







实验工具
notepad++编辑器
实验过程
步骤1:打开notepad++,新建一个文本文件,在其中输入一段汉字文本,查看当前编码格式,如下:
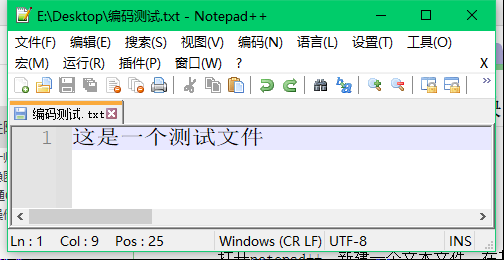
分析:由上图可见,从右下角可知当前文件是以UTF-8解码显示的,显示内容没有乱码,说明文件的编码格式与解码显示格式一致,均为UTF-8。
步骤2:通过“编码”菜单栏将解码显示格式改为ANSI,结果文件内容变成了乱码
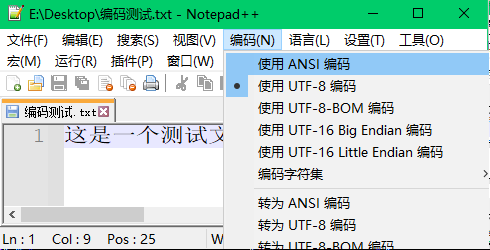
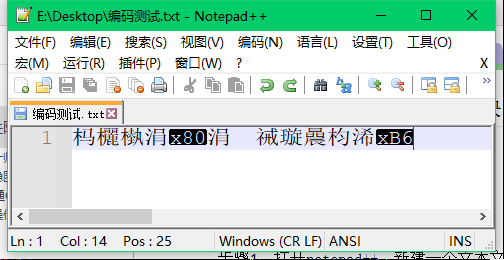
分析:文件编码格式为UTF-8,但解码显示格式为ANSI,因此文本显示为乱码。此时,虽然文本是按UTF-8编码的,但编辑器对其是按照ANSI进行解码的,也就是不管文本是否显示为乱码,编辑器当前认为文件是按ANSI进行编码的,所以对其按ANSI进行了解码显示。
步骤3:将编码格式转换为ANSI,结果没有变化
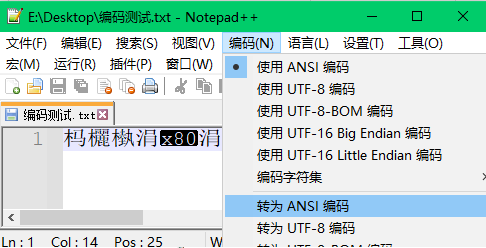
分析:因为编辑器当前是按照ANSI编码格式进行解码的,及编辑器默认文件的编码格式为ANSI,此时将文件编码转换为ANSI,意味编码格式从ANSI转换到ANSI,相当于没有转换,自然不会有任何变化(可以通过将解码格式改成UTF-8来验证文件的编码格式是否仍然为UTF-8)。
步骤4:将编码格式转换为UTF-8,结果文本变成了另外一种乱码,并且选项卡图标变成了红色,
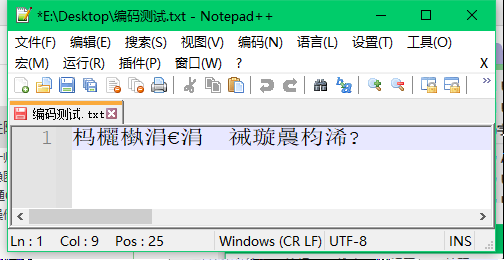
分析:选项卡图标变为红色,说明文件被修改了,说明转换过程经过了字节数据上的改变。而文本变成另外一种乱码,是因为编辑器把原来的乱码当成了文本正确显示的样子对其进行了从ANSI到UTF-8编码的转换,得到的乱码是原来的乱码经过转码后在UTF-8编码格式下解码的结果。此时,要想将乱码恢复到原来正确的文字,需要按照相反的顺序进行转码,即先UTF-8转ANSI,然后按UTF-8解码,如步骤5。而如果在此基础上使用ANSI标准进行解码显示,文本又会变成一种新的乱码,如步骤6。
步骤5:先进行UTF-8到ANSI的编码转换,发现经过一次转换再转换回来的乱码发生了变化,原来的法郎符号变成了十六进制数x80。再将解码标准换成UTF-8,结果显示只有部分文本恢复到了正确的样子。
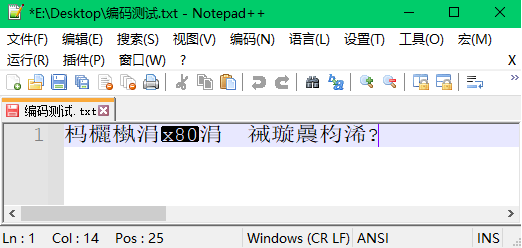
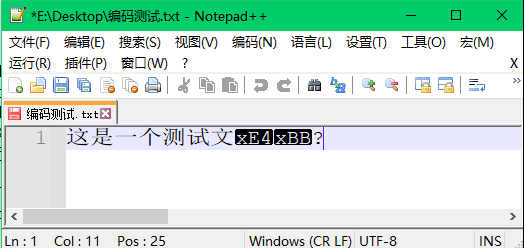
分析:这个结果说明,在不知道文件编码标准的情况下出现乱码,然后盲目地对文件地编码进行转换,这样很可能会对原来的文件造成损坏,即使最后知道了文件的真实编码标准,也很可能难以恢复完全
步骤6:在步骤4的基础上,把解码标准改为ANSI,结果乱码又变成了一种新的乱码。
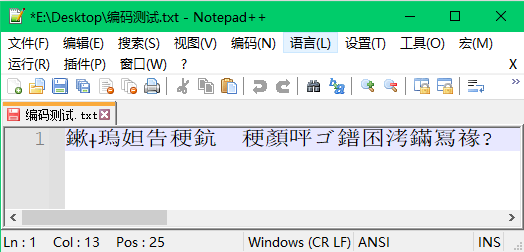
分析:这是因为用ANSI标准对按照UTF-8进行编码的乱码进行了解码,第二种乱码是相对第三种乱码的正确文字,而第一种乱码又是相对第二种乱码的正确文字,而真正的正确文字又是相对第一种乱码的正确文字,可以说原来的文字经过了反复三次的误解码后得到的最终的乱码。??似乎可以用这种方式对一些文本进行加密??答案当然是不可以,从步骤5中得到的结果就可以知道,这样会导致所需要加密的信息的丢失。
实验结论
在不知道文件编码标准的情况下出现乱码,然后盲目地对文件地编码进行转换,这样很可能会对原来的文件造成损坏,即使最后知道了文件的真实编码标准,也很可能难以恢复完全。
不能通过反复误编码的方式来进行文本加密,这样会导致员文本信息的损坏。

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









