为零。多亏熵分量,无论其价值如何,它都会收到最大奖励。
在训练过程中,该模型努力寻找可盈利策略,并提升具有最大回报的行动的可能性。同时,减少了利润较低和无利可图的行动的可能性。赫兹量化交易软件之前使用的简单采样没有考虑到这个因素。来自采样区域的任何动作,它都为我们提供相等的概率。无利可图动作的低概率会产生高熵分量。这扭曲了动作的真正价值,抵消了以前积累的经验,并导致构建出不正确的扮演者政策。
此处仅有一个解决方案 — 构建扮演者的随机模型,并从所学习分布中抽取动作。
我们已经讨论过 OpenCL 关联环境端缺少伪随机数生成器,因此我们将在主程序端使用生成器。
同时,赫兹量化交易软件记得所学习分布仅在 OpenCL 端可用。它包含在我们模型的内部对象之中。因此,为了安排采样过程,我们必须在主程序和 OpenCL 关联环境之间实现数据传输。这并不依赖于安排流程的所在。
在主程序端组织进程时,赫兹量化交易软件需要加载分布。这涉及 2 个缓冲区:概率和相应的函数值。
在 OpenCL 关联环境端安排进程时,我们必须传递随机值的缓冲区。稍后将要用它来选择单独的动作。
于此还应该考虑一点 — 所获值的消费者。在操作期间,我们将使用采样值来执行动作,即在主程序端。但在训练期间,我们会将它们传输给 OpenCL 关联环境端的评论者。众所周知,模型训练对减少执行操作的时间提出了最严格的要求。考虑到这一点,决定仅将一个随机值缓冲区传输到 OpenCL 关联环境,并在那里安排进一步的采样过程似乎非常合乎逻辑。
决策已然做出,我们开始实现。首先,赫兹量化交易软件修改 OpenCL 程序的 SAC_AlphaLogProbs 内核。我们的改动甚至会在一定程度上简化特定内核的算法。
我们在内核的外部参数中添加一个随机值的缓冲区。我们期望收到一组 [0,1] 范围内的随机值,安排在该缓冲区中的采样过程。
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, __global float *random, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float prob = 0; float value = 0; float sum = 0; float rnd = random[i];
为了选择一个动作,我们安排了一个循环,枚举所分析动作的所有分位数的概率,并计算它们的累积总和。在循环主体中,在计算累积总和的同时,我们还用结果随机值检查其当前值。超过该值的第一时间,我们就会用当前分位数作为选定动作,并中断循环迭代的执行。
for(int r = 0; r < count_quants; r++) { prob = probs[shift + r]; sum += prob; if(sum >= rnd || r == (count_quants - 1)) { value = quantiles[shift + r]; break; } }
现在我们不需要再像以前那样寻找最接近的分位数配对。我们有一个已知概率的选定分位数。我们所要做的全部就是激活结果值,并计算熵分量的值。
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; else outputs[i] = value; break; default: outputs[i] = value; break; } log_probs[i] = -alphas[i] * log(prob); }
对内核进行修改后,我们将补充主程序的代码。我们将首先对 CNeuronSoftActorCritic 类进行修改。在此,我们为随机值添加一个缓冲区。它的初始化发生在 Init 方法当中,类似于 cLogProbs 缓冲区。我就不多说了。无需保存它,因为每次直接验算都会重新填充它。因此,我们不会对文件处理方法进行任何调整。
class CNeuronSoftActorCritic : public CNeuronFQF { protected: .......... .......... CBufferFloat cRandomize; .......... .......... };
我们转向前向验算方法 CNeuronSoftActorCritic::feedForward。在此,通过父类和内部 cAlpha 层直接验算之后,我们按动作数量安排一个循环,并用随机值填充 cRandomize 缓冲区。
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false; //--- int actions = cRandomize.Total(); for(int i = 0; i < actions; i++) { float probability = (float)MathRand() / 32767.0f; cRandomize.Update(i, probability); } if(!cRandomize.BufferWrite()) return false;
填充缓冲区的数据将传递到 OpenCL 关联环境内存。
接下来,我们实现将内核放入执行队列。在此,我们需要加上把参数传输到内核。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_random, cRandomize.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
因此,我们已经在扮演者的前向验算中实现了动作选择的随机性。但要留意反向验算有一处细微差别。要点是,向后验算应根据其贡献将误差梯度分布在每个决策元素。以前,我们调用父类的直接验,误差梯度的分布类似。现在,我们已经在动作选择的最后阶段进行了调整。故此,这也应反映在误差梯度的分布上。















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









