







前言
mysql 主从复制使用感受,遇到一些问题的整理,也总结了一些排查问题技巧。
环境
mysql5.7
配置
附:千万级数据快速插入配置可以参考:mysql千万数据快速插入-实战
主库
主要配置
server_id=16523
log_bin=/laday/mysql/logbin/log_bin
# 这里为啥使用 STATEMENT 后面细讲
binlog_format=STATEMENT
# 日志过期时间天数
expire_logs_days=7
log-error=/laday/mysql/log/err.log
# 是否开启慢查询日志收集, 1为启用, 0为禁用
slow_query_log=1
# 慢查询日志文件
slow_query_log_file=/laday/mysql/log/slow.log
# 记录慢查询超时时间, 秒
long_query_time=20
tmpdir=/laday/mysql_tmpdir
# 开启 gtid, 自动寻找同步点
gtid_mode=ON
enforce_gtid_consistency=ON
# 数据库同步白名单(库级)
binlog-do-db=laday
# 数据库同步黑名单
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
从库
主要配置
# mysql 启动时是否忽略启动slave, ON=mysql 启动后slave不会自动启动,需要手动启动。
skip_slave_start=ON
# 忽略同步过程出现所有错误,根据实际情况制定
slave-skip-errors=all
# 开启 gtid
gtid_mode=ON
enforce_gtid_consistency=ON
# 同步表白名单 (表级)
replicate_wild_do_table=laday.table_1%
replicate_wild_do_table=laday.table_2%
# 同步表黑名单
replicate_wild_ignore_table=laday.%
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=performance_schema.%
replicate_wild_ignore_table=sys.%
STATEMENT
binlog_format=STATEMENT
最开始是使用 ROW 的,但是后面发现从库同步任务一直卡,发现是主库使用了 DELETE 语句删除一个千万级的大表,导致从库是一行一行删除,也就卡si了。
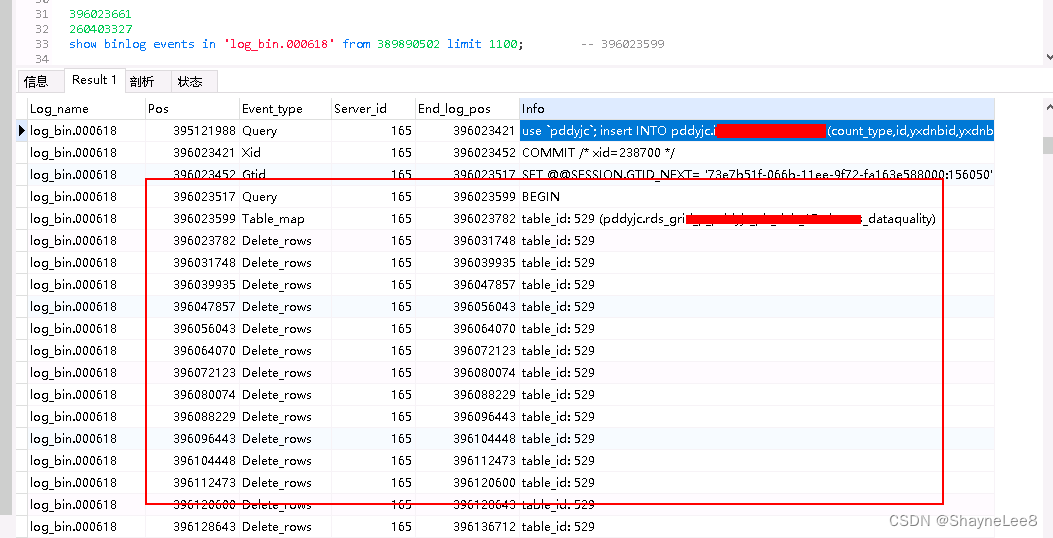
后面换成:MIXED
还随手测试了一下 delete from 【表名】 看着正常。后面还是卡了, 原来主库有一个语句 delete from 【表名】 where … sysdate() … 删除大表,导致从库又卡了。罪魁祸首->sysdate
最终我决定使用: STATEMENT
binlog
有时候主从复制会有延迟的情况,可以通过 show slave status 查看此刻进度,包括 pos 和 file。
show slave status

然后带入 pos 和 file 在主库执行如下语句:
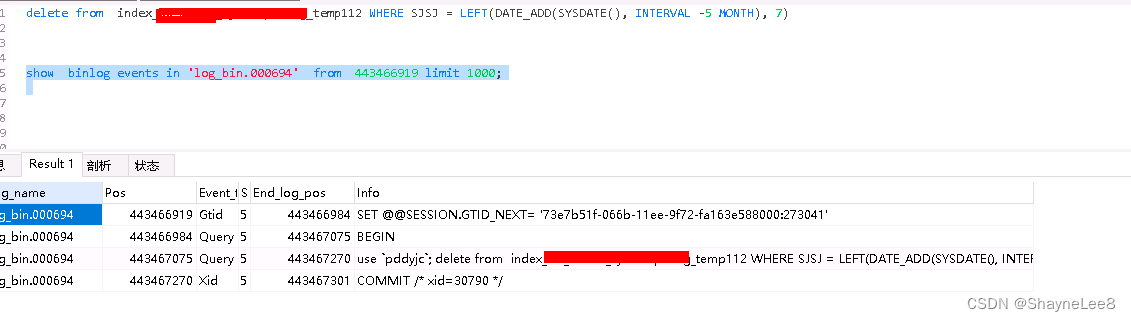
使用SQL查询看不出执行时间,可以使用 mysqlbinlog(在mysql 安装目录里面) 命令:
./bin/mysqlbinlog --start-datetime='2023-11-02 20:00:00' --stop-datetime='2023-11-02 23:00:00' ./logbin/log_bin.000613 > /home/xyz/temp001.sql
./bin/mysqlbinlog --start-position=314712945 --stop-position=315156780 ./logbin/log_bin.000973 > /home/xyz/temp002.sql

gtid
开启 gtid,方便从库自动寻找续点。
初始化如下:
CHANGE MASTER TO MASTER_HOST='10.111.xxx.xxx',MASTER_PORT=3308,MASTER_USER='账号', MASTER_PASSWORD='密码',master_auto_position=1;
也可以手动定义同步点,如下:
CHANGE MASTER TO MASTER_HOST='10.111.xxx.xxx',MASTER_PORT=3308,MASTER_USER='账号', MASTER_PASSWORD='密码',master_auto_position=0,
master_log_file='log_bin.000694',master_log_pos=194;
log-error
对于很多问题,错误日志会有很多信息提示,不要错过。
DistSQL
DistSQL(Distributed SQL)是 Apache ShardingSphere 特有的操作语言,读写分离用到,在此顺便记录一下。
常用语句:
-- 查询存储单元信息
SHOW STORAGE UNITS;
-- 查询所有分片规则
SHOW SHARDING TABLE RULES FROM pddyjc;
-- 查询指定逻辑表的分片规则
SHOW SHARDING TABLE RULE 表 FROM 库;
-- 删除指定逻辑表的分片规则
DROP SHARDING TABLE RULE 表;
-- 查询指定数据库中具有广播规则的表
SHOW BROADCAST TABLE RULES FROM 库;
-- 删除指定数据库中具有广播规则的表
DROP BROADCAST TABLE RULE 表 FROM 库;
-- 将 test_br 添加到广播规则中
CREATE BROADCAST TABLE RULE test_br ;
-- 设置单表默认存储单元
SET DEFAULT single table storage unit = ds_0;
-- 创建规则(分库)
-- test_a 以 sjsj 字段分库。
-- allow-range-query-with-inline-sharding=true , 支持 between 等区间关键字跨库查询。
CREATE SHARDING TABLE RULE test_a(
DATANODES("ds_${0..1}.test_a"),
DATABASE_STRATEGY(TYPE="standard",SHARDING_COLUMN=sjsj,
SHARDING_ALGORITHM(TYPE(NAME="inline",PROPERTIES("algorithm-expression"="ds_${ sjsj >='2023-10'?0:1 }","allow-range-query-with-inline-sharding"="true"))))
);
-- 创建规则(分表)
-- testtable 以 zzbm 字段分表。
ALTER SHARDING TABLE RULE testtable(
DATANODES("ds_0.testtable_${['0501','0502','0503','0504','0505','0506','0507','0508','0509','0510','0511','0512','0513','0514','0515','0516','0522','0581']}"),
TABLE_STRATEGY(TYPE="standard",SHARDING_COLUMN=zzbm,
SHARDING_ALGORITHM(TYPE(NAME="inline",PROPERTIES("algorithm-expression"="iamskh_ydkh_${ zzbm }"))))
);
-- 同时有分库分表
-- 伪语法
-- 单字段
CREATE SHARDING TABLE RULE t_order_item (
DATANODES("ds_${0..1}.t_order_item_${0..1}"),
DATABASE_STRATEGY(TYPE="standard",SHARDING_COLUMN=user_id,
SHARDING_ALGORITHM(TYPE(NAME="inline",PROPERTIES("algorithm-expression"="ds_${user_id % 2}",
"allow-range-query-with-inline-sharding"="true" -- 注释: 如果分片字段需要用 < > between 等范围查询, 需要加这行
)))),
TABLE_STRATEGY(TYPE="standard",SHARDING_COLUMN=order_id,
SHARDING_ALGORITHM(TYPE(NAME="inline",PROPERTIES("algorithm-expression"="t_order_item_$
{order_id % 2}"))))
);
-- 多字段,复合分片
CREATE SHARDING TABLE RULE t_order_item (
DATANODES("ds_${0..1}.t_order_item_${0..1}"),
DATABASE_STRATEGY(TYPE="complex",SHARDING_COLUMNS=col1,col2,col3,
SHARDING_ALGORITHM(TYPE(NAME="complex_inline",PROPERTIES("algorithm-expression"="ds_${ col1 > 1 && col2 > 1 && col3 > 1 ? 0 : 1}"
)))),
TABLE_STRATEGY(TYPE="standard",SHARDING_COLUMN=order_id,
SHARDING_ALGORITHM(TYPE(NAME="inline",PROPERTIES("algorithm-expression"="t_order_item_$
{order_id % 2}"))))
);
-- 导出当前配置信息
EXPORT DATABASE CONFIGURATION;
总结
实践是检验真理的唯一标准
—————— 但行好事莫问前程,你若盛开蝴蝶自来















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









