







 本文介绍了一个使用TensorFlow和MNIST数据集初步实现车牌数字识别的示例。虽然MNIST主要包含手写数字,不适合真实车牌的字母和简称,但通过筛选工整的数字图片,依然能展示识别过程。实验结果显示,模型能够正确识别出016720这一车牌号,具有一定的准确性和可信度。
本文介绍了一个使用TensorFlow和MNIST数据集初步实现车牌数字识别的示例。虽然MNIST主要包含手写数字,不适合真实车牌的字母和简称,但通过筛选工整的数字图片,依然能展示识别过程。实验结果显示,模型能够正确识别出016720这一车牌号,具有一定的准确性和可信度。
在前几天写的一篇博文《如何从TensorFlow的mnist数据集导出手写体数字图片》中,我们介绍了如何通过TensorFlow将mnist手写体数字集导出到本地保存为bmp文件。
车牌识别在当今社会中广泛存在,其应用场景包括各类交通监控和停车场出入口收费系统,在自动驾驶中也得到一定应用,其原理也不难理解,故很适合作为图像处理+机器学习的入门案例。
现在我们不妨酝酿一个大胆的想法:在TensorFlow中通过卷积神经网络+mnist数字集实现车牌识别。
实际上车牌字符除了数字0-9,还有字母A-Z,以及各省份的简称。只包含数字0-9的mnist是不足以识别车牌的。故本文所做实验仅出于演示目的。
由于车牌数字是正体,而mnist是手写体,为提高识别率,需要从mnist图片集中挑选出形状比较规则工整的图片作为训练图片,否则识别率不高。作为参考,下图是我挑选出来的一部分较工整数字:
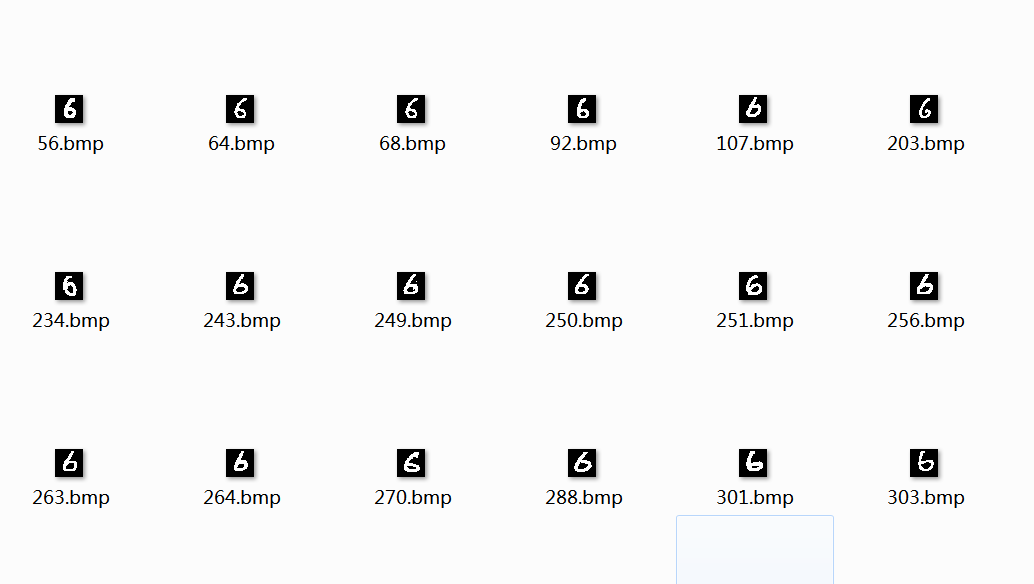
(如果你需要我挑选出来的图片,可以评论或私信我留下邮箱)
出于演示目的,我们从网上找到下面这张图片:

现在我们假设该车牌号为闽0-16720(实际上是闽O-1672Q),暂不识别省份简称,只识别0-16720。
上图经过opencv定位分割处理后,得到以下几张车牌字符。
现在我们通过如下代码,将这几张字符图片输入到上一篇博文《如何用TensorFlow训练和识别/分类自定义图片》中构建的网络:
license_num = []
for n in range(2,8):
path = "result/%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0]*784 for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w+h*width] = 0
else:
img_data[0][w+h*width] = 1
# 获取softmax结果前三位的index和概率值
soft_max = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









