







在上一篇中, 探讨了文件名编码以及非文本文件中的文本内容的编码, 在这里, 将介绍更为重要的文本文件的编码.
混乱的现状
设想一下, 如果在保存文本文件时, 也同时把所使用的编码的信息也保存在文件内容里, 那么, 在再次读取时, 确定所使用的编码就容易多了.
很多的非文本文件比如图片文件通常会在文件的头部加上所谓的 “magic number(魔法数字)” 来作为一种标识.
所谓的"magic number", 其实它就是一个或几个固定的字节构成的固定值, 用于标识文件的种类(类似于签名).
比如 bmp 文件通常会以 “42 4D” 两字节开头.
又比如 Java 的 class 文件, 则是以四字节的 “ca fe ba be” 打头. (咖啡宝贝? )
即便没有文件后缀名, 根据这些信息也是确定一个文件类型的手段.
附: 关于用 Notepad++ 查看十六进制的问题, 这是一个插件, 如果没有装, 菜单–插件–plugin manager–available–HEX-Editor, 装上它.
装上后, 它通常在工具栏的最右边, 一个黑色的大写的斜体的"H"就是它. 单击它可以在正常文本与 16 进制间切换. 要进一步查看二进制, 在文本区, 右键–view in–to binary.
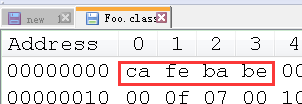
没有编码信息
那么, 对于文本文件, 有没有这样的好事呢? 可以简单建立一个文本文件 “foo.txt”, 里面输入两个简单的字符, 比如 “hi”, 保存, 然后再查看文件的大小属性:
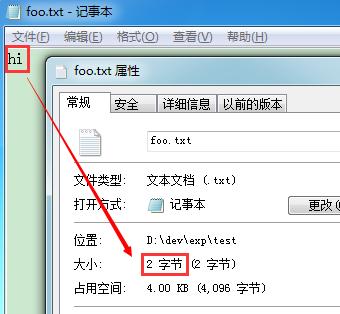
然后, 我们很遗憾地发现, 大小只有 2, 也即 “hi” 两个字符的大小, 这意味着没有保存额外的所用编码的信息.
用十六进制形式查看, 也可以发现这两个字节就是 hi 两字符的编码:
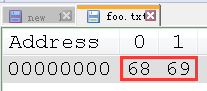
关于字母的 ASCII 编码, 可查看 字符集与编码(八)–ASCII和ISO-8859-1.
那么, 现在很清楚了, 文本文件仅仅是内容的字节序列, 没有其它额外的信息.
BOM?
当然, 说绝对没有额外信息也不完全正确, 在之前的关于 BOM 的介绍中, 我们看到 BOM 其实可以看成是一种额外的信息.
保持内容不变, 简单地"另存为"一下, 在编码一栏选择 “UTF-8”, 再次查看属性将会发现大小变成了 5 :
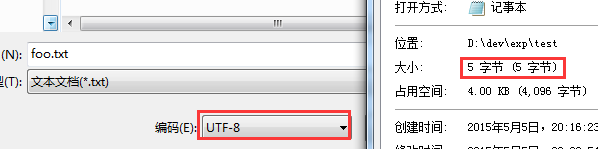
再次查看十六进制形式时, 就会发现除了原来的 “68 69” 外, 还多出了 UTF-8 的 BOM: “ef bb bf”
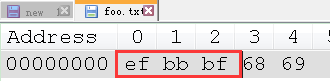
也正是以上三个与内容无关的字节使得大小变成了 5. 这个信息是与所用编码有关的, 不过它仅能确定与 Unicode 相关的编码.
严格地说, BOM 的目的是用于确定字节序的.
另一方面, 对于 UTF-8 而言, 现在通常不建议使用 BOM, 因为 UTF-8 的字节序是固定的, 所以很多的 UTF-8 编码的文本文件其实是没有 BOM 的, 不能简单地认为没有 BOM 就不是 UTF-8 了.
比如 eclipse 中生成的 UTF-8 文件默认就是不带 BOM 的. 微软的笔记本应该是比较特殊的情况.
综上所述, 文本文件通常没有一个特殊的头部信息来供确定所用的编码, 另一方面, 编码的种类又是五花八门, 那么如何去确定编码呢?
确定编码的步骤
不妨就以记事本为考察对象, 去探究一下它是如何确定编码的.
利用 BOM
前面说了, BOM 作为一种额外的信息, 间接地表明了所使用的编码. 尽管它原本的意图是要指明字节序, 但曲线救国一下也未必不可. 况且记事本还主动地为 UTF-8 也写入了 BOM, 不加以利用这一信息自然是不明智的.
注: 对 UTF-16 来说, BOM 是必须的, 因为它是存在字节序的, 弄反了字节序一个编码就会变成另一个编码了, 那就彻底乱套了. 不过一般很少用 UTF-16 编码来保存文件的, 更多是在内存中使用它作为一种统一的编码.
但对于 UTF-8, 很多时候也是没有 BOM 的, 记事本遇到 UTF-8 without BOM 时又该怎么办呢?
我猜, 我猜, 我猜猜猜
如果内容中没有编码信息, 又要去确定它使用的编码, 这不是为难人是什么? 好在"坑蒙拐骗"中的第二招"蒙"可以拿来用用.
"蒙"其实也是要讲点技术含量的, 简单点自然就是模式匹配了, 或许一个或几个正则式就完了;复杂点, 什么概率论, 统计学, 大数据统统给它弄上去, 那逼格立马就高了有木有? 当然了, 记事本也就是一跑龙套的…
记事本跟"联通"有仇?
在编码界有这么一个传说: 记事本跟"联通"有仇. 这是怎么一回事呢? 新建一个文本文件 “test.txt”, 录入两个汉字"联通", 保存, 关闭程序然后再次打开这一文件:
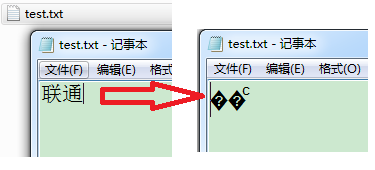
咦, 这是什么鬼? 咱们的"联通"呢?
深入分析
这其实就是竞猜失败的结果了, 准确地讲, 记事本把编码给猜成了 UTF-8.
为什么说是猜成 UTF-8 造成的呢? 我也没见过源码!接下来会根据出现的现象, 已有的证据来作出我们的推论, 然后还会做些实验去验证. (没错, 这就是科学!)
首先是这样一个事实: 当我们保存时, 使用的是缺省编码, 也就是 GBK. "联通"两字的 GBK 编码如下:
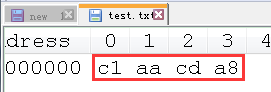
然后, 是这样一个现象: 再次打开时, 记事本突然就翻脸不认人了, 显示出了一些奇怪的字符.
严格地讲, 有三个字符, 两个问号及一个 C 一样的字符, 后面会分析为何会这样.
以上字节咋一看也没啥子特别的, 领头字节也没有恰好等于 UTF-16 或 UTF-8 的 BOM, 绝对标准的 GBK 模式, 为啥记事本对它另眼相看了呢?
关于 GBK 等编码, 可参见 字符集与编码(九)–GB2312, GBK, GB18030
那么, 一个合理的猜测就是记事本可能把它当成了无 BOM 的 UTF-8 编码. 而对于 UTF-8 编码来说, 它的编码模式还是很有自己特色的, 那么我们换成二进制形式查看以上编码:

看到以上编码, 相信对 UTF-8 编码模式有一些了解的都知道是怎么回事了, 我也用颜色的下标标注了关键的部分.
在前面的篇章中, 也曾经几次说到过 UTF-8 的编码模式:
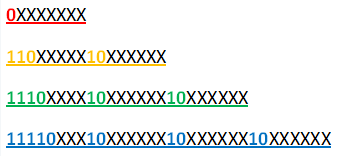
对比一下, 不难发现上述两个编码完全符合二字节模式!也难怪记事本犯迷糊了.
自然, 要做出一些"科学"的发现, 你还是需要一定的基础的. 所以在这里也给出了很多前面文章的链接.
显示疑云
那么, 为何又显示成了那样的效果呢? 既然推断它是 UTF-8 编码, 让我们人肉解码一下:
前两字节构成一组: 11000001 10101010 有效的码位有三段: 11000001 10101010 重组成码点之后是: 00000000 01101010
以上码点写成 16 进制是 U+006A, 这明明是一个一字节的码点! 对应的字母其实是小写字母 j.
所以, 这里其实是有错误的. 这个码点不应该用二字节来编码.
如果你读过前面关于 Unicode 的篇章, 就会明白, 对于 UTF-8 编码而言, 码点在 U+0000~U+007F(0-127)间的用一字节模式编码. 码点在 U+0080~U+07FF(128-2047)间的才用二字节模式编码.
别问为什么! 这叫乌龟的屁股–龟腚(规定).
理论上讲, 二字节的空间是完全可以囊括一字节编码的那些码点的, 各种模式间其实是有重叠与冗余的. 但如果一个码点适用于更少字节, 那么它应该优先用更少字节的编码模式.
所以, 通常说 UTF-8 的二字节模式是"110x xxxx, 10xx xxxx", 但并非所有满足这些模式的编码都是合法的 UTF-8 二字节编码. 这里面其实是有个坑的.
二字节首个码点为 U+0080, 对应二字节模式首字节为"1100 0010", 那么, 所有合法的二字节模式首字节不应该小于此值.
显然, 亲爱的微软的写记事本的程序员们, 你们偷懒了!你们至少应该可以避免与"联通"结仇.
那么, 虽然能够解出相应的码点, 但其实是非法的组合, 这也就是结果显示出"�"的原因. 这通常是一个明显的解释失败的标志.
注: "�"本身是一个合法的 Unicode 字符, 码点为 U+FFFD, 对应的 UTF-8 编码为: EF BF BD. 如果字体不支持的话, 可参见 http://www.fileformat.info/info/unicode/char/fffd/index.htm
这可不是"显示不出来"造成的, 它本身就长这样. 这个码点的含义为 “replacement character”(替换字符). 当碰到非法的字节时, 显示系统就用它来替换, 然后显示这个替换字符来表示发生了替换. 所以, 那些真正"显示不出来"的东西已经被替换了. (如果文件中本身就包含这个字符的话, 替换上去的和原有的实际是无法区分的. )

在这里, 程序实际临时在内存中做了替换, 如果你对它进行拷贝, 得到的也将是它的值, 而不是原来的值.
所以, 显示层面出现了问号(包括早期的 ASCII 中那个问号"?", U+001A, 也常用作替换字符), 不代表它不清楚如何显示, 而完全是因为最终交给它去渲染的就是"问号"字符. (可能是替换上去的, 也可能本身就有的. )
在显示层面, 原来的值实际已经丢失了.
至于为何显示了两个问号, 大概是把两个字节当作了两次失败. 个人认为显示一个问号也能说得通.
再来看第二组
后两字节构成一组: 11001101 10101000 有效的码位有三段: 11001101 10101000 重组成码点之后是: 00000011 01101000
以上码点写成 16 进制是 U+0368, 对应的字母其实是所谓的 COMBINING LATIN SMALL LETTER Cͨ(<–这里右上角的第二个 C 就是 U+0368). 见 http://www.fileformat.info/info/unicode/char/0368/index.htm
显示时, 它会紧贴在前面的字母上, 这是 Unicode 中个人感觉比较奇葩的一些内容, 如果你有兴趣, 这是 wiki 的一些介绍 http://en.wikipedia.org/wiki/Combining_character 前面乱码的截图中, 那个怪怪的 C 就是这样来的, 感觉好像与前面一个问号是一体的一样.
"联通"这一案例还真多梗.
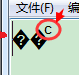
至此, 冤有头, 债有主, 一切都水落石出. 最终我们的猜测被证实.
直接证据!
其实, 在变成怪怪的字符后, 如果我们点击"另存为", 在弹出的对话框中会发现编码成了"UTF-8"
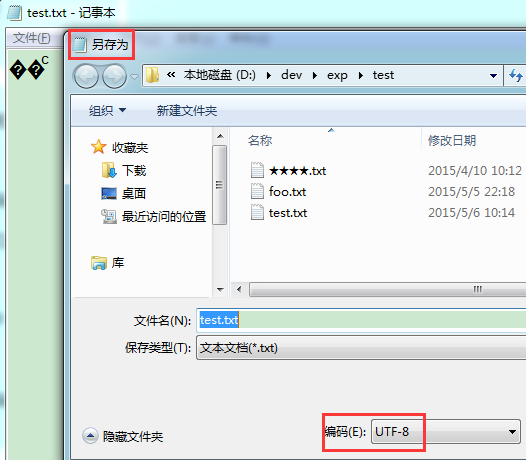
这是赤裸裸的证据, 直接表明了记事本把编码误判成了 UTF-8! 简直是铁证如山呀!
打破模式
删掉 test.txt, 从新再建立, 这次把联通的好基友"电信"也一起录入, 录入"联通电信"四个字, 保存并再次打开时记事本就不再抽疯了, 因为"电信"两字的 GBK 编码模式与 UTF-8 不能匹配了, 读者可自行验证一下, 这里就不再贴图展示了.
注: 不要直接删除原来的乱码字符并重新录入, 前面"另存为"已经表明它已经成了 UTF-8 编码, 直接在原文件修改将导致以 UTF-8 编码保存. 所以应该删除原文件.
有句话叫"无巧不成书", 记事本跟"联通"有仇, 这其实就是一个因为样本太少而误判的典型例子.
缺省编码, ANSI 是个什么玩意
如果既没有 BOM, 又无法猜测出所使用的编码, 那是否就只能是两眼一抹黑了呢?
还好, 计算机世界还有件贴心的小棉袄叫"缺省".
其实, 当你保存任何一个文本文件时, 指定一个编码是必不可少的一个步骤.
与此类似, 读取一个文本文件时, 或者说是比如 Java 中 new 一个
Reader字符流时, 又或者是string.getBytes时, 你其实都是需要指定一个编码的.
但很多时候, 我们并没有感觉到需要这一步骤, 原因就是"缺省"在为我们默默地服务.
缺省这玩意, 怎么说它好呢? 当它正常时, 你好, 我好, 大家好. 当它不正常时, 你甚至不知道哪儿出错了. 你过于依赖它, 它很可能成为你的定时炸弹. 不得不说, 很多时候我们其实是抱着炸弹在击鼓传花, 还玩得不亦乐乎, 直到"轰"的一声, 咦? 头上什么时候多了个圈?
以记事本为例, 当我们新建一个文件并保存时, 其实是有个选项的, 通常, 这里会缺省地选上"ANSI"
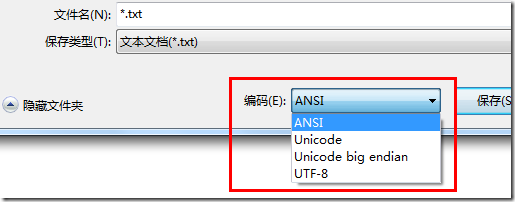
那么这里的 ANSI 又是个什么鬼呢?
ANSI(American National Standards Institute 美国国家标准学会)与它字面的意思并不相符, 它也不是一种真正意义上的编码.
通常把它理解成平台缺省编码, 它具体指代什么则通常与平台所在地区的 Windows 发行版本有关.
像我们这些火墙内的大陆人民, 多数人用的 Windows 版本, ANSI 指的是 GBK;
在香港台湾地区, 它可能是 Big5;
在一些欧洲地区, 它则可能是 ISO-8859-1.
除了 ANSI 之外, 在这里还有其它的选项. 其实在这里短短的一个下拉列表, 处处都是坑呀, 说多了都是泪.
- ANSI, 前面已说, 就不说了.
- Unicode. 其实是 UTF-16, 具体地讲是 UTF-16 little endian(UTF-16 LE).
这个缺省为 Little Endian 也仅是微软平台的缺省. 其它平台未必是如此.
- Unicode big endian. 与之前类似, 就是 UTF-16 big endian(UTF-16 BE).
Unicode 现在的含义太宽泛, 可以指Unicode 字符集, 可以指 Unicode 码点, 也可以指整个 Unicode 标准.
现在看来, 把 UTF-16 继续叫成 Unicode 实在是很坑爹, 除了容易引发误解, 我还真没想到它还能有什么其它好处~
- UTF-8.
其实是"带 BOM 的 UTF-8", 而真正推荐的缺省做法是"不带 BOM". 微软就是任性!
还需要注意的是, 不同的操作系统对于缺省有不同的策略.
比如现在很多的 Linux 的操作系统都把 UTF-8 当成了缺省的编码, 无论你在什么地区都是如此. 这对于减少混乱还是有帮助的.
因为文件内容没有编码的信息, 各个系统平台对于缺省的规定又各不相同, 种种情况导致了乱码问题层出不穷, 下一篇, 将探讨引入编码信息的一些实践.














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









