







 如果我们允许序列的点与另一序列的多个连续的点相对应(即,将这个点所代表的音调的发音时间延长),然后再计算对应点之间的距离之和,这就是dtw算法。在采用传统欧式距离,即点对点的方式计算发音序列距离时,距离之和如下: 欧式距离 = |A(1)-B(1)| + |A(2)-B(2)| + |A(3)-B(3)| + |A(4)-B(4)| + |A(5)-B(5)| + |A(6)-B(6)| =6_x0001_差分距离法是计算原始时间序列的一阶微分,然后度量两个时间序列的微分序列的距离,即微分距离。
如果我们允许序列的点与另一序列的多个连续的点相对应(即,将这个点所代表的音调的发音时间延长),然后再计算对应点之间的距离之和,这就是dtw算法。在采用传统欧式距离,即点对点的方式计算发音序列距离时,距离之和如下: 欧式距离 = |A(1)-B(1)| + |A(2)-B(2)| + |A(3)-B(3)| + |A(4)-B(4)| + |A(5)-B(5)| + |A(6)-B(6)| =6_x0001_差分距离法是计算原始时间序列的一阶微分,然后度量两个时间序列的微分序列的距离,即微分距离。
背景
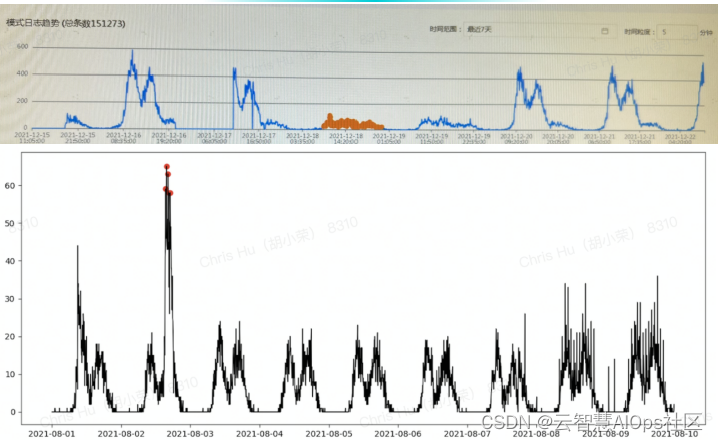
目前,日志异常检测算法采用基于时间序列的方法检测异常,具体为:日志结构化->日志模式识别->时间序列转换->异常检测。异常检测算法根据日志指标时序数据的周期性检测出历史新增、时段新增、时段突增、时段突降等多种异常。
然而,在实际中,日志指标时序数据并不都具有周期性,或具有其他分布特征,因此仅根据周期性进行异常检测会导致误报率高、准确率低等问题。因此如果在日志异常检测之前,首先对日志指标时序数据进行分类,不同类型数据采用不同方法检测异常,可以有效提高准确率,并降低误报率。
日志指标序列的类型
日志指标序列分为时序数据与日志指标数据两大类:
- 时序数据: 包含平稳型、周期型、趋势型、阶跃型。
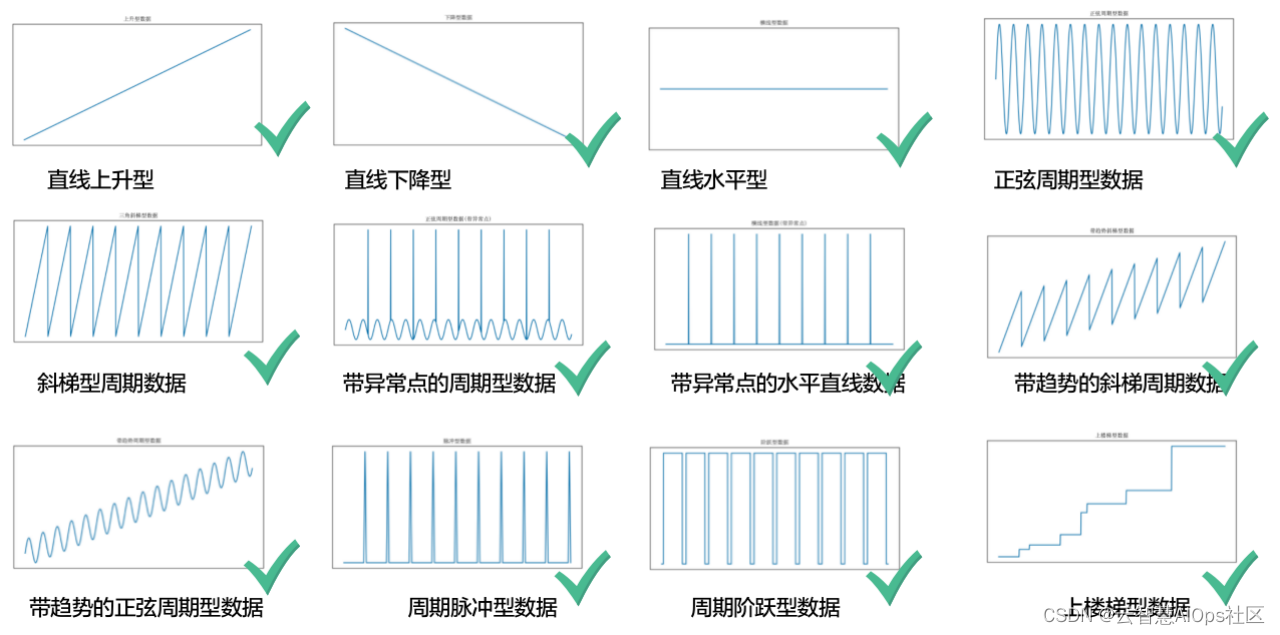
- 日志指标数据: 包含周期型、非周期型。
时间序列分类算法
时间序列分类是一项在多个领域均有应用的通用任务,目标是利用标记好的训练数据,确定一个时间序列属于预先定义的哪一个类别。 时间序列分类不同于常规分类问题,因为时序数据是具有顺序属性的序列。
时间序列分为传统时间序列分类算法与基于深度学习的时间序列分类算法。传统方法又根据算法采用的用于分类的特征类型不同,分为全局特征、局部特征、基于模型以及组合方法4大类。基于深度学习的时间序列算法分为生成式模型与判别式模型两大类。本文主要对传统时间序列分类算法进行介绍。

传统时间序列分类算法
基于全局特征的分类算法
全局特征分类是将完整时间序列作为特征,计算时间序列间的相似性来进行分类。分类方法有通过计算不同序列之间距离的远近来表达时间序列的相似性以及不同距离度量方法 + 1-NN(1-近邻)。主要研究序列相似性的度量方法。
- 时间域距离
问题场景描述:
如下图所示,问题场景是一个语音识别任务。该任务用数字表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









