http协议详解
1、HTTP协议:超文本传输协议
是一种分布式、合作式、多媒体信息系统服务,面向应用层的协议。是一种通用的,不分状态的协议。是一种请求/应答协议。
1.1、HTTP/1.0和HTTP/1.1的比较
RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1 。HTTP1.0 与HTTP1.1 向后兼容,也就是说运行1.1版本的浏览器可以和1.0 版本的服务器进行“对话”。
1.2 Host域
HTTP1.1在Request消息头里头多了一个Host域, HTTP1.0则没有这个域。
eg:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
可能HTTP1.0的时候认为,建立TCP连接的时候已经指定了IP地址,这个IP地址上只有一个host。
1.3日期时间戳
(接收方向)
无论是HTTP1.0还是HTTP1.1,都要能解析下面三种date/time stamp:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, updated by RFC 1123
Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsoleted by RFC 1036
Sun Nov 6 08:49:37 1994 ; ANSI C's asctime() format
(发送方向)
HTTP1.0要求不能生成第三种asctime格式的date/time stamp;
1.4状态响应码
状态响应码100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
客户端在Request头部中包含
Expect: 100-continue
Server看到之后如果回100 (Continue) 这个状态代码,客户端就继续发request body。这个是HTTP1.1才有的。
另外在HTTP/1.1中还增加了101、203、205等等性状态响应码
1.5请求方式
HTTP1.1增加了OPTIONS, PUT, DELETE, TRACE, CONNECT这些Request方法.
Method = "OPTIONS" ; Section 9.2
| "GET" ; Section 9.3
| "HEAD" ; Section 9.4
| "POST" ; Section 9.5
| "PUT" ; Section 9.6
| "DELETE" ; Section 9.7
| "TRACE" ; Section 9.8
| "CONNECT" ; Section 9.9
| extension-method
extension-method = token
2、HTTP协议的重要概念
1、连接(connection):一个传输层的实际环流,它建立在两个相互通信的应用程序之间。
2、消息(message):HTTP协议通信的基本单位,它包括一个结构化的八元族序列并通过连接传输。
3、请求(request):一个从客户端到服务器的请求信息,它包括应用于资源的方法、资源的标识符和协议的版本号。
4、响应(response):一个从服务器返回的信息,包括HTTP协议的版本号、请求的状态和文档的MIME(多用途互联网邮件扩展)类型。
5、资源(resource):由URI(统一资源标识符,URL就是URI的一种)标识的网络数据对象或服务。
6、实体(Entity):数据资源或来自服务资源的回应的一种特殊表示方法,他可能被包围在一个请求或响应信息中。一个实体包括实体头信息和实体的本身内容。
7、客户机(client):一个为发送请求的目的而建立连接的应用程序。
8、用户代理(User agent):初始化一个请求的客户机。他们是浏览器、编辑器或其它用户工具。
9、服务器版(server):一个接受连接并对请求返回信息的应用程序。
10、源服务器(origin server):是一个给定资源可以在其上驻留或被创建的服务器。
11、代理(proxy):一个中间程序,它可以充当一个服务器,也可以充当一个客户机,为其它客户机建立请求。
12、网关(gateway):一个作为其他服务器中间媒介的服务器。与代理不同的是,网关对被请求的资源来说他就是源服务器;发送请求的客户机并没有意识到他在同网管打交道。网关通常作为通过防火墙的服务器的门户,网关还可以作为一个协议翻译器以便于存取哪些存储在非HTTP系统的资源。
13、通道(tunnel):是作为两个连接中继的中介程序。一旦激活,通道便被认为不属于HTTP通信,尽管通道可能是被一个HTTP请求初始化的。当被中继的连接两端关闭时,通道便消失。
14、缓存(Cache):信息的局域存储。
3、协议特点
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
4、在协议栈上的位置
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:
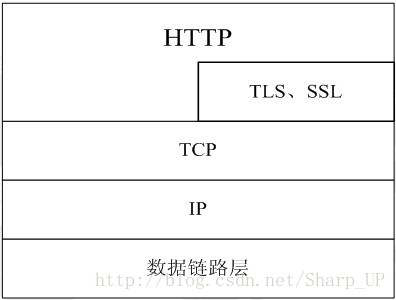
HTTP通信通常发生在TCP/IP连接上,HTTP仅仅期望可靠传输:任何提供这种保证的协议都可以使用,默认HTTP的端口号为80,HTTPS的端口号为443。
5、HTTP工作流程
HTTP协议是一种请求/应答协议。与主机建立连接之后,客户机以请求方法,URI和协议版本的形式向服务器发送请求,其中包括请求修改、客户信息和可能的正文内容。
在HTTP中,客户端总是通过一个连接与发送一个HTTP请求来发起一个事务。服务器不能主动和客户机联系,也不能给客户机发送一个回叫连接。客户端和服务器都可以提前中断。eg:当浏览器下载一个文件时,用户可以取消下载,关闭与HTTP的连接。
一次HTTP操作称为一个事务,其工作过程可分为四步








 本文详细解析了HTTP协议,包括HTTP/1.0与HTTP/1.1的对比、Host域、状态响应码和请求方式等。同时探讨了HTTP的工作流程、消息报头、特点以及在协议栈的位置。此外,还着重阐述了HTTP与HTTPS协议的主要区别,帮助理解它们在安全性和应用层面的差异。
本文详细解析了HTTP协议,包括HTTP/1.0与HTTP/1.1的对比、Host域、状态响应码和请求方式等。同时探讨了HTTP的工作流程、消息报头、特点以及在协议栈的位置。此外,还着重阐述了HTTP与HTTPS协议的主要区别,帮助理解它们在安全性和应用层面的差异。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









