







本人翻译得不是很好,有问题可以互相交流
CNN被证明优于DNN,因为参数少得多。在这里考虑两种限制,一种是限制乘法次数,另一种是限制参数数量。使用CNN框架时,发现相较DNN,在这些限制的情况下,false reject rate改进了27%至44%。
由于运行在移动设备上,因此必须具有较小的内存占用和较低的计算能力。目前谷歌的KWS系统使用DNN,优于HMM。而且DNN在设备上运行,可以通过改变网络中的参数数量,很容易地调整模型大小。CNN在过去几年里已经成为声学模型的热门,在各种语音相关的任务(索引中的任务4 5 6 )里比DNN也更好。
CNN表现比DNN好有几点原因。
1、DNN忽略了input topology(输入拓扑),输入可以按任意(固定)顺序程序,而不影响网络的性能[3],然而,语音的频谱表示在时间上和频率上有很强的相关性,并且通过输入空间的局部区域共享的权重,来用CNN建模局部相关性,已经证明在其他领域[7]有优势。
2.DNN并没有明确地设计成对语音信号中的translational variance(平移方差)进行建模,这种方差可能是由于说话风格[3]不同而存在的。更具体地说,不同的说话风格导致在频域中,formants被移动。这些说话风格要求我们应用各种说话人适应技术来减少特征的变化。虽然啊足够大的DNN确实可以捕获translational invariance,但需要有大量训练示例的大型网络。而CNN可以通过平均(average)隐藏单元在不同的局部时间和频率区域的输出,从而使用更少的参数来捕获。
在论文4 5 6中均证明CNN的KWS比DNN性能好、模型更小。这篇论文中,会看CNN应用到KWS的两种应用。1、我们考虑限制整体计算量的问题,即参数和乘法。这样的限制下,论文8中CNN只有频率的池化,这样的典型架构不能在此使用。因此,我们介绍一种新颖的CNN架构,不池化,但在频域strides the filter,来达到计算约束。2、我们考虑限制系统的整体参数数量。对于这个问题,我们可以通过在时域和频域上池化来提升性能,这是第一次被证明对语音有效,而不使用多个卷积块[5,9].
此论文中的KWS,有14个不同短语组成,来评估这个CNN架构。衡量性能的好坏是通过每小时1次false alarm(FA)操作阈值下观察false reject rate(FR)。这个任务限制乘法数,我们发现CNN在频率上stride filter,FR比在DNN上改善了27%。限制参数的条件下,在时域上池化时,CNN比DNN的FR改善了41%,只在频域上池化时,改善了6%。
如图1所示,DNN的系统由3个部分组成。1、特征提取。每25ms计算一次40维的梅尔滤波器组特征,帧移是10ms。接下来的每一帧中,向左叠加23帧,右叠加8帧,然后输入DNN网络。2、DNN网络。3个隐藏层,每层128个隐藏元,和一个softmax层。每层隐藏层都使用ReLU函数。输出目标是关键词的个数+1,1代表不属于任何一个关键词。对网络的权值进行训练,利用分布式异步梯度下降和交叉熵函数去优化。3、后验处理模块。将来自DNN的单个帧级后验分数组合成与关键词对应的单个分数。对于三部分想进一步了解,可读论文2.

使用CNN代替DNN,其他两个部分不变。典型的CNN结构如图2所示。1、输入信号V是t×f,t和f分别是在时域和频域各自的输入特征维数。权值矩阵W,是(m×r)×n,与full input V进行卷积。权重矩阵跨越大小为m×r的小的局部的时频块,其中m<=t,r<=f。这种权重共享有助于模拟输入信号中的局部相关性。权重矩阵有n个隐藏单元(即特征映射)。filter的步长在时域是非零的s和频域的p。因此,总体上,卷积运算产生n个大小为的特征映射。(t-m+1)/s × (f-r+1)/v.
卷积后,最大池化层有助于消除由于说话风格、信道失真等原因而存在的在时频空间上的可变性。给定池化大小为p×q,池化执行sub-sampling(次采样操作)去减少时频空间。为达到本文的目的,我们考虑non-overlapping pooling(不重叠层),因为在8中没有证明对于语音有帮助。经过池化后,时频空间有为数((t-m+1)/(s·p))×((f-r+1)/(v·q))。

一个典型的卷积结构已经被强有力地测试证明对于许多LVCSR任务有很好的作用(在6和11中体现),是使用两个卷积层。假设输入到CNN的log-mel是t×f=32×40,然后通常第一层的filter在频域上r=9,这个架构filter的大小对时域上没那么敏感,通常选择大小是输入的三分之二,那么这里m=20。卷积乘法是通过步长s=1和v=1,然后,只执行频率上的不重叠的最大池化层,q=3。第二个卷积filter的大小是r=4,没有最大池化被执行。
比如,我们希望参数低于250K,如图1所示的结构比较典型。本文中,将这种架构称为cnn-trad-fpool3。这个架构有两个卷积层,一个linear low-rank(线性低秩层),一个DNN层。但这种架构有一个主要问题,在卷积层大量乘法,由于三维输入,跨时间、频率和特征映射,在第二层中就加剧了问题。但在乘法限制的small footprint的KWS不可行。即使我们的应用被参数限制而不被乘法限制,在时间上池化的其他结构会更适合KWS。接下来我们介绍代替CNN架构以解决限制参数或乘法的任务。

第一个待解决的问题是找到合适的CNN架构,使乘法数限制在500K。经过实验了好多个架构,一个解决限制乘法数的方案是不用两个卷积层,而是一个卷积层,并且在时域上始终有filter。卷积层的输出传递给linear low-rank层,然后两层DNN。如表2所示,这种只有一个卷积层的称作cnn-one-fpool3。为简单起见,从表中我们忽略了s=1,v=1。经过这样的改造,乘数减少了10倍。

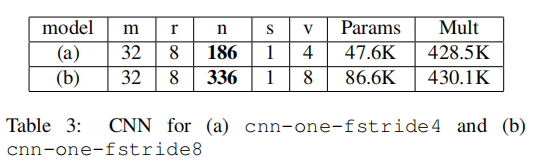
在频率的池化q=3需要步长v=1的filter,这也增加了乘数。因此,我们比较了不在频率上池化但有filter的架构。表3展示了CNN架构-频率filter的r=8,步长v=4(即百分之50重叠),以及v=8(无重叠)。分别叫cnn-one-fstride4,cnn-one-fstride8。为简单起见,省略了线性层和DNN层。表3表示,如果用步长filter的v>1,乘数减少了,因此可以提高隐藏层单元n数量增加到表2中cnn-one-fpool3的架构。
3.4 Limiting Parameters
当保持乘数固定,参数数量仍然远小于250K。然而,增加参数数量又往往会提高更多。我们希望设计一个模型,在保证参数固定的同时,但允许乘数变化。在本节,探索与cnn-trad-fpool3架构不同,限制模型大小250K但不限制乘法数。
一种方法是增加feature maps(特征映射)。如果我们想要提高特征映射但又保持参数固定,我们必须在时域和频域上探索采样。监狱我们已经在cnn-trad-fpool3中在频域上池化了,在这个部分,我们会在时域上探索sub-sampling(子采样)
在4和8这样的声学模型上已经探索了时域上传统的池化,但是没有表现出很大优势。我们的原理是,在声学建模部分,我们想要分类的子词单元(即上下文相关状态)发生在非常短的时间内(即10-30ms)。因此,在时域上池化效果不好。然而,在KWS系统中的关键词单元发生的事件要长得多(即50-100ms),因此,我们探索如果我们提升cnn-trad-fpool3通过在时域中对信号进行sub-sampling(次采样),无论是通过stide还是pool。在时域上pool是有用的,当使用多个卷积子网络【5,9】时。然而,这种方法提高了参数数量并且对于KWS任务来说计算昂贵。据我们所知,这是第一次用更长的声学单元探索在时域上的卷积子网络。
3.4.1stride in time
首先,比较在卷积中时域filter的步长s>1的架构们。表4体现了时域filter的s变化的不同CNN架构。为了简化,忽略DNN层和在实验中不变的常量,即频域步长v=1和时域池化p=1.注意到,当我们提高时域上filter的步长,能增加特征映射n的大小,使参数总数保持不变。我们希望在时域上的次采样不会降低性能,同时增加特征映射提高性能。

3.4.2 pooling in time
一种可替代stride the filter in time的方法是pool in time,通过一个non-overlapping amount。表5中展现了配置,通过在时域上池化,可以提高n,以保持参数总数不变。

为了比较CNN和DNN的KWS,选了14个短语以及有10K到15K的语音,这些语音包含这14个短语。又找了大约396K的语音,不包含任何关键词。训练:验证:测试=80:5:15。然后创建噪声的训练和测试集,通过在[-5db,10db]之间随机采样的信噪比加入汽车和自助餐厅的噪声到干净数据中。模拟噪声条件,并在干净语音和有噪音语音条件下评估。这个KWS的性能评估是通过绘制ROC(接收机工作曲线),这个曲线计算了每个虚警速率的假拒绝率。这个值越低越好。选择系统的阈值是为了在这个语音集上应对每小时的1FA.

首先,分析了典型的CNN体系结构。比较了不池化时p分别等于1,2,3,其他常数保持不变。图3的a和b一个是干净语音,一个是有噪声语音。p=3的时候饱和了。这与8中观察的结果一致。且在FA per hour = 1的时候,相对DNN,改善超过了41.接下来比较当约束乘法和参数时,CNN和DNN的性能。
5.2. Limiting Multiplies
首先,限制乘法数量到500K.如图4所示。表现最好的cnn-one-fstride4,在频域上的步长重叠为百分之五十,但在频域不池化。比fstride8更好,8有一个不重叠的步长。而且,比在频域上池化的fpool3更好。虽然在频域上池化是有帮助的,如图5所示,但是计算昂贵,因此我们必须大大减少特征映射以限制计算。因此,在乘法数有限制的条件下,首选就交叠步长的filter CNN架构。fstride4在干净和噪音的条件下比DNN表现的好27%和9%。

5.3. Limiting Parameters
最好表现的是cnn-trad-fpool3。图5所示,所有在时域上有步长的表现更差,没有步长的更好。比较图6中,cnn-tpool2,即p=2,是表现最好的系统。这些结果表明,在次采样之前,在时域上池化,相当于在相邻帧之间建立了关系,更好,比先验选择哪一个相邻帧进行滤波的时间步长更有效。此外,在预测长关键字单位时,比cnn-trad-fpool3在干净数据有6%的相对改善,但在噪声方面具有与cnn-trad-fpool3相似的性能。 此外,cnn-tpool2在干净数据比DNN有44%的相对改善,在噪声方面有41%的相对改善。 据我们所知,这是第一次在没有子网络的情况下在时域池化,已经证明对语音任务有帮助。

引用:
[1] J. Schalkwyk, D. Beeferman, F. Beaufays, B. Byrne,
C. Chelba, M. Cohen, M. Kamvar, and B. Strope, ““Your
word is my command”: Google search by voice: A case
study,” in Advances in Speech Recognition, A. Neustein,
Ed. Springer US, 2010, pp. 61–90.
[2] G. Chen, C. Parada, and G. Heigold, “Small-footprint
Keyword Spotting using Deep Neural Networks,” in Proc.
ICASSP, 2014.
[3] Y. LeCun and Y. Bengio, “Convolutional Networks for
Images, Speech, and Time-series,” in The Handbook of
Brain Theory and Neural Networks. MIT Press, 1995.
[4] O. Abdel-Hamid, A. Mohamed, H. Jiang, and G. Penn,
“Applying Convolutional Neural Network Concepts to
Hybrid NN-HMM Model for Speech Recognition,” in
Proc. ICASSP, 2012.
[5] L. Toth, “Combining Time-and Frequency-Domain Convolution in Convolutional Neural Network-Based Phone
Recognition,” in Proc. ICASSP, 2014.
[6] T. N. Sainath, A. Mohamed, B. Kingsbury, and B. Ramabhadran, “Deep Convolutional Neural Networks for
LVCSR,” in Proc. ICASSP, 2013.
[7] Y. LeCun, F. Huang, and L. Bottou, “Learning Methods
for Generic Object Recognition with Invariance to Pose
and Lighting,” in Proc. CVPR, 2004.
[8] T. Sainath, B. Kingsbury, G. Saon, H. Soltau, A. Mohamed, G. Saon, and B. Ramabhadran, “Deep Convolutional Networks for Large-Scale Speech Tasks,” Elsevier
Special Issue in Deep Learning, 2014.
[9] K. Vesely, M. Karafiat, and F. Grezel, “Convolutive Bottleneck Network Features for LVCSR,” in Proc. ASRU,
2011.
[10] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. Le,
M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and
A. Ng, “Large Scale Distributed Deep Networks,” in Proc.
NIPS, 2012.
[11] T. N. Sainath, O. Vinyals, A. Senior, and H. Sak, “Convolutional, Long Short-Term Memory, Fully Connected
Deep Neural Networks,” in to appear in Proc. ICASSP,
2015.















 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









